如果你用AWS,数据存在Amazon S3里,当你有需要跑文件系统类的应用,比如AI训练、AI智能体、或者其他需要用NFS挂载的系统时,都需要你把数据拷一份到Amazon EFS文件存储或者下载到本地,现在不用了。
最近,AWS发布了S3 Files功能,你现在可以把任何一个已有的S3 Bucket直接当成本地文件系统来挂载,用标准的文件操作方式去读写Bucket里面的数据,当然,同时也能用S3 API来访问数据。
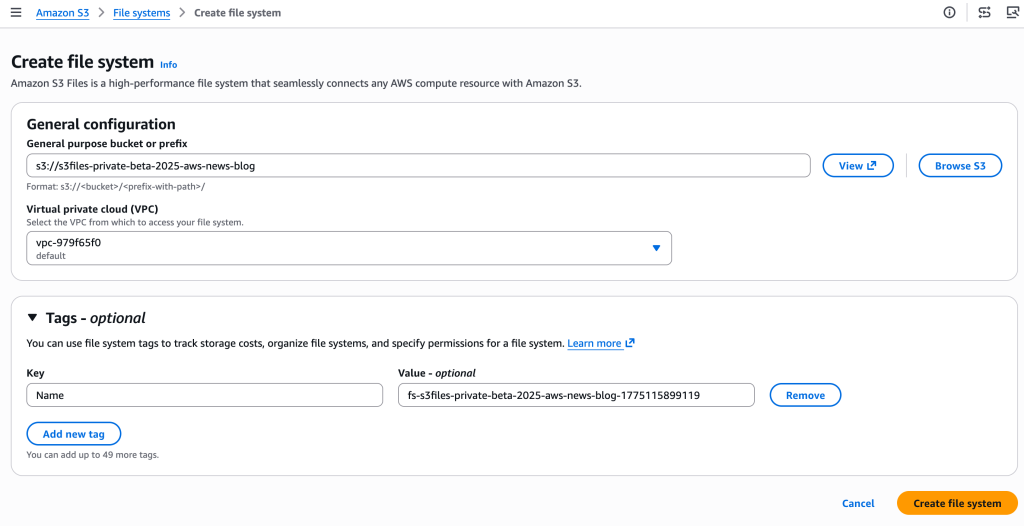
上图展示的是对一个Bucket桶来创建文件系统。说白了,就是把EFS接到了S3的上面。创建完文件系统后,EC2、ECS、EKS什么的看见它,都把它当文件系统直接挂载。而且,它可以同时挂载到多个目标,完美实现数据共享。
挂载好之后,当你通过文件系统处理特定文件和目录时,相关的文件元数据和内容会被存储到文件系统的高性能存储中。当用户访问这些文件时,能享受到低延迟访问性能,AWS说,延迟能低到1毫秒。
而对于没有存到高性能存储中的文件,比如个头特别大,好几十GB的文件,S3 Files会自动直接从那个Amazon S3里面给你提供这些文件。虽然延迟可能会高一点,但是带宽高啊,而且不占用高性能存储层,还省成本。
此外,对于字节级别的数据读写,S3 Files可以只仅传输请求的那部分字节数据,而不是像S3那样把整个对象甩给你,这样能减少数据移动的成本。如果你按照文件的方式改了文件,这些修改最终也会落到S3桶里。
之所以现在这么干,是因为AI需要。Agent要访问文件的时候,你给它一个文件路径就行了。如果要访问对象存储,那就需要把文件下载到本地,如果没有本地文件系统,智能体上下文一丢,就得重新下载,很不方便。
S3 Files的出现,终于把对象存储和文件系统之间的那堵20年的墙给拆了。过去,S3 是大仓库,便宜、耐用、无限扩展,但你不能在里面直接干活,必须先把东西搬到工作台,现在,S3 Files把整个S3都变成了智能体的工作台,你就说强不强?
过去,用户需要自己在S3之外维护额外的文件系统层,比如,NetApp的FSx for ONTAP和戴尔的PowerScale就在AWS上提供文件+对象的混合访问能力。但S3 Files是AWS原生集成的能力,提供完整的文件存储,这多少会让存储厂商有点不爽,但是用户开心。