
三月的旧金山,阳光明媚,在临近海边Fort Mason Center的Festival Pavilion,举目便可看到远处的金门大桥。
在这片象征着科技与未来的土地上,Arm Everywhere活动正在举行。一场足以改写数据中心CPU格局的发布正式亮相。

与此同时,会上,Arm首席执行官Rene Haas正式带来了由Arm自主设计、面向人工智能(AI)数据中心的CPU——Arm AGI CPU。这不仅是一场产品发布会,更是Arm发展历程中具有里程碑意义的战略抉择,宣告这家以IP授权为核心的半导体巨头,正式迈入自主造芯的全新赛道。
这次是Arm首次推出自己的芯片产品,这标志着Arm从IP到Arm计算子系统(CSS)再到量产芯片的全新布局。从提供底层架构授权,到打造标准化计算子系统,再到直接推出完整芯片产品,Arm的三步进阶,本质是顺应AI算力需求的主动进化,也是对数据中心市场竞争格局的深度回应。
在AI算力竞争日趋白热化的当下,仅靠IP授权已难以满足客户对一体化、高性能、低时延解决方案的需求,自主造芯既是Arm技术能力的集中展现,也是其巩固生态主导力的必然选择。
AI基础设施时代的CPU变革
在AI时代,算力无处不在,看看现在热闹的芯片市场便可见一斑,比如GPU以及各种AI芯片。在这场盛宴中,CPU似乎处于一个尴尬的地位。长期以来,AI算力的讨论焦点始终集中在GPU与专用AI加速器上,CPU被视为“配角”,其在AI系统中的价值被严重低估,甚至被认为是算力体系中的“边缘角色”。
一方面是在AI加速方面,CPU相比专门的加速器在表现方面并不尽如人意。不过随着AI从模型训练向在线推理转变,整个AI系统生成的词元(token)数量正在飞速增长,亟需更多CPU来承载推理、协同调度与数据迁移等任务。生成式AI的普及让推理场景呈现指数级扩张,海量token处理、跨芯片调度、数据流转与算力分配等工作,都高度依赖CPU的稳定支撑,CPU正从AI系统的“辅助角色”转变为“刚需核心”。
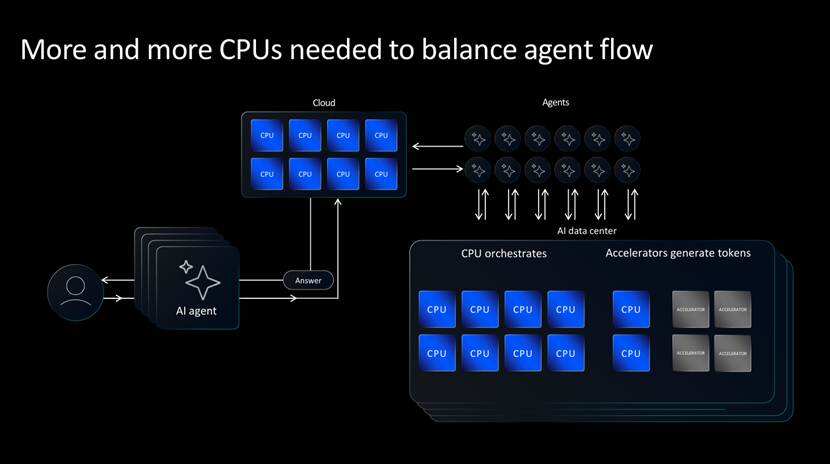
与此同时,数据中心对每吉瓦(GW)功耗提供的CPU算力需求将增长至当前的四倍以上,这就要求新的CPU产品既能支撑高吞吐量所需的性能,又能满足实际功耗限制下的能效要求。全球数据中心能耗管控日趋严格,算力密度与能效比成为厂商竞争的核心指标,传统CPU架构已无法适配新一代AI工作负载,行业亟需一场面向AI场景的CPU架构革命。
所以,我们看到主流的CPU企业纷纷革新自己的处理器架构来适配AI类工作负载的需求变化。对于Arm来说,Arm Neoverse现已成为当今众多领先超大规模云服务及AI平台的核心支撑,包括Amazon Graviton、Google Axion、Microsoft Azure Cobalt及NVIDIA Vera等。经过多年生态深耕,Arm架构已在云数据中心站稳脚跟,积累了海量软件适配与场景落地经验,这为Arm推出自主AGI CPU奠定了坚实的生态基础,也让其有底气直面x86架构的长期垄断。
Arm AGI CPU有何过人之处?
我们现在生成式AI在快速发展,那么相比我们常见的CPU产品,Arm AGI CPU有什么不一样的地方呢?这款产品并非简单的核心堆叠,而是从AI推理、大规模并行、高密度部署等核心需求出发,进行的全维度深度优化,每一项参数都直指当前数据中心CPU的痛点。

在性能表现方面,单颗CPU集成多达136个Arm Neoverse V3核心,在单核、系统级芯片(SoC)、刀片式服务器及机架各层级均实现行业领先的性能表现,同时提供每核心6GB/s内存带宽,时延低于100ns。超大核心规模与高内存带宽、低时延的组合,完美匹配生成式AI推理的高并发、低延迟需求,彻底解决传统CPU在AI推理场景下核心不足、带宽瓶颈、时延过高的问题。
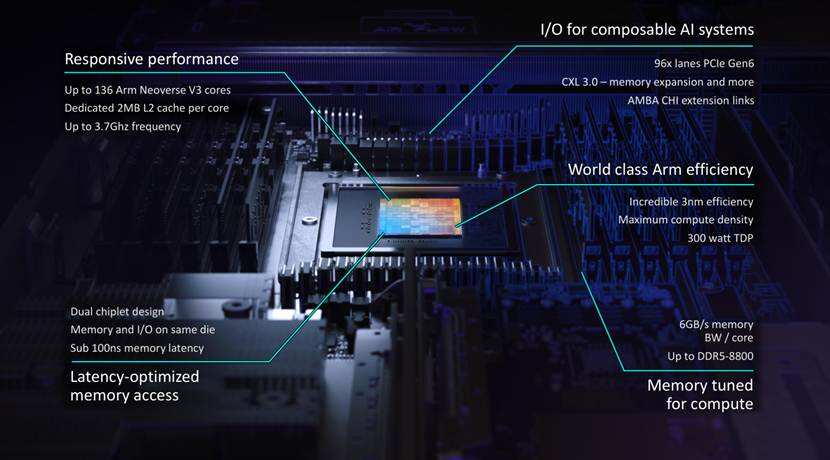
在扩展性方面,300瓦TDP设计,每线程独立核心,可在持续负载下提供确定性性能,避免降频与线程闲置。独立核心设计让多任务并行时不会出现性能损耗,确定性性能输出能保障AI服务的稳定性,这对云服务商、AI企业而言,是保障业务连续性的关键优势。
在能效方面,支持高密度1U服务器机箱的风冷部署方案,单机架可支持多达8160个计算核心;同时也支持液冷系统,单机架可实现超过45000个核心的部署规模。风冷与液冷双适配的设计,兼顾了中小规模数据中心的低成本部署与超大规模集群的高密度算力需求,灵活适配不同客户的基础设施条件。
从运行频率到内存及I/O架构,Arm AGI CPU的每一处设计都经过专门优化,在高密度机架部署场景下,支持大规模并行、高性能的代理式AI工作负载。这种全链路优化,让Arm AGI CPU不再是通用型CPU,而是专为AI时代打造的“定制化算力核心”。

Arm的参考服务器采用1OU双节点设计,该服务器采用符合开放计算项目(Open Compute Project,OCP)的DC-MHS标准规格设计。每台刀片服务器中集成两颗CPU芯片,并配备独立内存与I/O,共计272个核心。这些刀片服务器可在标准风冷36千瓦(kW)机架中满配部署,30台刀片服务器可提供总计8160个核心。贴合OCP开放标准的设计,能快速融入现有数据中心体系,降低客户迁移与部署成本。
此外,Arm还与Supermicro合作推出200千瓦(kW)液冷设计方案,可容纳336颗Arm AGI CPU,提供超过45000个核心。面向超大规模算力集群的液冷方案,直接瞄准OpenAI、Meta等顶级AI企业的需求,抢占高端AI算力市场。
来自Arm的测试数据,Arm AGI CPU可实现单机架性能达到x86平台的两倍以上,每吉瓦AI数据中心算力的资本支出(CAPEX)节省高达100亿美元。这组数据不仅是性能优势的证明,更是对数据中心长期运营成本的重构,在算力规模化扩张的背景下,成本优势将转化为核心竞争力。

Arm计划向社区贡献该参考服务器设计方案及配套固件,并进一步提供包括系统架构规范、调试框架及适用于所有Arm架构系统的诊断与验证工具等资源。开放生态的策略,能快速吸引开发者与合作伙伴,加速Arm AGI CPU的场景落地,形成良性循环。
Arm商业模式探索的新阶段
在活动上,来自Meta的嘉宾介绍了其利用该代理式AI CPU优化其全系应用的基础设施,并与其自研的Meta训练与推理加速器(MTIA)协同部署,从而在大规模AI系统中实现更高效的编排与调度。双方承诺将围绕Arm AGI CPU的多代芯片产品展开长期深度合作。头部科技企业的深度绑定,验证了Arm AGI CPU的技术价值,也为其商业化落地打开了重要突破口。
除Meta外,Arm已确认与Cerebras、Cloudflare、F5科技、OpenAI、Positron、Rebellions、SAP、SK电讯等企业达成进一步的商务合作。覆盖AI芯片、云服务、企业软件、通信等多个领域的合作矩阵,说明Arm AGI CPU已获得全行业认可,生态版图快速扩张。
熟悉Arm的朋友知道,Arm通过IP授权以及CSS,推动Arm计算平台的发展。Arm此次向芯片产品领域的拓展,为生态合作伙伴在构建和部署基于Arm架构的基础设施时提供了更大的灵活性。合作伙伴可根据需求,灵活选择Arm IP授权、Arm CSS方案,或直接部署Arm自主设计的芯片产品。“三层服务模式”让不同规模、不同需求的客户都能找到适配的合作方式,极大拓宽了Arm的商业边界。
为加快产品落地与规模化部署,Arm与永擎电子、联想、广达电脑、Supermicro等头部OEM厂商及ODM厂商展开合作,早期系统现已推出,更广泛的商用部署预计将于今年下半年落地。依托成熟的硬件制造生态,能快速实现产品量产,抢占市场窗口期。

超大规模云服务商、云计算、芯片、内存、网络、软件、系统设计与制造等领域的50余家领军企业,均对Arm计算平台向芯片领域拓展表示支持。其中包括亚马逊云科技、博通、谷歌、Marvell、美光、微软、NVIDIA、三星、SK海力士、台积公司等行业标杆企业。全产业链的支持,意味着Arm AGI CPU从芯片到系统、从软件到硬件的生态闭环已基本形成。

Arm AGI CPU是Arm全新数据中心芯片产品线的首款产品,该产品线将与Arm Neoverse CSS产品路线图并行推进,确保所有Arm数据中心客户在平台架构与软件兼容性方面实现协同发展。双路线并行的策略,既保障了原有客户的投资与兼容性,又能通过自主芯片引领技术创新,稳固Arm在AI数据中心市场的长期地位。
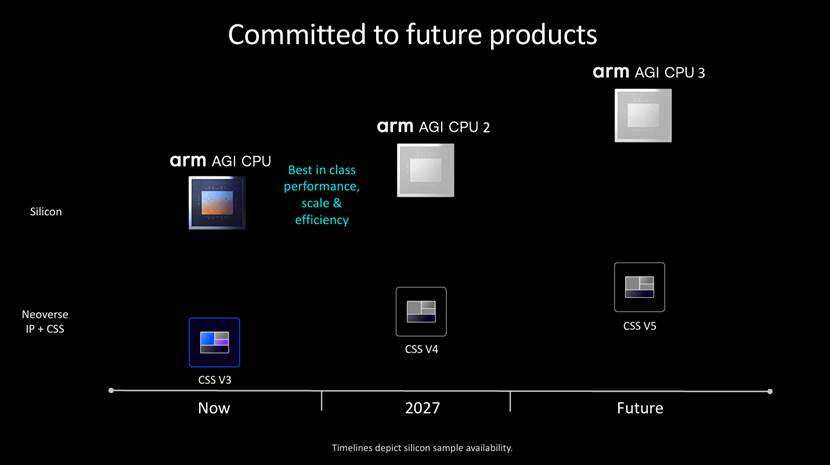
从IP授权到自主造芯,Arm AGI CPU的发布不仅是Arm自身的战略转折,更将重塑AI数据中心CPU的竞争格局,推动整个行业向更高性能、更低能耗、更开放生态的方向迈进。
本文来源于DOIT传媒,文章内容仅供参考,不构成投资建议。


评论列表