
在存储系统的竞技场上,焱融科技是绝对的性能跑车。凭借在AI训练与推理场景中的领先技术优势,公司实现了高速发展。根据IDC SDS全闪市场报告,焱融科技作为国内全闪存储一体机市场排名第四的厂商,在2024年至2025年期间,其AI训练及推理场景的市场份额大幅提升,实现了业绩的强劲增长。

在2025数据存储产业大会上,与焱融科技CTO张文涛的一番对话,让我发现这家以极致性能著称的存储公司,并没有迷失在百模大战的训练热潮中。
相反,他们正在冷静思考AI存储的下一个机遇:当AI技术的焦点从训练走向推理,当AI从工具进化为智能体,存储系统该如何进化?
AI训练市场的赢家
焱融科技成立于2016年,最初主攻HPC领域,2018年开始进军泛AI行业,定位是专业的AI存储供应商。现阶段的AI训练对存储的性能要求很高,需要高性能存储来快速地给GPU投喂数据,而焱融最不缺的就是性能。
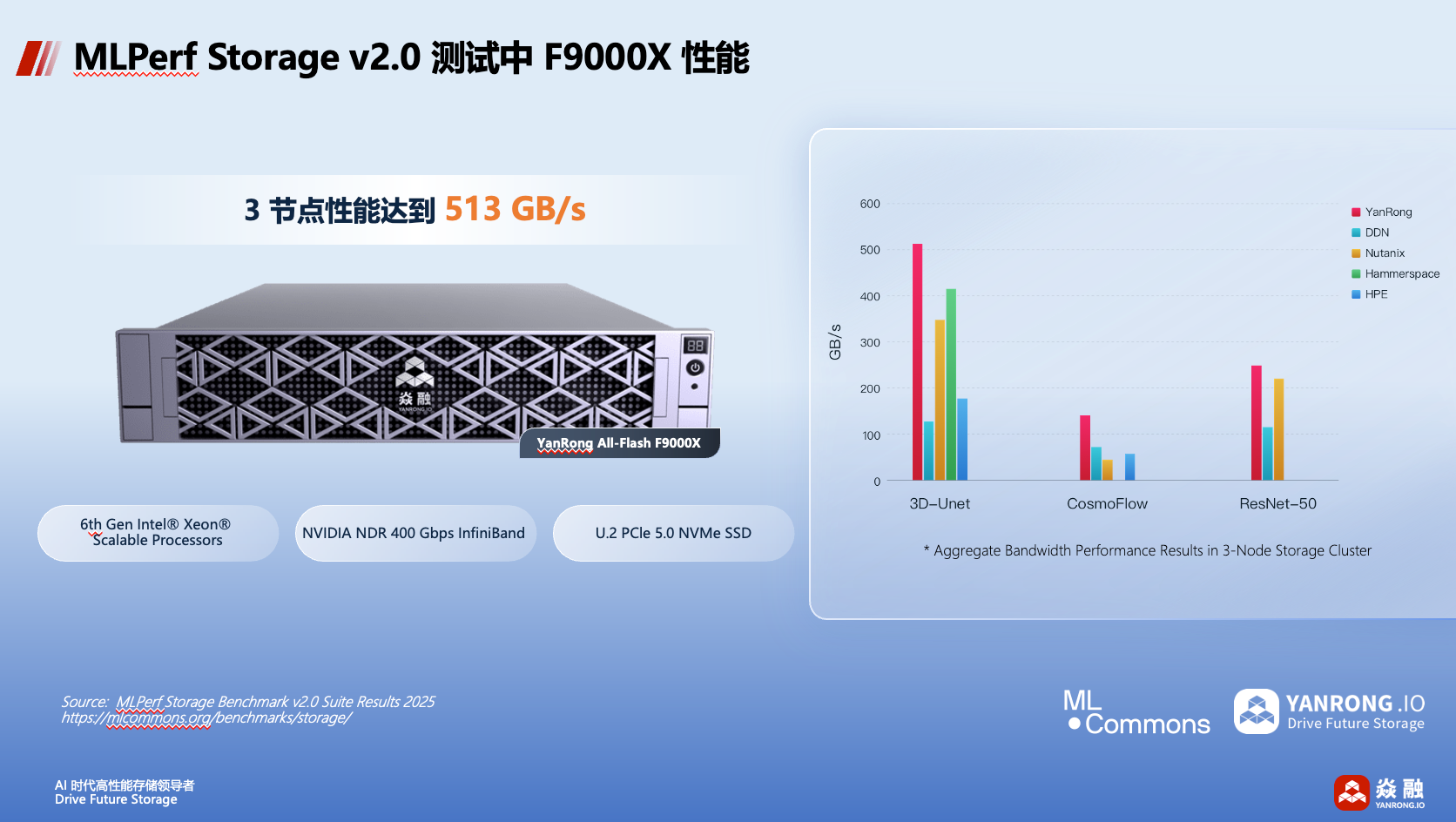
焱融的产品性能非常出色。在MLPerf Storage v2.0中,由3个节点组成的焱融全闪存F9000X集群在UNet3D测试集中创造了新的全球性能记录,在通用硬件上实现了513GB/s的超高带宽。
”三节点513GB/s的超高带宽其实是一个峰值性能,是MLPerf训练场景下的基准测试性能。对于多数采用三节点F9000X的用户来说,用户最少也可以达到480GB/s的性能表现。“张文涛介绍说。
据了解,焱融服务于做大模型、从事智能驾驶以及私募量化等行业的用户。目前,国内部分还在预训练大模型的企业当中,有一部分也是焱融的用户。一些做智能驾驶以及私募量化的企业也会训练一些模型。
张文涛介绍称,一些制造业企业会用AI来解决各种智能化问题。为此,就需要直接训练大模型,或者基于预训练的大模型做蒸馏、量化、微调等操作,这些轻量级的训练的频次很高,这也是焱融能在训练市场斩获颇丰的主要原因。
长远来看,推理将是星辰大海
“虽然目前AI市场的关注焦点在训练,但训练市场终究是寡头市场,”张文涛给出了一个非常冷静的判断。虽然焱融目前的业绩多来训练需求,但他看得更远:虽然百模大战打得火热,但最终继续训练大模型的巨头屈指可数。
真正的机会在哪里?在推理,在千行百业。张文涛认为,目前的AI推理市场正处于爆发的前夜,大家都在等待一个像微信、支付宝那样能彻底改变生活方式、提升生产力的杀手级应用。到那时,推理对存储的并发与响应需求将呈指数级增长。
当然,推理市场的爆发依赖于像DeepSeek这样的优秀模型,存储更像是大模型的记忆系统,碰到任何新的东西先负责记下来,然后学习和迭代内化到AI模型中,长远来看,存储对AI的发展是至关重要的。
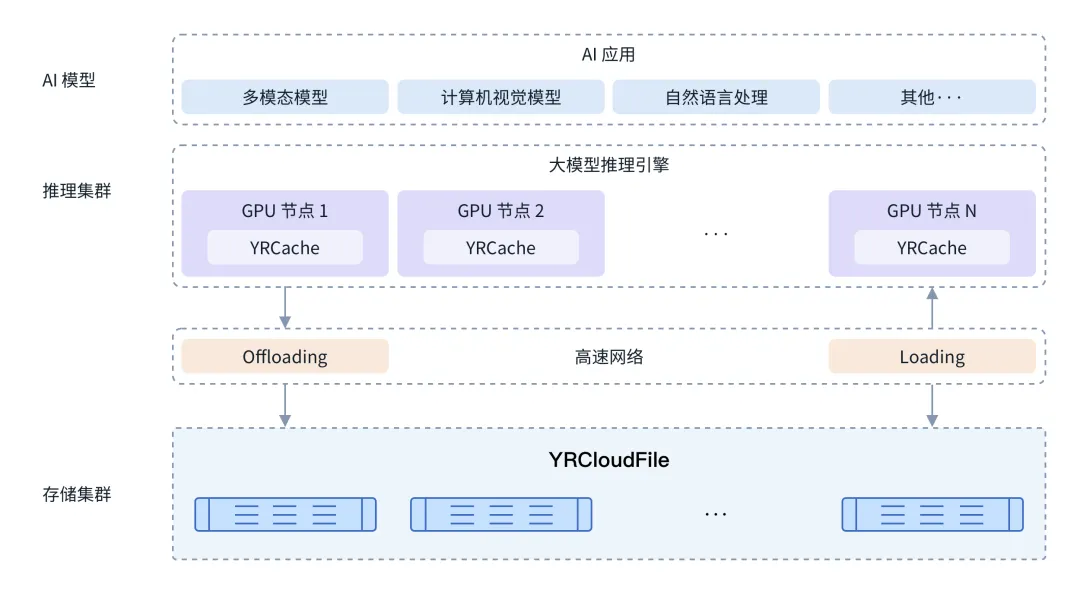
作为新一代大模型存储系统,焱融YRCloudFile除了擅长训练场景,也面向推理场景做了深度优化。2025年,焱融发布国内首个大模型推理加速方案——焱融YRCache,凭借“以存代算”为核心理念,缓解GPU显存不足的挑战并提高了推理的效率。
随着AI的发展,推理的负载会越来越多。所以有观点认为,在确保推理性能的前提下,把推理效率做到极致,把推理成本压到最低才是决定AI成败的关键。而焱融YRCache用存储创新克服推理场景的关键挑战,重塑了AI推理的成本结构。
2025数据存储产业大会正式揭晓了“2025 年度数据存储典型实践案例”名单,焱融 YRCache:面向大模型推理场景的高性能存储加速方案”成功入选,YRCache 在技术突破、落地成效与产业价值方面的高度认可。
2025年被视为是智能体元年,张文涛认为,如果智能体想持续迭代学习,还有很多工作要做,比如给智能体打造一个配套的记忆系统。在未来,焱融还是希望从存储入手,更好地支撑AI技术的发展与应用。
全域数据的“大管家”——DataInsight
焱融的存储系统性能很出色,但是对企业来说,除了训练和推理需要的高性能存储,还需要获取更多的数据喂给 AI。为了解决这一问题,焱融在2025年推出了DataInsight,它用来激活海量历史数据。
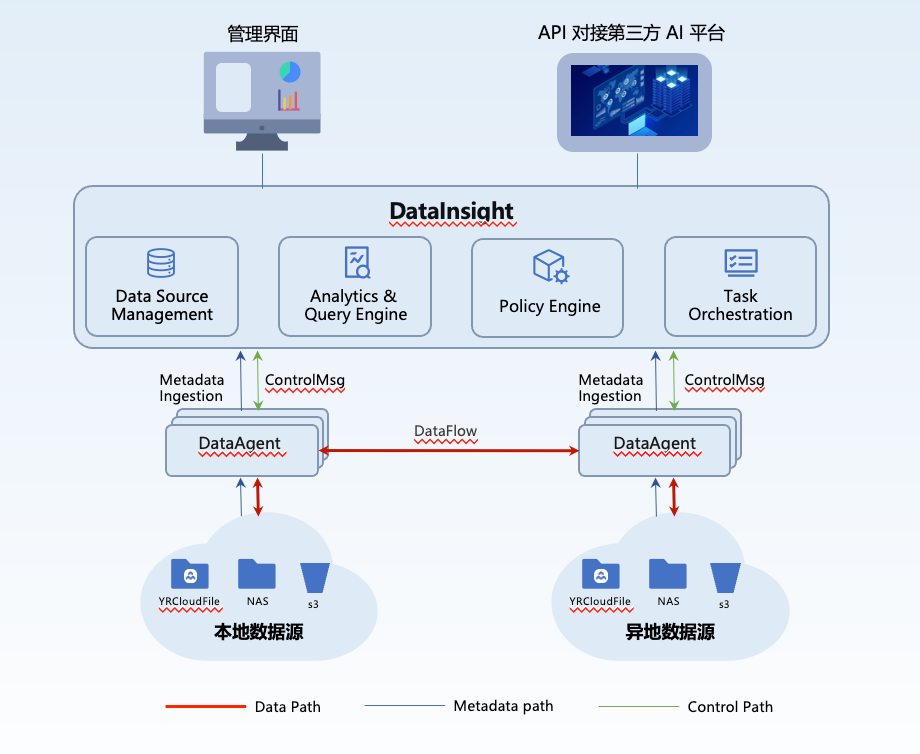
真实的企业环境中,大量旧数据往往被分散存放在不同系统中,DataInsight能对接海量异构数据源,提取元数据,形成统一视图,为用户提供快速检索能力。有意思的是,即使是百亿级的元数据信息也能秒级检索,焱融的DataInsight同样很快。
比如,当用户要找2024年各个部门的数据,DataInsight一次快速性检索出来后,按需把这些数据放到高性能存储里,供前端业务做数据处理,整理成高质量数据后,再给到模型训练。
除此之外,DataInsight还可以用来进行数据治理。比如,当用户检索发现了完全无价值的数据,可以直接删除释放存储空间。或者当发现长期未访问但可能仍有用的数据,可以自动归档到性价比更高的存储介质。
本文来源于DOIT传媒,文章内容仅供参考,不构成投资建议。


评论列表