
导读
前些天有外媒曝出马克・扎克伯格正在组建一个名为「超级智能团队」的专家团队,以实现通用人工智能。就在6月12日,Meta又有新的动作,推出基于视频训练的世界模型V-JEPA 2(全称 Video Joint Embedding Predictive Architecture 2)。其能够实现最先进的环境理解与预测能力,并在新环境中完成零样本规划与机器人控制。这次,Meta首席AI科学家Yann LeCun亲自出镜,介绍世界模型与其他AI模型的不同。
他说,世界模型是一种现实的抽象数字孪生,AI可以参考它来理解世界并预测其行为的后果。例如,它可以用于帮助视障人士的辅助技术、在混合现实中为复杂任务提供指导、使教育更加个性化,甚至可以理解代码对程序状态和外部世界的影响。此外,世界模型对于自动驾驶汽车和机器人等自主系统至关重要,它将开启机器人技术的新纪元,使现实世界中的AI智能体能够在不需要大量机器人训练数据的情况下帮助完成家务和体力任务。
文字编辑|宋雨涵
1
什么是世界模型
V-JEPA 2
所谓世界模型,就是专门来帮助AI智能体理解周围世界,预测周遭状况如何发展,并最终通过规划自身行动来完成目标的模型。这种能力在人类身上体现为直觉与预判:预测世界将如何回应我们的行为(或他人的行为),尤其是在规划行动以及判断如何应对新情况时。世界模型已然成为AI领域聚焦的目标。李飞飞的World Labs、谷歌的DeepMind都在开发类似的世界模型。英伟达也开发了世界模型Comos,而Meta表示,V-JEPA 2的运行速度是英伟达Cosmos模型的30倍。
下面是 V-JEPA 2 的一些性能指标:
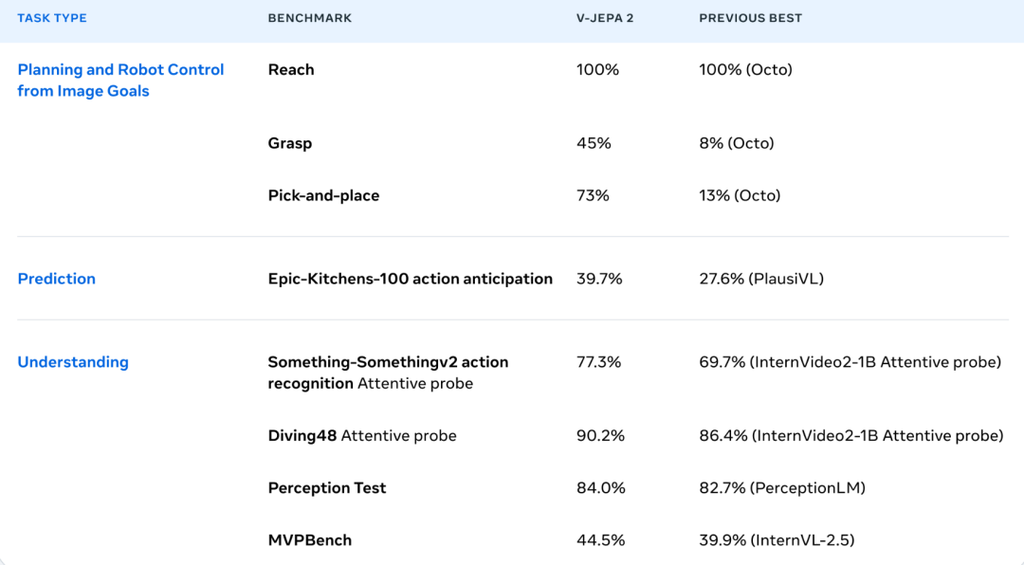
V-JEPA 2模型参数规模达12亿,它基于联合嵌入预测架构(JEPA)搭建而成。此前,Meta已经通过相关实践验证,JEPA架构在处理图像、3D点云等多种模态的数据时,展现出了卓越的性能。
此次全新发布的V-JEPA 2,是在去年推出的首个基于视频训练的模型VJEPA基础上进行升级的。升级后的V-JEPA 2在动作预测以及世界建模能力方面得到了进一步提升,这使得机器人借助与陌生物体和环境的交互,能够更顺利地完成各项任务。
V-JEPA 2 技术解析
此次发布的V-JEPA 2模型,是在去年首个基于视频训练的V-JEPA模型基础上升级而来。它进一步增强了动作预测和世界建模能力,让机器人能够通过与陌生物体及环境交互来完成任务。V-JEPA 2与语言建模相结合,可提供出色的运动理解能力和领先的视觉推理能力,还能预测世界的发展态势。
在训练方式上,Meta采用基于视频的自监督学习方法训练V-JEPA 2,无需额外人工注释即可在视频上开展训练。该模型拥有12亿参数,主要基于视频进行训练,运用自监督学习策略。它包含编码器和预测器两个核心组件:编码器接收原始视频并输出嵌入,以捕捉观察世界状态的有用语义信息;预测器则接收视频嵌入和关于预测内容的额外上下文,输出预测的嵌入。
V-JEPA 2的训练过程分为两个阶段。在第一个预训练阶段,研究团队使用了超过100万小时的视频和100万张图像。这些丰富的视觉数据助力模型学习了大量关于世界运行的知识,包括人们与物体的互动方式、物体在环境中的运动规律,以及物体间的相互作用。仅在预训练阶段后,模型就展现出了与理解和预测相关的关键能力。例如,在冻结编码器和预测器特征的基础上训练注意力读出模型后,V-JEPA 2在Epic-Kitchens-100动作预测任务中创造了新的最高纪录。该任务要求根据以自我为中心的视频预测未来1秒将执行的动作(由名词和动词组成)。
在训练的第二阶段,Meta专注于利用机器人数据提升模型的规划能力。他们向预测器提供动作信息,将这些数据整合到JEPA训练流程中。使用额外数据训练后,预测器学会了在预测时考虑具体动作,并可用于控制。令人惊喜的是,这一阶段并不需要大量机器人数据。Meta的技术报告显示,仅使用62小时的机器人数据进行训练,就足以生成一个可用于规划和控制的模型。
除了发布模型,Meta同时推出了三个全新基准测试,为物理推理能力评估设立新标准:
1、IntPhys 2:用于测试模型在复杂合成环境中的直观物理理解能力(Benchmarking Intuitive Physics Understanding In Complex Synthetic Environments)。
2、一种基于最小视频对的、感知捷径的物理理解视频问答基准测试(A Shortcut-aware Video-QA Benchmark for Physical Understanding via Minimal Video Pairs)。
3、CausalVQA:面向视频模型的物理基础因果推理基准测试(A Physically Grounded Causal Reasoning Benchmark for Video Models)。
2
预测革命
通往AGI的岔路口
V-JEPA的发布远不止技术迭代,它代表着智能进化的分水岭:
- 抛弃强监督依赖:长久以来,“标注为王”的认知框架在机器学习领域占据主导地位,但这一模式正面临挑战。研究者开始重新思考,机器是否可以不依赖大量的标注数据,仅通过观察世界来习得智能规律。这种转变意味着,机器学习将不再局限于从预先标注好的数据中提取模式,而是尝试像人类婴儿一样,通过与环境的自然交互来构建对世界的认知。
- 超越模式识别:当前,AI在模式识别任务上取得了显著进展,但仅仅依赖“数据相似性匹配”来理解世界是远远不够的。高阶智能的核心在于学会“预测未知”,即基于已有的知识和经验,对未来可能发生的情况进行合理的推测。为了实现这一目标,构建物理常识模型成为关键挑战。这要求AI系统不仅要能够识别数据中的模式,还要能够理解这些模式背后的物理规律和因果关系,从而实现对世界的更深入理解。
- 效率的重新定义:在数据需求方面,V-JEPA模型的出现为机器学习领域带来了新的希望。相较于依赖监督学习的技术路线,V-JEPA模型在数据需求上实现了巨大的压缩。据称,其训练所用数据可比对标模型少16倍。这一突破对于解决大模型的高能耗问题具有深远意义,因为它降低了数据收集和处理的成本,同时提高了模型的训练效率。
- 具身智能的基石:要使机器人能够真正与现实世界进行交互并做出判断,其脑中必然需要一套对物理规律的内部认知模型。LeCun认为,JEPA模型正是为未来具身智能体的核心能力铺路。具身智能强调AI系统通过物理或虚拟身体与环境交互,通过感知、行动和反馈来学习和执行任务的能力。JEPA模型通过其独特的架构和训练方法,为机器人构建了一套对物理世界的内部认知模型,使其能够更好地理解和适应现实世界中的复杂情况。
由此可见:
Meta路线:以预测驱动的自监督世界模型为核心,通过物理常识理解实现类人推理
OpenAI/英伟达路线:依赖海量标注数据的生成式模型,强调统计匹配而非因果建模
这一分歧触及AI哲学的本源问题:智能究竟是模式的复制,还是知识的创建?当生成模型追求像素级的逼真复刻时,预测模型已在建构抽象层面的物理规律认知。LeCun断言:“五年内将无人使用纯LLM路线。”随着多模态JEPA架构扩展和分层预测框架落地,从静态数据拟合走向动态世界理解的认知革命已然启动。
AGI的终极形态,正在从“回答已知”转向“预测未知”,而这正是人类智能的本质内核。预测学习开启的不仅是技术突破,更是对智能本身的重构——机器终将在对世界的想象与推演中,走向真正的理解。
战略布局,Meta的AI生态野心
此次发布恰逢Meta在AI领域的密集布局。昨日有消息曝出,Meta豪掷148亿美元收购Scale AI 49%股份,同时成立新AI实验室并招揽28岁华裔天才少年。
这一系列动作明确指向构建完整AI生态的战略目标。LeCun亲自站台讲解技术愿景,颇有为Meta招兵买马“打广告”的意味。
Meta的开源策略也在此次发布中延续。从Llama系列大语言模型到如今的V-JEPA 2,Meta坚持通过开源扩大影响力,同时吸引全球开发者共建生态。
扎克伯格的超级智能助手愿景正通过这些技术逐步落地。在印度农村的试验中,农民已能通过智能眼镜识别作物病害、查询天气并判断收割时机,使用本地语言与AI交互。
结语:
关于世界模型,Meta后续将开展多方向的深度探索。
当前,V-JEPA 2仅具备在单一时间尺度上进行学习和预测的能力,然而在现实场景中,众多任务都要求跨越多个时间尺度进行规划。Meta后续会把研究重点放在分层JEPA模型上,力求让该模型能够在不同的时间和空间尺度下开展学习、推理以及规划工作。
另外,开发多模态JEPA模型也是Meta的一个重要研究方向。多模态JEPA模型不仅能借助视觉进行预测,还能整合听觉、触觉等多种感知能力,从而实现对世界更全面、深入的理解。







