
北京时间3月19日,英伟达发布代号为Blackwell的GPU芯片架构和显卡核心,基于该芯片打造了新一代的超级芯片GB200,还基于GB200打造了新一代AI计算节点。
这还没完,英伟达用AI计算节点配合第五代NVLink连接多块GB200超级芯片,构建了DGX机架。最后,还用8个DGX机架所包含的576块最强B200显卡构建了SuperPOD集群,AI算力高达11.5 Exaflops。

英伟达宣称,新的Blackwell芯片采用了最大的芯片物理尺寸,是接近光罩极限的大尺寸芯片(reticle limited die),所谓reticle limited die指的是尺寸达到或接近曝光极限的单个小芯片,这是光刻机单次曝光能够覆盖的晶圆面积的最大值。
它采用的是台积电的4nm工艺技术,单个die的晶体管数量达到了1040亿。然而,这只是一张显卡核心的一半。事实上,它由NV-HBI 10 TB/s的高速带宽接口连接了两个die,一块G200的整体晶体管数量为2080亿。

这块B200芯片的面积肉眼可见地大,Blackwell显卡核心的尺寸相较于上一代的H100芯片有大幅提升。毕竟两个大的die堆在一起,其晶体管数量加起来比Hopper多了1280亿。

这次B200采用了192GB的HBM3e显存,拥有8TB的内存带宽,提供20 PetaFlops的AI性能(FP4),10 PetaFlops的FP8性能。相较于上一代的H100,其训练性能提升4倍,推理性能提升30倍,能效更是提升了惊人的25倍。

与此同时,将两块B200显卡芯片与一块Arm Neoverse V2处理器放在一起,B200和Grace Arm核心通过900GB的NVLink-C2C连接,就构成了新一代的超级芯片GB200。这样一来,这块超级芯片的显存容量达到了384GB。

于是乎,这块GB200超级芯片,对外提供40 PetaFlops的AI性能,加上Arm CPU自带的内存,总体内存容量就达到了864GB。另外,它还有16TB/s的HBM内存带宽,以及总体3.6TB/s的NVLink带宽。

把2个GB200超级芯片组成一个Blackwell计算节点,算力达到80PetaFlops。肉眼看着应该是1U的空间,整体计算密度还是很高的,再加上这样一套平台的功耗想必也是惊人的,于是,英伟达打造的这套节点直接选择了水冷散热的方式。

这台Blackwell计算节点采用了新发布的专为AI场景优化的Connectx-800G Infiniband SuperNIC网卡,服务器的另一端还带有NVLink 交换机芯片。同时,节点中还使用了Bluefield-3 DPU,帮助服务器处理网络、存储、网络安全方面的需求。

将18台这样的Blackwell计算节点放到一个机架中,一个机架中就有了36块GB200超级芯片,显卡之间通过NVLink交换机连接,最终在DGX GB200 NVL72机架中就有了72块共享显存的B200显卡芯片。

机架的顶部还有一台Quantum Infiniband-800交换机,配合第五代NVLink技术,用8个这样的机架就组成了包含576块B200显卡芯片的SuperPOD AI算力集群。这样一个SuperPOD就可提供 11.5 Exaflops (576 x 20 PetaFlops)的 AI 计算性能。

在此之上,SuperPOD系统通过 NVIDIA Quantum InfiniBand 或者Spectrum以太网连接,最终可以在AI数据中心里扩展到32000个B200显卡,整个数据中心图提供645ExaFlops的AI算力,13PB的高速内存。
硬件配置提升巨大,参数规格带来逆天性能,这一代显卡的性能提升体现在哪里呢?
在推理方面,得益于第二代Transfomer技术。与相同数量的NVIDIA H100 GPU相比,GB200 NVL72可以为如GPT-MoE-1.8T这样的大型语言模型提供4倍的训练性能提升。
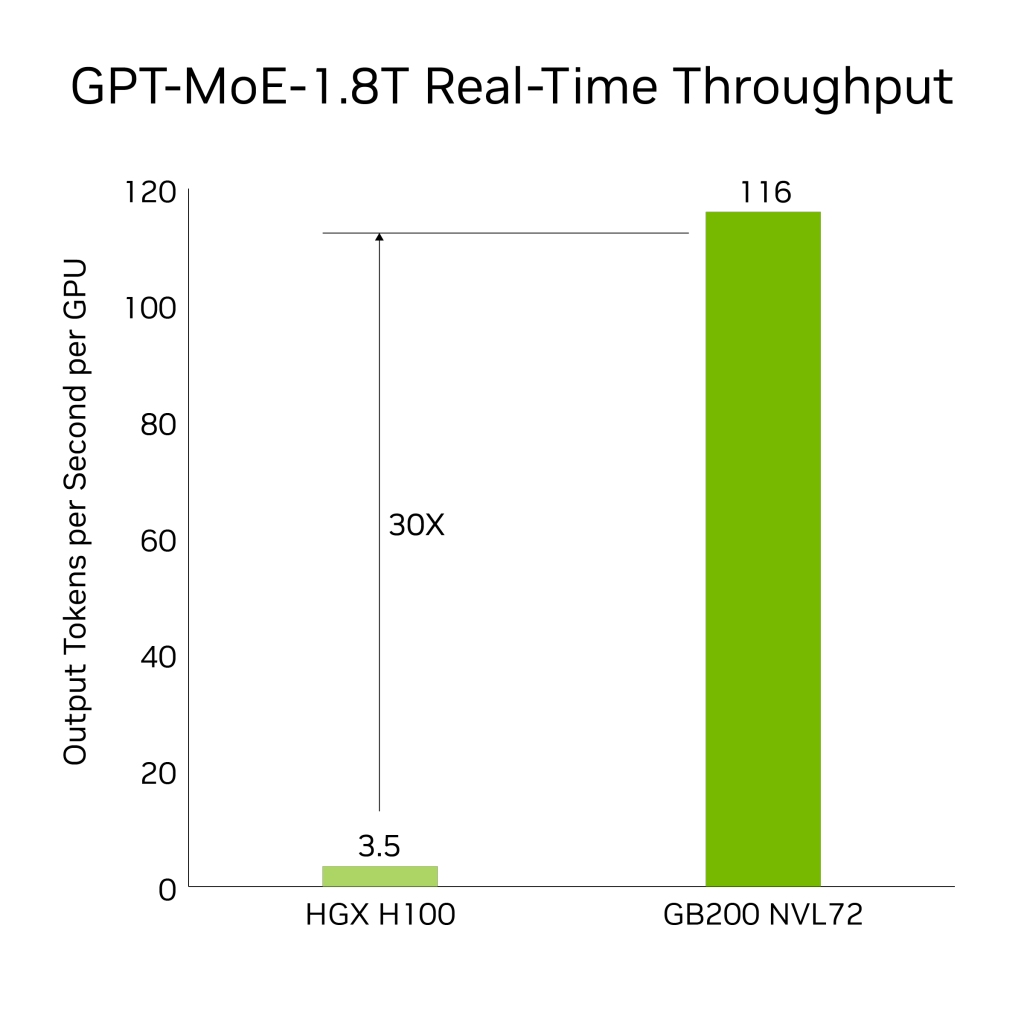
AI推理方面,GB200与上一代H100相比,对于资源密集型应用如1.8T参数的GPT-MoE,GB200可以提供30倍的速度提升。这一进步得益于新一代的张量核心。
企业会持续生成大规模数据,并依赖各种压缩技术来减轻瓶颈问题并节省存储成本。为了在GPU上高效处理这些数据集,Blackwell架构引入了一个硬件解压缩引擎,它能够在大规模上原生解压缩经过LZ4、Deflate和Snappy格式压缩的数据,从而加速整个分析流程。
该解压缩引擎加快了受内存限制的内核操作,提供高达800 GB/s的性能,并使得Grace Blackwell的查询基准测试比英特尔第四代至强快18倍,比NVIDIA H100 Tensor Core GPU快6倍。
有了高达8 TB/s的高内存带宽和Grace CPU高速NVlink-Chip-to-Chip(C2C)连接,这个引擎加快了数据库查询的整个过程。这导致在数据分析和数据科学的使用案例中都表现出顶尖的性能。这样一来,企业可以快速获得洞见的同时减少成本。

物理基础模拟在产品设计和开发中非常重要。物理模拟用于各种产品,如飞机、火车、桥梁、硅芯片甚至药物的测试和改进,通过模拟可以节省数十亿美元的成本。

ASIC的设计原本几乎完全依赖于CPU,在一个漫长且复杂的工作流程中完成,包括模拟分析以识别电压和电流。Cadence SpectreX模拟器就是其中一个例子。提供的图表显示,SpectreX在GB200上的运行速度比在x86 CPU上快13倍。
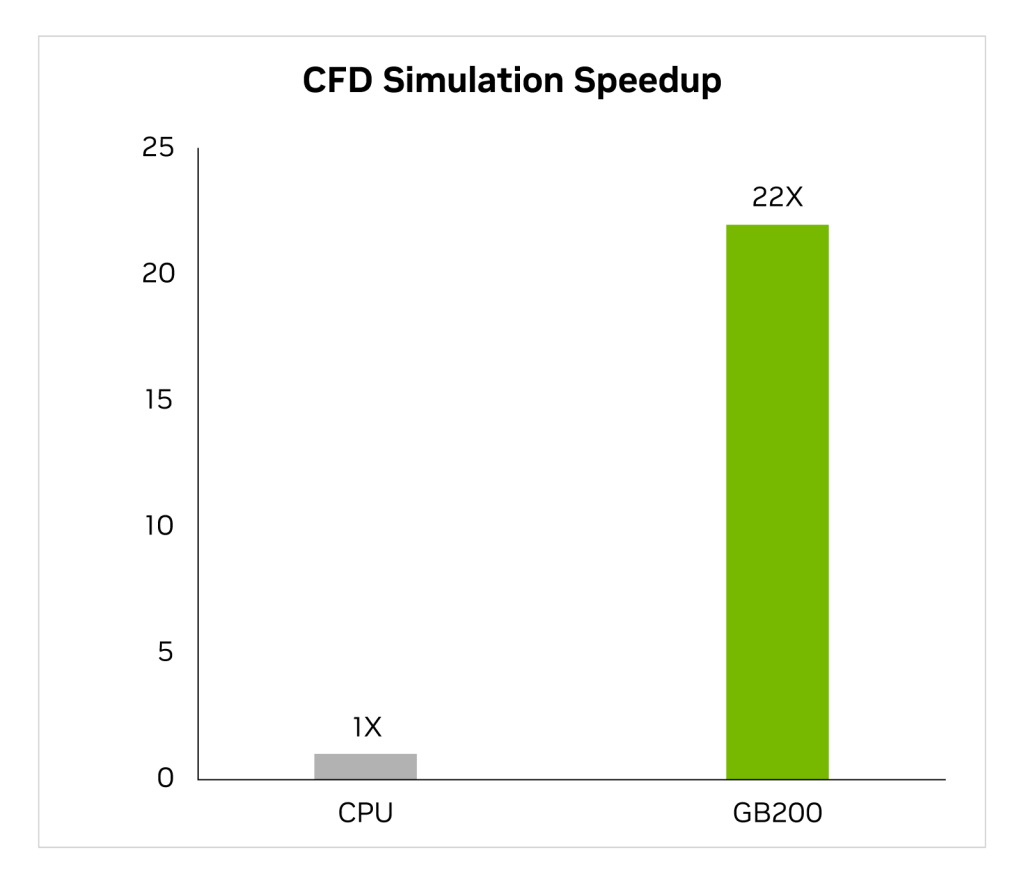
随着行业在过去两年越来越多地转向GPU加速的计算流体动力学(CFD)作为关键工具,工程师和设备设计者用它来研究和预测他们设计的行为。Cadence Fidelity,一个大涡流模拟器(LES),在GB200上进行的模拟比x86 CPU快达22倍。
一年一度的GTC大会备受瞩目,全球范围内关注AI技术的业内人士和技术爱好者都为之瞩目,来自中国的服务器厂商宁畅以赞助商身份来到了GTC舞台,展示了宁畅支柱型、全能型、旗舰型系列AI服务器及解决方案,支撑图形渲染、机器学习、AI推理、云计算等多元化应用场景需求。
对于国内的企业来说,既要关注英伟达推出的芯片和系统方案,也应该关注服务器厂商在人工智能产业中的价值。服务器厂商面向行业做的很多优化对于AI在行业的落地也至关重要,能尽可能帮助企业在生成式AI的创新竞赛中取得成功。







