
随着人工智能浪潮席卷全球,从基础大模型训练,到AI智能体、RAG应用与边缘推理落地,整个AI产业链正在加速从“算力为王”转向“存力竞速”的深度演变。HBM(高带宽内存)作为高性能AI芯片的关键部件,正在进入新一轮产品更迭。
据TrendForce最新调研,HBM4的制造复杂度已显著上升,其价格溢价预计将超过30%,远高于前一代HBM3e的20%。而以英伟达、AMD为代表的头部AI芯片厂商,正在为下一代GPU产品全面引入HBM4,带动HBM供应链进入新一轮投资与竞争周期。
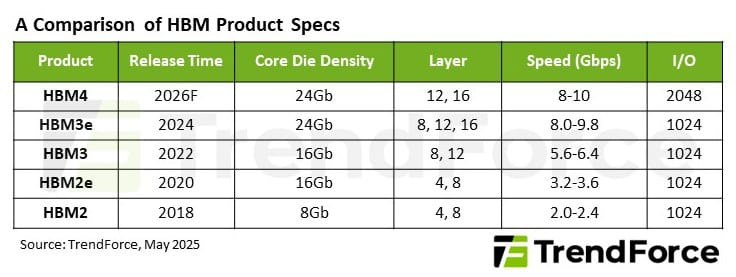
HBM4“通道翻倍”,性能跃升与制造难度并存
HBM4与HBM3e相比最大的变化在于I/O通道数量从1024个翻倍至2048个,虽然单通道数据速率维持在8Gbps以上,但总带宽实现成倍提升。更高的通道数量使HBM4即使在同等速率下,也能实现双倍数据吞吐,大幅缓解AI推理与训练中“内存带宽瓶颈”。
但这种跃升也带来了显著的制造挑战:
Die面积显著扩大,增加了封装成本与良率压力;
更复杂的信号布线对TSV(硅通孔)工艺、封装对位精度、热设计等提出更高要求;
越来越多厂商从“纯内存Base Die”转向“逻辑型Base Die”架构,这不仅增加设计复杂度,也抬高了与逻辑芯片协同的门槛。
因此,HBM4的价格溢价预计将高于HBM3e的20%,达到30%以上,未来也可能进一步上升。这种成本上浮将直接传导至AI芯片、整机服务器甚至终端应用中。
AI大模型的参数量、上下文长度和推理并发能力持续增长,对GPU架构提出前所未有的带宽挑战。在这个背景下,HBM4已成为高端GPU的必选项。
在2025年GTC大会上,NVIDIA剧透了新一代Rubin GPU架构,明确配套HBM4作为主存;与此同时,AMD也在准备与之抗衡的MI400系列,预计同样会引入HBM4技术。
这意味着,未来AI算力竞争的焦点,不只是TFLOPS多少,而是“每秒能处理多少数据”。而这背后,HBM4将成为衡量AI芯片综合性能的关键支点之一。
可以预见,HBM4的部署不仅会出现在顶级GPU中,还将向AI推理芯片、边缘计算模块、AI PC处理器等领域延伸。它将逐步从“旗舰专属”变为“高端标配”。
逻辑基底成为趋势,HBM走向“智能化协同”
除了通道数量的跃升,HBM4另一关键创新在于:引入逻辑型Base Die架构。
以往的HBM3e采用“纯内存型”Base Die,仅起到信号中转作用,功能相对简单。而在HBM4中,SK海力士、三星等厂商开始与晶圆代工厂合作,探索引入轻量逻辑功能的底层控制模块,例如错误检测、电源管理、通道优化、SoC协同等。
这种架构升级带来的价值在于:
降低SoC与HBM之间的延迟,提升带宽利用率;
更好支持AI芯片复杂的访存模式;
为HBM未来嵌入轻计算能力打基础,比如近存计算(Near-Memory Compute)等形态。
TrendForce预测说,到2026年,HBM总出货量将超过300亿Gb,HBM4也将在当年下半年取代HBM3e成为主流产品。但同时,产业竞争格局也日趋集中与不均衡。
SK海力士仍将保持超50%的市场份额,在良率、技术路径、客户绑定方面领先;
三星虽具工艺与封装能力,但需提升HBM4良率与稳定性;
美光仍处于追赶阶段,HBM3e尚未规模交付,HBM4量产能力仍待验证。
此外,由于HBM需要HBM Die + Base Die + TSV封装 + SoC协同的完整能力,整个产业链的协同压力巨大,任何一环的不成熟都可能影响产品交付节奏。
对于下游AI芯片、服务器整机厂商而言,选对合作供应链、预判量产时点、控制成本溢价,将是能否把握新一代AI基础设施机会的关键。
未来,谁能率先把HBM4稳定落地,谁就有可能在下一轮AI芯片大战中占据上风。我们看到的不仅是一款存储产品的更替,还是AI基础设施底座竞争格局的重构。







