
生成式AI技术时代,算力短缺和能源不足是两个重大挑战,而亚马逊云科技作为全球最大的供应商,正在凭借自研AI芯片,构建更高效的AI硬件技术方案,在应对两大挑战的同时,也在悄然改变AI芯片产业的市场格局。
2025年12月2日,亚马逊云科技在拉斯维加斯举办re:Invent大会。在生成式AI极速狂飙的时代背景下,亚马逊云科技宣布AI硬件上的全新突破,正式发布基于研芯片Trainium3和基于该芯片的Trn3 UltraServers服务器。
深度绑定:做英伟达GPU的“最佳栖息地”

在介绍Trn3 UltraServers之前,CEO Matt Garman首先介绍了P6e-GB300实例,它的硬件是基于英伟达GB300-NVL72超级芯片构建的超节点服务器UltraServers。亚马逊云科技不只是把英伟达的GB300单纯引入,而是会一起做深度优化。
这种优化,让运行在亚马逊云科技上的GPU获得了极佳的可靠性和可用性,亚马逊云科技自豪地宣称,这里就是运行英伟达显卡最好的地方。此前,在2025年7月,双方联合打造了基于GB200的P6e-GB200 UltraServers。
亚马逊云科技与英伟达的合作超过了15年之久,两家合作非常紧密,前不久官宣的Project Ceiba,是双方构建的给英伟达做AI研究和开发的AI超算平台。这可以看出英伟达对亚马逊云科技的全面认可。
亚马逊云科技不久前官宣了与OpenAI的合作,OpenAI选用的UltraServers用的是英伟达的方案,这为亚马逊云科技带来了380亿美元的大额订单。这是全球最受关注的AI大模型公司对亚马逊云的认可。
UltraServers是2024年发布的重磅硬件产品,它采用了NeuronLink高速互联技术,Nitro系统等一系列创新硬件技术。在第一阶段,UltraServers基于自家Trainium芯片打造了EC2 Trn2 实例,而后才有了基于英伟达方案的EC2 P6e-GB200。
生态突围:百万芯片落地,Trainium芯片在推理场景大面积应用

在AI加速硬件领域,亚马逊云科技采用了双引擎策略,既要全力拥抱英伟达,也要死磕自研芯片。当然,英伟达在整个AI业界的呼声非常高,亚马逊自研的芯片真的会有很多人去用?
答案是肯定,目前Trainium在推理场景用的很多。
Matt在发布会上宣布,绝大部分Amazon Bedrock上的用户都在用Trainium做推理,很多用户在无意间就用上了Trainium芯片。这就跟几年前,很多用户无意间就用上了Graviton Arm芯片如出一辙,这种硬件生态上的突破,或许只有在云上才能成功。
Amazon Bedrock是亚马逊云科技的模型托管平台,用户通过API调用模型进行推理,Bedrock上的Claude用户众多,所有Cluade模型的用户都在用Trainium。在Claude等模型的支持下,亚马逊云科技已经部署了100多万个Trainium芯片。
去年re:Invent上,亚马逊云科技与Anthropic高调宣布Project Rainier,该项目涉及30个数据中心,耗费1.1 GW(吉瓦)的电力,采用了50万块的Trainium2芯片。
有意思的是,这些芯片通过EFA网络连接跨服务器、跨机架、跨集群甚至跨数据中心的Trainium处理器,然后组成一台超级电脑,这台电脑的任务就是帮助Anthropic训练下一代Claude模型。
这是Trainium芯片找到的绝佳的客户案例,它正在努力证明,Trainium也可以用来训练世界顶级的AI模型。Trainium不只会用于推理,其初衷就是以较低成本,给用户提供生成式AI训练所需的高性能,下一阶段,其在训练场景的表现值得关注。
硬件革新:全新Trainium 3与UltraServers的性能跃迁

此外,亚马逊云科技还正式发布了第三代AI加速器Trainium 3,它采用了先进的3nm工艺,能效相较于上代提升了40%,算力直接翻倍,它的出现就是为了继续提升大规模生成式AI工作负载的性价比。

伴随Trainium 3发布的,还有搭载Trainium 3的新一代Trn3 UltraServers超节点服务器,相较于上代产品,计算能力提高了4.4倍,带宽增长了3.9倍,每兆瓦生成的Token数量是Trn2 UlraServers的五倍。

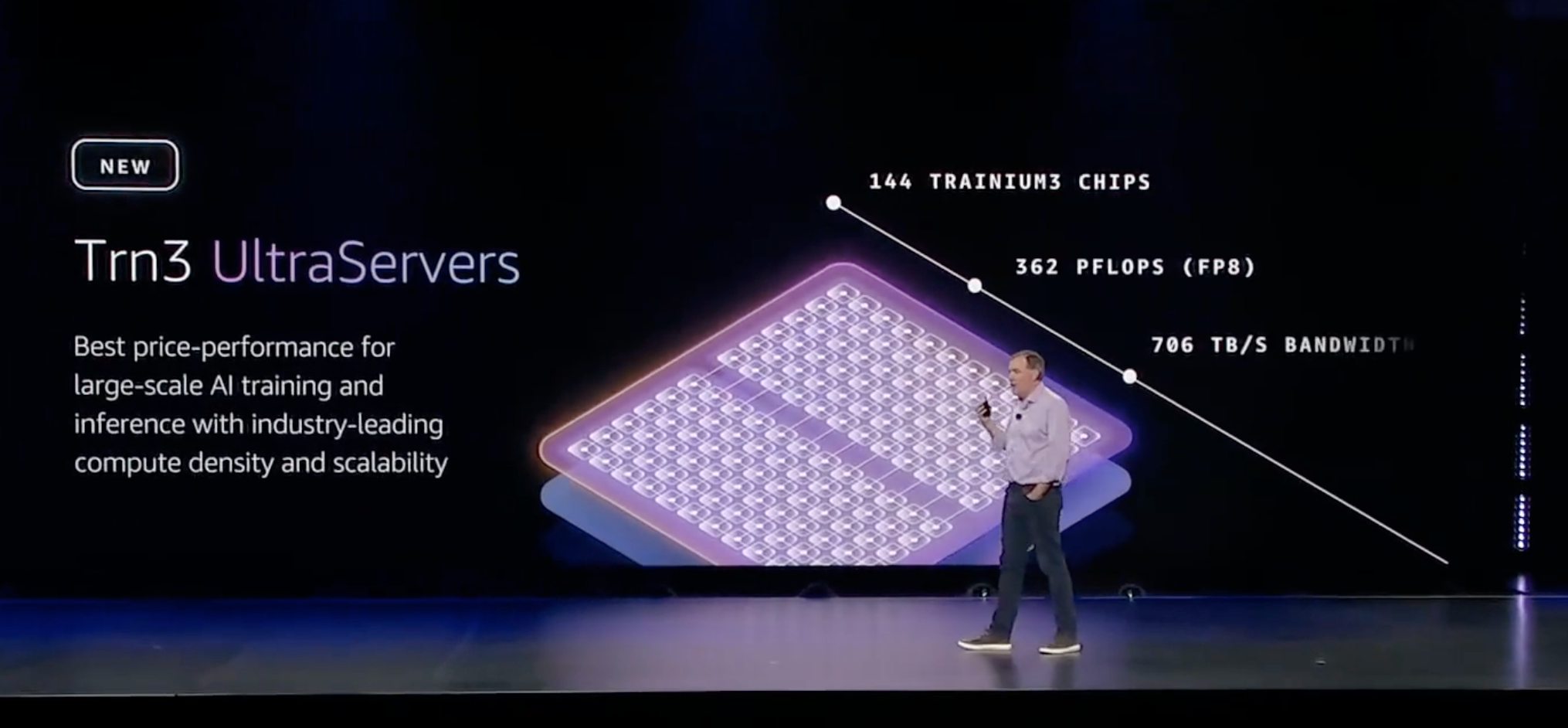
这台Trn3 UltraServers中有144块Trainium 3芯片,362PFlops的FP8算力,以及706TB/s的带宽。上一代Trn2 UltraServers只有64块Trainium 2芯片,提供83.2的FP8算力,6TB HBM和184TB的内存带宽,这次提升非常大。

上图是Trn3 UltraServer的计算节点,这是一台1U液冷服务器,它搭配了4块Trainium3芯片,保守估计大概也有2千瓦的功耗,液冷冷板覆盖Trainium3和CPU节点,Nitro部分则是继续使用了传统风冷方案。
剑指未来:Trainium 4蓄势待发,ASIC路线正在崛起

这还没有完,为了让用户进一步增加对Trainium的信心,Matt直接宣布Trainium 4的消息。相比Trainium 3,Trainium 4的FP4性能提升了6倍,内存带宽提升4倍,HBM容量增加2倍,在性能增强的同时降低能耗。
Trainium是亚马逊云科技基于ASIC打造的AI加速器,最近谷歌的ASIC加速器芯片——TPU也受到了很多关注,两大巨头纷纷加码ASIC加速器,相信会让整个市场对ASIC有更积极的看法。
本文来源于DOIT传媒,文章内容仅供参考,不构成投资建议。


评论列表