
原创 :芯风威
在AI 大模型和数据洪流时代,存储系统成为突破性能瓶颈的关键环节。Solidigm 推出的面向数据中心,高TCO 的 QLC NVMe SSD —— D5 系列产品,以惊人的容量和高顺序读取性能,为大规模AI 存储集群带来了全新可能。
芯风威(NewFW Technology)围绕 DeepSeek 3FS 分布式文件系统实战,重点测试了 D5-P5336 61.44TB 在以下AI 训推文件系统使用场景下的针对冷数据性能:
IO 吞吐极限性能(顺序读取)
AI 推理缓存负载能力(KVCache 测试)
测试环境概览
Meta Server:128 核CPU,2TB 内存
Storage Server(2 台):64 核CPU,1TB 内存,Solidigm D5-P5336 61.44TB NVMe SSD 16 盘位置
Client 节点(1 台):128 核CPU,2TB 内存
网络连接:全部节点通过基于 RDMA 高速互联(400G)
为什么QLC 依然能胜任AI 负载?
本次实战主要聚焦在顺序读取和高频缓存访问,充分发挥了QLC 的优势。
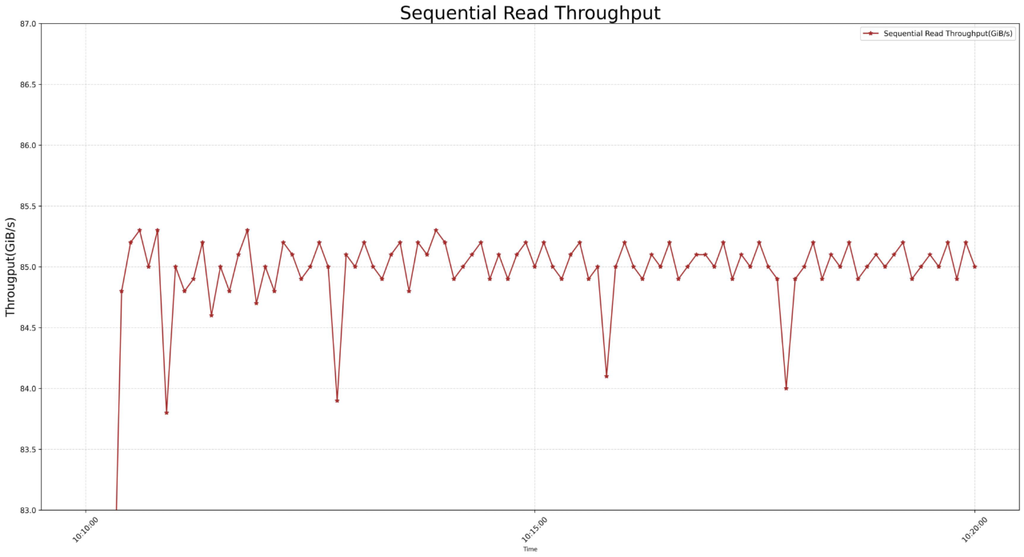
顺序读取测试:海量并发下的极速响应
在顺序读取测试中,客户端发起大文件连续读操作。实测结果令人惊艳:
单台Storage Server 聚合读取吞吐量接近 85GB/s通过RDMA 网络对外提供稳定 43GB/s 的顺序读取性能(受限于网络)
双Storage Server 系统整体读取吞吐量逼近 120GB/s按DeepSeek 官方 3FS 数据对比,在 180 台全闪存储的情况下,聚合读取吞吐量可达 10.5TB/s (1.6 倍左右)。但是从整体容量来计算,整体容量为 DeepSeek 官方配置的 4.36 倍。
且读延迟稳定,99%分位延迟保持在微秒级。
如此表现,在DeepSeek 3FS 这样的分布式AI 系统中,意味着更快的数据加载速度,更少的I/O 等待瓶颈。
在 AI 训推过程中,尤其是在处理如医疗影像、高清图片、视频等大型数据时,极高的顺序读取带宽配合高吞吐量的网络可以确保数据的海量吞吐,确保GPU 等AI 芯片性能得到充分利用。
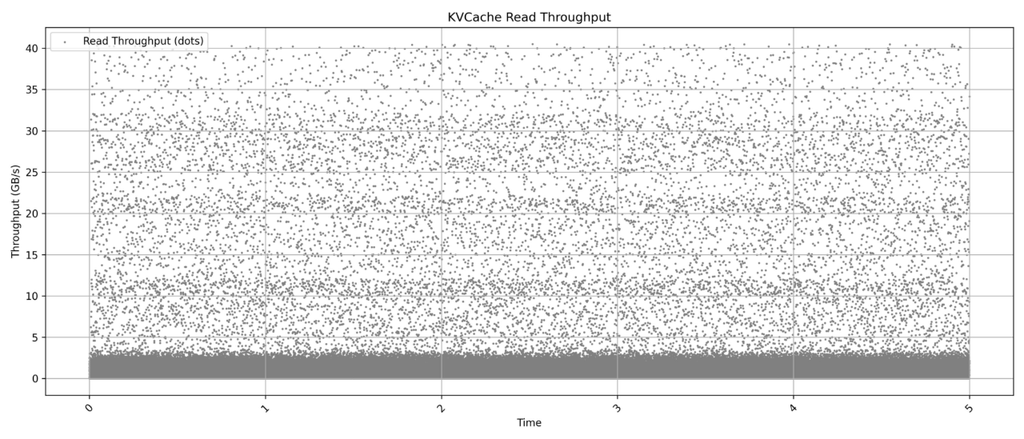
KVCache 负载测试:支撑高频访问,稳定超低延迟
针对当前流行的大规模推理业务,我们还进行了大集群下KVCache 负载模拟。
测试显示:在百万级请求QPS 下,SSD 能稳定提供单次读取延迟小于 100 微秒的表现顺序读取缓存页命中率高,带宽使用高效,没有明显抖动为AI 推理系统大幅降低了整体延迟。注:受限于集群节点数量,图表显示内容为多轮测试数据合集。
AI 在实时推理环节,稳定以及极小的延迟是大模型快速检索数据进行预测的基础。
TCO 优势分析:D5-P5336 让AI 集群更具规模效益
在大规模服务器集群中,存储设备的TCO(整体拥有成本)至关重要。D5-P5336 在这方面表现非常突出:
1,单盘超大容量,节省服务器与机架空间单盘可达 61.44TB 及 122.88TB 容量,同TLC SSD JBOF配置相比节省高达4倍的存储占用空间,同 HDD JBOD 相比节省高达8倍的存储占用空间。相同存储需求下,服务器数量将大幅减少全部采用QLC存储的服务器数量比采用HDD+TLC的数量将大幅减少
2,更优价格,每TB 成本更低QLC NAND 架构大幅降低单位成本
3,合理耐久度设计官方额定 0.6 DWPD在推理缓存、顺序读取负载下,完全满足企业级生命周期要求
综合来看,使用D5-P5336 可以让每PB 存储整体TCO 降低超过 35%,在超大规模部署中性价比优势巨大。
PCIe 5.0 的前景展望:
性能想象空间巨大目前D5-P5336 采用的是 PCIe 4.0 接口,即便如此已达到惊人的读取带宽。展望未来,随着PCIe 5.0 大容量QLC SSD 普及:
单盘理论带宽将翻倍增长
整体吞吐瓶颈将进一步被突破
QLC 优势会被进一步放大,特别是在超大模型推理场景
可以预见,基于PCIe 5.0 的新一代D5 系列产品,将成为新一轮AI 基础设施升级的重要力量。
总结
QLC 不只是性价比高,更能在合理场景下发挥出色性能:
Solidigm D5 系列顺序读取吞吐接近线性扩展;
DeepSeek 3FS 环境下验证了高可用与低延迟能力;
超大容量带来的TCO 优势,让AI 集群部署更具规模效益;
随着人工智能的发展和技术突破,存储性能将迎来新爆发。
Solidigm D5 服务器系列NVME SSD 硬盘,不只是容量革命,更是下一代AI 基础设施的中坚力量!







