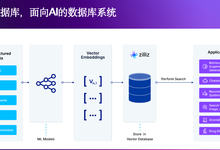
Amaozn S3确实是AWS的亲儿子!最近,AWS发布了Amazon S3 Vector,又让Amazon S3成了第一个支持向量存储的对象存储。
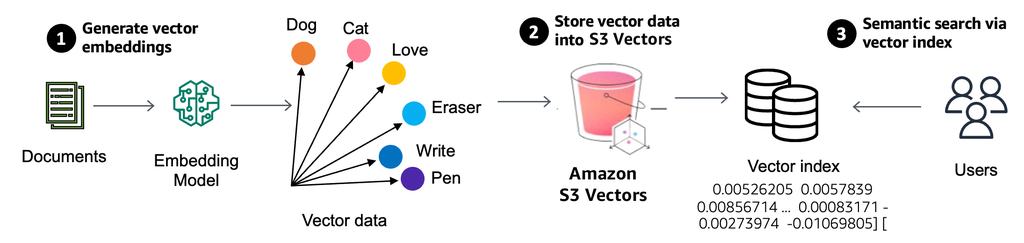
此前,AWS有一个叫Amazon OpenSearch的服务,也可以存储向量数据,支持向量搜索功能。这一服务性能比较高,但是成本也比较高。为了降低成本,把OpenSearch中不常用的数据转移到对象存储上,于是就有了Amazon S3 Vector。
AWS的专家在博客中提到,Amazon S3 Vector是一种专门构建的持久向量存储解决方案,可以将上传、存储和查询向量的总成本降低高达90%。
企业部署大模型几乎都会采用RAG技术,RAG技术需要对接大量非结构化数据,需要将大量数据转变成向量存储起来。过程中需要设置向量数据库,配置计算资源,还要手动与大语言模型进行集成。
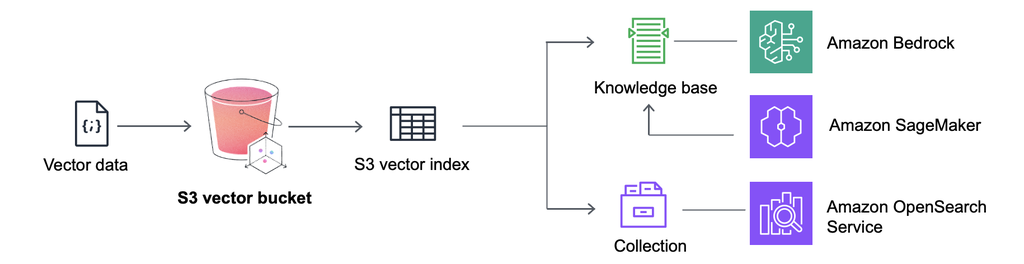
现在,Amazon S3 Vector直接与Amazon Bedrock知识库和Amazon SageMaker Unified Studio原生集成,在创建知识库时,可以选择S3 Vector桶作为向量存储选项,它可以降低对构建和使用RAG技术的成本。
用户也可以让Amazon S3 Vector与Amazon OpenSearch 服务结合使用,以降低低频访问的向量的存储成本,随着需求增加或需要更高的性能,也可以快速将其迁回到 OpenSearch。
Amazon S3 Vector通过新的向量存储桶实现,该存储桶“拥有一套专用的API,用于存储、访问和查询向量数据,无需配置任何基础设施”。该存储桶包含两种类型的数据:一类是向量,另一类是用于向量索引。
Amazon S3 Vector本质上还是对象存储,按照常规S3的计费方式来收费,存储会收取基础的存储费用,读写部分按照次数单独计费。
Amazon S3 Vector省去了配置计算实例的麻烦。如果没有Amazon S3 Vector,企业需要配置一个高端的计算实例。比如,在r7g.2xlarge实例上部署一个一千万向量的数据集,就算你根本没查询多少下,这台机器每月也得花300多美元。
如果把这套数据放到 S3 Vector上,即便每月有25万次查询,还更新了一半的向量数据,成本也才刚刚超过30美元。如果某段时间查询特别多,你也可以把这个向量索引暂时迁移到更传统的向量数据库OpenSearch。
AWS并非唯一一家为对象存储添加矢量支持的厂商。本月初,Cloudian使用Milvus数据库扩展了其HyperStore对象存储,增加了矢量数据库支持。看来对象存储支持向量数据也是大势所趋啊。