
7月28-30日,以“闪耀数字经济新引擎”为主题的2022全球闪存峰会(Flash Memory World)在线上盛大召开。7月29日,PCIe、CXL新兴应用论坛上,唯亚威VIAVI中国区PCIe协议分析仪专家陆小虎发表了以“CXL协议分析”为题的主旨演讲,详解CXL协议技术。

CXL协议的功能与特性
CXL协议发展经历过1.0、1.1、2.0、3.0版本,如今市场上已经出现了基于CXL1.1和2.0的产品,3.0协议还在开发中。协议本身更是吸引了一众大型科技公司积极参与其中。今天来了解一下什么是CXL协议。
首先CXL协议主要用于CPU与Device(设备)之间的数据加速传输,具有低延迟、高速率的优点,其主要是用于人工智能和机器学习等应用场景的数据交互过程中。我们可以看到PCIe协议到5.0版本之后,像要求大量IO数据交互的AI应用就出现了性能瓶颈,因此引入了CXL协议概念突破瓶颈。
CXL协议能解决哪些问题?首先是共享内存的问题,支持PCIe协议的大量设备都有内存,但这些内存都没有被CPU进行统一编址,因此互相之间不能被调用导致延迟问题。CXL协议引入了共享内存概念,CPU可以对所有device上的内存进行统一编址,互相能进行调用。
第二是高延迟问题,比如CPU和GPU之间交互数据,CPU要先把数据放在CPU的缓存层里,再到CPU内存,再通过PCIe链路到GPU的内存然后是GPU的缓存层再到达GPU,整个链路非常长,节点非常多,还涉及IO带宽问题。
因此,我们希望能让CPU直接去读写GPU的内存,这样就能跳过繁复的过程从而降低延迟。带着这样的愿景我们看一下CXL的功能特性。
CXL2.0版本有一个FLIT based transfers功能,采用一种544bit的FLIT模式进行传输,相当于一整块一整块进行数据传输降低数据传输延迟,与NVMe协议的队列概念相像。
CXL2.0增加的新功能
CXL2.0加入了memory Pooling共享内存池的概念,具体来看这几个功能:
1、Switching是交换功能,极大扩展了CXL和device的应用场景,如果没有交换能力,只能直挂在CPU root port下,应用场景少而少。
2、Resource Pooling,就是内存池,这种全新模式将改变整个数据中心的硬件结构。
3、Fabric Management以及CXL EP enumeration过程。简单来说,它在模仿CXL的设备也在模仿PCIe的枚举过程,因为我们对PCIe枚举过程和启动过程非常熟悉,所以CXL也会设计成将其枚举成一个PCIe的一批设备去交互一些性能便于大家开发。
4、安全性。IDE(链接完整性与数据加密),加入加密能力。
5、引入PCIe协议里的一些功能,如热拔插、QoS还有错误上报等。
6、兼容性,向后兼容CXL1.1协议。
接下来具体看CXL的三个子协议及其对应的三种设备。
首先它有三个子协议——CXL.io、CXL.cache、CXL.memory。
CXL.io,从数据来看和PCIe的event一模一样的,主要用于初始化、链接、设备发现,枚举以及寄存器的访问。从某种程度来讲,它就是一个PCIe的event。
CXL.cache,就是device去使用host的主内存。
CXL.memory,是CPU使用devices上的内存,是两个方向。
这部分为什么会有两个协议?两者功能不是一样的吗?这主要是因为要引入一个非对称的概念,CXL协议是一个非对称的协议,PCIe是一个对称的协议,对称即PCIe从host发出来和devices发出来结构一模一样,同时对端设备接收到数据后处理也是一模一样,都是先物理层、协议层再到数据链路层。
CXL不用,CXL.cache是device去使用host的内存,不但要用还要跟CPU的缓存保持数据一致性,如果不通信,有些内存已经被使用或不存在,就会出现很多问题。
而CXL memory不一样,CXL memory是CPU使用device上的内存,不需要去跟device缓存,devices也没有缓存,有也不用交互。因为CPU这边缓存是直接用设备内存的,直接和CPU通信就可以。所以两者的使用方向和目的不一样,就被拆分成了两个子协议。
基于这三个子协议就有了三种设备类型,CXL.io是所有的设备都需要,因为它有一个枚举过程。剩下的两个协议进行组合后就产生了三种设备。
第一种常见的有智能网卡,特点是有缓存没有内存,它的内存是直接使用CPU内存,其优势在于CPU处理数据时非常快。因为内存就在自己这里,直接读取和处理就可以,第三种设备就不同则是只有内存没有缓存,也就是说它其实是CPU的一个内存无限扩展。
传统CPU主板上的内存槽位有限,主板面积有限,而提高单条内存容量,依然有限制。
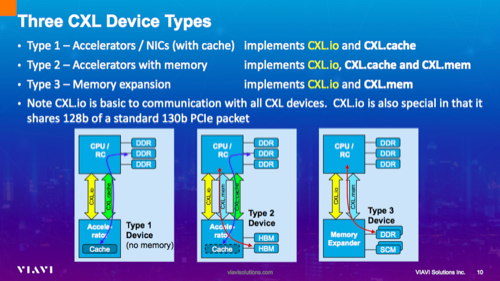
如果能无限扩展CPU的内存,那么就能拥有无限内存,我们也可以看到大量厂商都在尝试做memory的扩展产品,回过来看第二类设备,适用于智能加速卡,集合了前两种设备的功能,支持三个子协议,同时我们可以看到图中cache有一个虚线,其实这个cache可以做动态调整,主要原因在于它本身不跑CXL协议,用PCIe协议,device用自己内存效率很高,但如果把device的内存用CPU管理,那device用自己的内存时,还要跟CPU进行交互获得同意才行效率很低。
这种情况下,它就有一个Master和Subordinate的概念,就是允许device上的cache作为主cache,用自己内存就很快。CPU要用device上的内存时,用CPU的cache和device上的内存进行数据交互,然后去使用device的内存,以此优化device上使用自己内存的方式。
CXL的配置
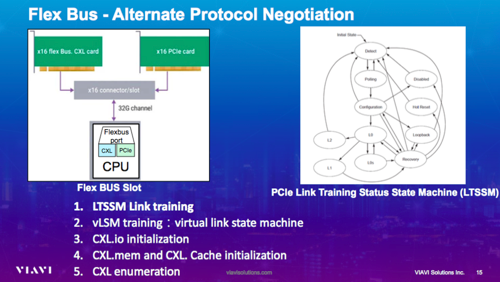
CXL的配置速率是32G支持X16、X8、X4、X2的通道。同时它也支持Bifurcation功能,这时1×16变成的2×8、12×4,速率也支持降速,降级模式从Gen4到Gen3,虽然速率下降,但硬件还需要5.0的硬件。接下来具体看协议层。

左图是一个协议层的关系图,可以从物理层开始看,从下往上。物理层分电极层和逻辑层,和PCIe的物理层相同。但增加了Flex Bus port的概念,在物理层会选择上层是用PCIe的链路层还是CXL的链路层。再往上可以看到一个ARB/MUX的模块,如果是PCIe,这个模块会直接被pass掉,不做任何处理。如果选择CXL,这个模块会仲裁下面上来的数据,判断数据是要转存转到哪个链路层。除此之外还要去维护整个链路的状态。
这是CXL的数据交互的过程,分为五部分:
唯亚威Xgig CXL协议分析
具体来看FLIT数据包的结构,CXL.cache和CXL.memory的一个数据定义。CXL.cache定义了几个概念,第一,D2H就是device到host方向的数据,H2D就是host往device方向的数据。同时两个方向各自定义了三个通道,叫Requesrt,Response和Data。
实际数据交互过程中,它有一个Snpdata是保持cache的一致性,一个UQID,有一个队列概念,用5E追踪整个数据的transaction链路的进程,同样一个任务有同样一个ID。
单纯的数据交互就是host取一个memory,device回一个cmp。当CPU去读device的内存时,它的cache就在自己那一侧,不需要维护device的cache,使用device的内存即可。它定义的时候cache和memory的应用场景其实是分开的。因此两边的数据结构完全不一样。
CXL是通过固定宽度数据包也就是Flit格式传输数据,你可以认为他是一个车厢,有四个位置,限定格式摆放“物品”(携带数据)。

来看一个实际的数据包展示,上面的Xgig TraceView会进行协议分析,帮助你把整个数据罗列在一个event里,方便查看数据同时为你呈现这个transaction是正常完成的,还有用时多长等参数。
另外我们看transaction,也可以看到它其实相当于是一个read,跨越多个FLIT包,第一个发送一个命令,回来一共有8个数据,但第一个FLIT只有3个,第二行是8,有8个要求,后面的PldSlots就有3个,还缺5个,第二个FLIT给了4个,还缺一个。最后一行的PldSlots里面就补充了,所以在CXL里面,一个TLP有可能跨越了多个FLIT包,想看里面的数据,要把这个数据拼凑完整才能看一个整体的数据交互过程。
对于这种协议来讲,其携带的额外信息很多,优势就在于当你出现高速数据传输的时,携带数据的能力越强,速率越高,数据量越大,这种flit模式下的低延迟高速率的优势就会越明显。因此它是主要用这种高速传输的概念。
再来看Xgig协议分析仪会提供CXL里面的触发条件,用于解决定位问题,让某一个特殊CXL的数据,把主要问题集中在那个event出现的时候,分析仪可以设计一个触发条件,触发这个点,然后把这个点前后的数据抓出来,这样大家定位问题和分析问题会非常方便。
第二还有进行性能分析,分析仪会去分析这个CXL比如延迟的最大值,最小值,还有它的速率的最大值最小值,以及flits的一些极限值,还有时间上的最大最小值,进行性能的统计和计算。
最后会统计出数据,将你抓取的数据里所有CXL的cache,memory具体是多少数量,其中具体分read还是write还是response,所有数据都会统计出一个数量。同时右边呈现一个成像图,把这整个数据分成50等份,向你显示read在这个数据抓取时是前面、中间还是最后比较多。
VIAVI Xgig PCIe 5.0 分析仪介绍
唯亚威在去年就已经发布了Gen5×16的硬件产品系列,支持Gen5×16的PCIe链路最大,同时上下兼容低速低带宽。存储空间会非常大,存储空间最大为256GB,达到RAM级别,同时分析仪还拥有分段能力,这是我们所特有的。
另外唯亚威还支持Exerciser的模拟协议一致性,同时支持Jamming错误注入,最后一个是Analyzer,支持CXL2.0的协议分析,也支持PCIe的协议分析。

唯亚威分析仪特点包括,第一,我们已经过了PCI SIG协会的4.0/5.0的协会评测认证,可以从协会的官网看到我们的MOI文档。
第二个特点是唯亚威在上海有一个研发中心和实验室,在数据支持方面很方便,尤其是基于中国区客户功能需求把握方面。传统外资公司很多都是把需求转给美国,然后再转给美国的研发去分析问题。 因为在其他地区并不一定能理解中国区的不同功能需求。而唯亚威在中国区的实验室可以处理各种问题,对重现和模拟一些不同环境非常有利。






