在数据库领域深耕近二十年后,海量数据站在了AI时代的风口上。随着Vastbase V100向量数据库的发布,海量数据得到了更多关注和采用。海量数据总裁肖枫表示,这并非盲目跟风,而是深思熟虑后的提前布局。
2025年数据存储产业大会上,肖枫接受DOIT传媒采访时,不仅复盘了海量数据从技术服务到国产数据库领军者的发展史,更深刻剖析了向量数据库如何成为连接私域数据与大模型的关键“桥梁”,以及如何与存储结合追求卓越。
国内数据库第一股,布局向量数据库市场
2007年,当国内数据库行业尚不明朗时,一家叫海量数据的公司成立了。早期业务主要以技术服务为主。2017年,海量数据在上交所上市,成为国内首家以数据库为主营业务的主板上市公司,成为国产数据库第一股。肖枫表示,上市后有助于筛选并吸引最优秀的人才,对于公司规模化发展,对于提升其产品竞争力都很有帮助。
2020年,海量数据打造纯国产的企业级关系型数据库Vastbase G100。此后不久,海量数据开始向多模方向发展,如今除了关系型数据库,还提供时序、GIS、向量数据库等产品。
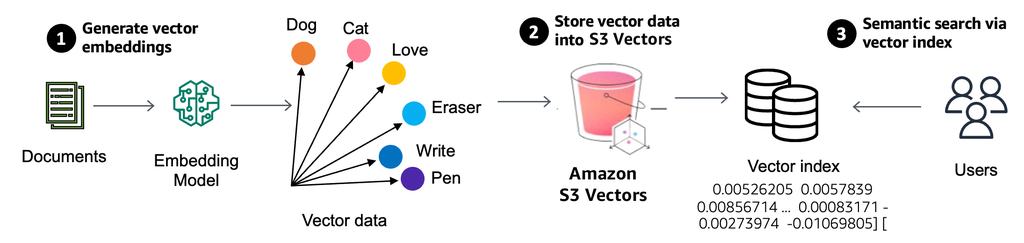
2024年,海量数据发布了Vastbase V100,恰好在25年初,踩到了AI时代的风口。这是一款面向企业级AI应用的向量数据库,融合了关系型数据库与向量数据处理能力,面向知识库、向量检索、语义搜索等AI应用场景而设计。

海量数据已获得了许多用户的认可,包括来自政府、工业、金融、通信、能源、交通等领域的众多头部企业。而随着生成式AI技术的发展,越来越多用户开始关注到向量数据库,这将为海量数据下一个阶段做好准备。

只有“学霸“含量极高的研发团队才行
“偶然之中有必然,如果不是跟硅谷联系多、同学之间交流频繁,也不可能笃定AI一定会成为趋势。”先人一步布局向量数据库带来了市场优势,当被问及为什么能提前布局AI和向量数据库时,肖枫给出了这样的答案。
这种“必然”源于海量数据独特的信息触角与人才密度。肖枫毕业于中科大,朋友圈里有许多校友混迹于硅谷,也有许多在外企的前同事。得益于这样的信息优势,海量数据早在GPT早期版本发布时便敏锐捕捉到了技术风向。
同时,海量数据有一支“学霸”含量极高的研发团队——核心成员多出身于中科大(部分成员来自中科大少年班)、清华等顶尖学府,也不乏许多业界技术研发大牛。
“我们选人的标准极其严苛,尤其针对研发。” 肖枫如是说。他在人才策略上坚持着近乎苛刻的原则,它是在追求更高的条件概率,这是贝叶斯定理——通过设定更有利的先验条件,让最终选到优秀人才的概率更高。
在他看来,数据库是典型的“科技公司”而非“产品公司”,正如Oracle RAC的诞生依赖于天才的灵感,好的产品都是最牛的人做出来的。向量数据库涉及很多复杂算法,只有具备深厚数学功底的顶尖人才才能熟练运用,这些人才为海量数据构建了壁垒。
在向量数据库市场的差异化突围
2025年,DeepSeek的爆火给海量数据带来了一次“神助攻”。它让市场看懂了向量数据库的价值——通过向量化处理,大模型能精准识别私域数据中的隐形关联,从而挖掘数据中的价值。
“以前经常有人问向量数据库有什么用,现在DeepSeek出现后就没人问了”肖枫说。如今向量数据库的应用场景越来越多,在金融投资、体育竞技、工业质检、医疗诊断、教育科研等非常多的领域发挥作用。
虽然从技术角度看,海量数据可以部署到云上和本地环境,但考虑到国内的云生态环境和在安全上的顾虑,目前用户仍是以本地私有化部署为主。如此便避免了与公有云的竞争,在企业私域数据领域找到了差异化生存空间。
从技术路径上看,相比于基于pgVector的插件式改造,Vastbase V100坚持将向量引擎写入数据库内核。这避免了插件模式在性能和安全性上的不足,能充分利用原生内核的优势,提供更高的压缩效率和融合性。
从产品设计来看,海量数据将传统事务性数据库与向量数据库的能力相结合,与原生向量数据库相比,它的标量处理能力更强,这样就能实现能“先用标量拦一刀,再用向量对数据做深度分析”的效果。
这种设计,可以让原有用户通过简单升级完成平滑演进,既降低了升级的成本和技术复杂性,也降低了用户的学习曲线。肖枫认为,这种兼顾传统事务性业务与AI向量能力的模式可能会很有市场。
向量数据库与存储都是“AI数据平台”的一部分
2025数据存储产业大会由中国电子工业标准化技术协会主办,中电标协数据存储专业委员会承办,海量数据作为副会长单位,代表数据库厂商参与了此次存储主题的活动,在肖枫看来,这并不奇怪。
肖枫认为,数据库与存储的界限正在模糊,未来可能会统称为“AI数据平台”。回到技术的本质,他认为存储与向量数据库有很多结合的点,比如,未来向量数据库可能会像存储一样进行冷热分层。
而且,在国内高端算力受限的背景下,向量数据库的一大核心价值是节省算力。通过与存储技术的深度结合,把一些处理工作下推到存储,让向量数据库帮助企业在有限的资源下实现AI效能最大化。
“做数据库的是离不开存储的,存储技术对数据库的影响实在太大了,无论是硬盘存储还是其他存储形式,存储与数据库的技术结合非常多”肖枫表示,未来两者的结合还会有很多想象空间。
结束语
当数据库不再仅仅是数据的仓库,而是逐步演变为连接私域数据与大模型的关键桥梁,海量数据站在AI创新的风口上,正以Vastbase V100为支点,试图撬动企业私域数据的巨大潜能,为千行百业的智能化转型注入新的数据动能。