9月18日晚间,英特尔和英伟达同时宣布,英伟达投资50亿美元购买英特尔普通股。
双方合作在企业级市场打造定制的至强x86处理器,在消费级市场打造集成了英伟达RTX显卡的CPU,可以说是联手打造顺应AI市场需求的芯片产品。
对此,我只能说非常期待。

消息一出市场反应激烈,英特尔股价立马强势反弹。
不久前,美国政府宣布用89亿美元购买英特尔9.9%的股份,随后软银以20亿美元认购英特尔普通股。现在又以低于市场价引入英伟达的投资,看来英特尔很希望得到这些资金。
当然,我不太关注资本层面的操作,而是更在于产品市场方面的分析。今天就来聊一聊英伟达和英特尔的一点过往,然后看看这次合作之后可能会打造出什么样的产品,讲真,还是挺期待的。
英特尔与英伟达爱恨交织的30多年
从上世纪90年代开始,英特尔就是做CPU的,而英伟达就是做显卡的。看似井水不犯河水,但其实两家的竞争意味一直很浓厚。有媒体称,1998 年,黄仁勋曾说过:“英特尔想摧毁我们,我们的任务是先干掉他们。”
从市场来看,在PC时代的早期,两家功能角色互补,关系相对融洽。2001年开始,英伟达为英特尔开发了叫nForce的系列芯片组产品,市场反响不错,英伟达靠这个赚到了不少钱,但在一定程度上冲击了英特尔自家的芯片集产品。
大概在2005年前后,英特尔本来有机会以200亿美元收购英伟达,但由于当时报价超预期,收购被搁置,英特尔转向内部研发,启动“Larrabee”项目,项目以失败告终,英特尔没能成功进入独显市场。
2008年,英特尔决定把内存控制器从主板芯片组中拿出来,集成到CPU内部。如此一来,导致英伟达无法再为英特尔CPU开发芯片组,nForce业务一夜之间被英特尔一锅端了。双方最终走向法庭,关系一落千丈。
这还没完,2010年以来,英特尔大力发展集成显卡,其性能不断提升,只要不是玩游戏和有专业需求的用户,用户就不用再单独购买独立显卡了。这对于英伟达的低端显卡带来了不少冲击。
此后的十年时间,英特尔继续深耕x86通用计算处理器,而英伟达则在并行计算道路上越走越远,除了打造更强的游戏显卡以外,也用GPU + CUDA的方案在HPC市场上与英特尔的x86,以及Arm处理器竞争。
CPU的优势是通用性强,逻辑任务表现好,而且生态强大。2015年以来,显卡以并行计算优势在超算市场上获得逐步采用。2020年7月,英伟达的市值开始超越英特尔,当时两家市值约2500亿美元。
2022年以来,ChatGPT来袭,英伟达数据中心GPU成了训练和运行大型语言模型不可或缺的核心工具,市场疯抢英伟达显卡,一步步把英伟达市值推到了4万亿美元。
AI时代分水岭,让“英”与”英”达成历史性和解
此时的英特尔则面临多种冲击和挑战。首先,英特尔在其引以为傲的芯片制造工艺上遭遇了重大挫折,先进节点的研发和量产一再延迟,使其长期保持的技术领先地位被台积电(TSMC)等代工厂超越。
其次,英特尔在AI市场上希望靠Gaudi来竞争,这是英特尔于2019年收购Habana Labs获得的AI加速器产品线,尽管Gaudi 3还有一些竞争力,而且价格也友好,但始终难以撼动英伟达CUDA生态系统的强大壁垒。
与此同时,英特尔希望用通用计算x86至强处理器参与到AI市场,比如在至强处理器中加入AI加速指令(如DL Boost, AMX)提高AI推理的性能表现,但并没有显著提升英特尔在AI市场的影响力。
2022年,英特尔推出Arc(锐炫)桌面级独立显卡,但该产品主要用于消费级和工作站场景,并没有撼动英伟达高端桌面级显卡市场,更没有影响到英伟达的数据中心服务器市场。CEO陈立武承认,英特尔“短期内”无法与英伟达的高端系统竞争。
此时的数据中心市场发生了巨大变化,原本以CPU为中心的市场,逐渐转向以GPU加速计算为中心。英伟达的平台(GPU + CUDA + NVLink)成为数据中心的新标准,所有希望构建AI基础设施的公司,都别无选择地依赖英伟达的技术。
英伟达获得了超强的定价权和生态系统控制力,而英特尔至强CPU被降级为英伟达AI系统中的“主机CPU”,一个重要但已非核心的辅助部件,这种战略地位的根本性转变,正是2025年发生这次历史性大和解的背景。
当然,其实和解后背必然还受到了美国产业政策的影响。美国希望制造业回流,特别是希望芯片生产制造转回美国本土。美国政府入股英特尔是最明显信号,软银和这次英伟达投资英特尔也是在向美国政府示好。
“英”与”英”将打造什么样的AI产品?
英特尔需要接入英伟达的生态系统,才能参与到增长最快的AI市场。英伟达选择与英特尔合作,目前英伟达的GPU将不会由英特尔代工部门生产,选择英特尔主要也是以联合打造产品为主。
接下来看两家要打造的数据中心级AI产品:
数据中心市场部分,会利用英伟达的NVLink连接英伟达和英特尔的技术架构,英特尔将构建为英伟达定制的x86 CPU,英伟达会将其集成到其AI基础设施平台中并提供给市场。

此前两家已有了一些合作。2025年5月,英特尔发布了三款全新英特尔至强6性能核处理器,其中一款6776P被用作是DGX B300的主控CPU,选择英特尔至强 6,说明它在I/O、内存、协同能力等方面满足了DGX B300的苛刻需求。
此前合作并非为英伟达定制CPU,而这次合作则要利用英伟达的NVLink技术打造定制CPU。大概率会用到此前英伟达推出的NVLink Fusion技术,这是一个把英伟达专有的NVLink开放给合作伙伴的技术。
众所周知,英伟达的NVLink主要用于GPU之间的高速互联,而主流x86 CPU并不支持这一接口,CPU与GPU只能通过PCIe通信,带宽和延迟都成了瓶颈。为突破这一限制,英伟达曾尝试收购Arm,希望借此打造能够原生支持NVLink的处理器。
虽然收购未果,但公司随后推出了NVLink-C2C协议,让Arm架构CPU可以直接通过NVLink与GPU交互。基于这一技术,Grace CPU与Hopper GPU结合诞生了GH100、GB200等超级芯片,也推动了英伟达新一代AI加速系统的出现。
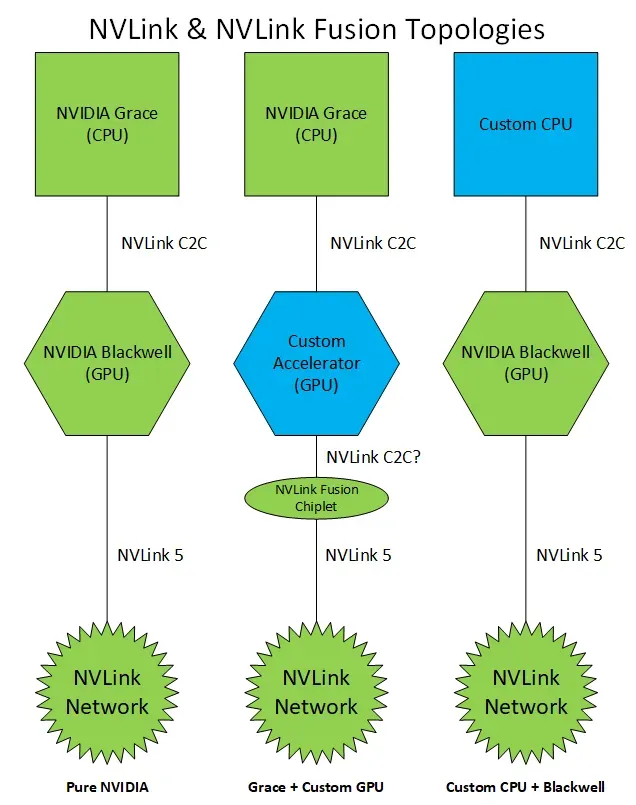
NVLinkFusion技术中,用户可以选用三种系统构建方式。要么选GB超级芯片方案,要么把CPU换成第三方的,要么把GPU加速器换成第三方的,几个组件之间通过NVLink5进行接入。
显然,英特尔为英伟达定制的CPU就是要采用第三种方式。具体操作中,英伟达会用NVLink 5 Chiplet技术,在英特尔的CPU中嵌入一块来自英伟达的小芯片,让英特尔至强支持NVLink,从而接入到英伟达的AI加速系统中。
此件有消息称,富士通和高通正在开发支持NVLinkFusion的CPU,而此次高调宣布与英特尔的合作,应该会更重视这次与英特尔的合作。类似的,GPU加速器厂商也可以介入NLink系统中,但我估计这类合作伙伴不会很多。
有朋友可能会好奇,接入NVLink的价值是什么?
以GB200系统为例,通过NVLink连通之后,Grace CPU的DDR内存和Hopper GPU的HBM显存形成了一个统一、连贯的内存地址空间,GPU可以像访问本地显存一样访问CPU的内存,既简化了编程模型,也解决了数据传输瓶颈。
在消费级产品上可能的合作方式
如果你有耐心看到这里,接下来猜一下英伟达与英特尔在消费级产品上合作,可能会打造出什么样的产品。
官方消息说,在个人计算领域,英特尔将打造并向市场推出集成NVIDIA RTX GPU小芯片的x86 SOC。x86 RTX SOC将为各种需要集成世界一流CPU和GPU的PC提供支持。
如果说,这里只是用英伟达的RTX显卡取代英特尔的集显那就太没意思了,我更期待的是能打造出类似苹果M系列那样的产品,把CPU、GPU等都整合到同一块芯片里,让CPU和GPU共享一套高速统一内存,数据不需要在不同芯片之间来回拷贝。
大语言模型推理需要大容量、高带宽、低延迟的内存。苹果M系列的统一内存架构,使苹果电脑能高效运行数十亿甚至上百亿参数的模型,而无需像传统PC那样依赖独立显卡的大显存,要知道,大显存的英伟达显卡可太贵了。
英伟达DGX Spark小型台式机开发套件,复制了DGX工作站或服务器的架构和软件堆栈,让开发者可以测试代码,并且能在在Spark上运行,就能在DGX上运行。DGX Spark采用了NVLink-C2C互连技术,本质上跟DGX系统是一样的。
如果英特尔和英伟达联手,打造统一内存的SoCCPU的话,则可以让Windows系统具备类似苹果电脑系统那样的推理能力,从而降低普通人在本地使用AI推理技术的能力,从而为Windows电脑市场带来更多增量,或许AIPC时代才能真的来到。
结束语
从30多年的相爱相杀到如今的握手言和,英伟达与英特尔的这次历史性合作,不仅仅是资本层面的战略布局,更是两家芯片巨头在AI时代寻求新突破的必然选择。
你是否看好这次合作?看好为英伟达定制的至强,或者我想象中的集成了RTX显卡的酷睿呢?(也许就不叫酷睿了)我反正挺期待的,真的。