2025年年初开始爆火的DeepSeek-R1为业界带来了免费开源的超强大语言模型,在全民争相部署使用DeepSeek的过程中,涌现出了很多降低大模型使用成本的技术。这其中,最吸引人的当属KVCache以存代算技术。
KVCache 缓存技术已成为提升推理效率的业界共识,但要真正发挥其价值,需要存储系统具备强大的支持能力。焱融科技利用自研高性能分布式文件系统 YRCloudFile,搭配来自Solidigm的高性能存储设备,打造了YRCloudFile KVCache推理加速方案,显著提升推理效率和模型推理性价比。
YRCloudFile KVCache——一种能显著降低成本并提高系统并发性能的神奇魔法
在专业 AI 存储厂商焱融科技副总裁黎俊鸿看来,KVCache 技术已成为 AI 推理系统的标配,包括 DeepSeek 在内的众多主流模型均已支持 KVCache 加速机制。目前,已有很多企业用户在使用焱融 YRCloudFile KVCache方案,以有效提升推理性能与系统响应速度。
到底什么是KVCache呢?简单说,当我们与DeepSeek-R1进行多轮对话时,模型为了记住刚才跟你聊了什么,就需要把这些数据缓存下来,缓存的数据就是KVCache。原本这些数据是要放在显卡的GPU显存里的,但显存不仅容量小,而且贵的离谱。
黎俊鸿提到,一个8张A100组成的系统在接受推理请求的过程中,会不断累积KVCache,一小时内产生的KVCache容量就可高达130TB 以上。而单张高端显卡通常仅配备几十至上百 GB 的显存,相较之下,显存容量远远无法满足如此规模的缓存需求
一种解决办法是将 KVCache 从GPU显存迁移至主机 DRAM,以缓解显存压力,但 DRAM 容量同样有限,且成本较高。更优的解决路径是将 KVCache 存放至高性能存储系统中。相比于显存,存储系统具有更高的容量密度和更低的单位成本,能够有效降低大模型推理过程中的资源使用成本,从而提升整体性价比。
将数据从GPU显存迁移到存储系统后,如果后续的计算过程中用到了存储系统中的KVCache数据,再将数据从存储系统中重新加载到GPU显存当中,从而避免了把以前计算过的数据再计算一遍,降低整个推理的延时和成本。
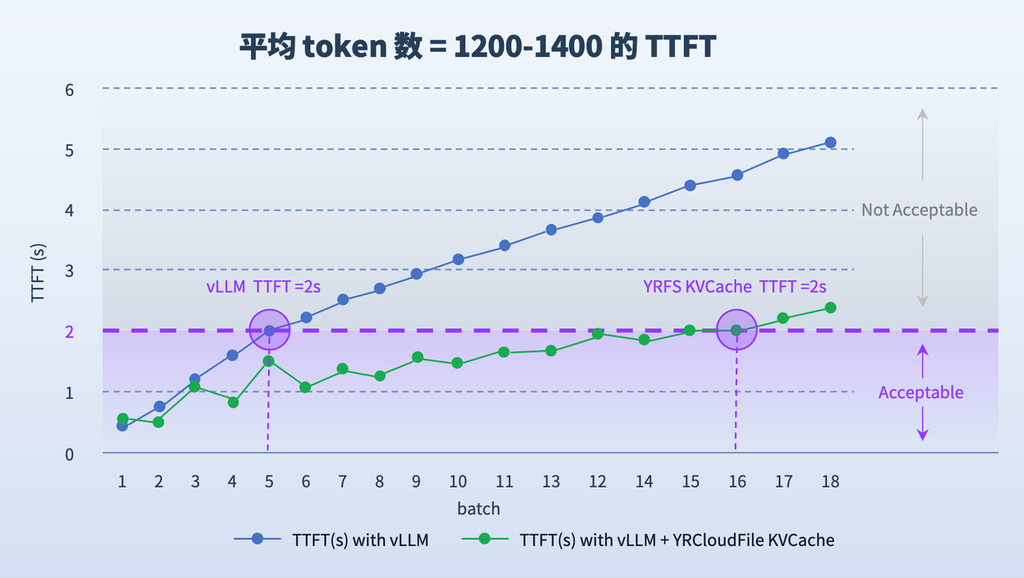
除了显著降低推理成本,焱融 YRCloudFile KVCache技术还大幅提升了系统的并发处理能力。从上图实测的数据可以看出,在没有使用YRCloudFile KVCache时,为保证首个Token在2秒内返回,系统最多只能支持5个并发请求。而采用焱融YRCloudFile KVCache方案后,并发能力提升至16个,整体处理效率提升了 3 倍以上。
这一技术突破充分凸显了存储系统在 AI 推理中的核心价值。在更普遍的层面上,存储系统在数据准备、模型训练、模型推理等场景中都发挥着非常关键的作用,正在从传统意义上的存放数据的仓库,转变为支撑AI发展的“关键引擎”。
国产存储之光:性能至上,焱融打造高性能存储的新标杆
焱融科技是一家成立于2016年的存储公司,核心团队成员主要来自IBM、华为、金山云、阿里云等科技公司,研发实力充足。在2024年IDC全闪软件定义存储出货量排行当中,荣膺中国第四,产品、服务以及市场表现都获得了认可。
焱融科技专注于高性能文件存储,曾在存储系统性能评测榜单IO500中跻身前六。2024年,在国际权威 AI 存储性能MLPerf Storage基准测试中,凭借极致性能斩获多项世界第一,代表了中国文件存储技术的顶尖水平。
可以说,卓越的性能是焱融科技高性能分布式文件存储的核心优势之一。正因如此,焱融科技高度重视与高性能存储设备厂商 Solidigm 的合作。在 2022 年推出的全闪分布式存储一体机 F8000X 中,焱融科技采用了22 块 Solidigm PCIe Gen4 NVMe 固态硬盘,充分发挥硬件与自研分布式文件系统的协同优势,进一步提升了整体系统的读写性能与业务响应效率。
2024年,焱融科技推出了新一代全闪分布式存储一体机 F9000X,搭载 Solidigm D7-PS1010 PCIe 5.0 NVMe SSD,并集成了 NVIDIA 400Gb InfiniBand 高速网络,全面释放带宽与 IOPS 性能潜力,为高性能 AI 计算场景提供强劲支撑。
在 AI 应用的全生命周期中,包括数据采集、预处理、模型训练、模型验证、模型推理及数据归档,焱融科技强调“一站式存储平台”建设,贯穿 AI 数据处理全流程,避免各阶段频繁迁移数据带来的性能损耗和管理负担。
焱融科技副总裁黎俊鸿表示,当前 AI 存储面临四大核心挑战:一是通过智能分层降低整体数据存储成本;二是实现在线业务不中断的平滑扩容;三是优化海量小文件的读写性能;四是应对带宽与 IOPS 的高强度需求,尤其是在 KVCache 场景中,存储系统需快速响应 GPU 与存储间 KV 数据的读写请求,直接影响推理效率和系统整体性能表现。
焱融不仅提供软硬件一体化的全闪产品解决方案,更自主研发了高性能分布式文件系统 YRCloudFile,具备无损扩容、冷热数据自动分层、智能数据加载、海量小文件优化等功能。目前,该方案已成功应用于智谱 AI、知乎、以及多家头部车企与运营商的智算中心,持续为客户 AI 业务的稳定运行和高效扩展提供坚实支撑。
与 Solidigm 深度合作,共同推动存储系统性能突破
自 2019 年起,焱融科技便与 Solidigm 建立稳定合作关系,携手经历了存储接口从 SATA 到 NVMe、从 PCIe 4.0 到 PCIe 5.0 的技术演进。无论是 2022 年推出的基于 PCIe 4.0 平台的全闪分布式一体机 F8000X,还是 2024 年发布的新一代 PCIe 5.0 平台产品 F9000X,焱融科技均选择 Solidigm 高性能 SSD 作为核心组件。
焱融科技副总裁黎俊鸿指出,作为一家专注高性能分布式并行存储系统的企业,焱融始终致力于为对数据访问性能要求极高的客户提供软硬件一体化解决方案,这也使其在产品选型时尤为重视性能表现,Solidigm 在该领域的技术优势正好与之高度契合。
双方合作不仅基于 Solidigm 在性能、可靠性和性价比方面的均衡表现,也得益于双方在技术支持和工程师文化层面的高度协同。Solidigm 持续提供专业技术支持,使双方在产品调优与项目落地中合作顺畅,持续推进产品性能优化。
焱融科技在软件栈持续迭代优化的同时,也通过搭配 Solidigm Gen5 SSD 与高速网络等关键组件,实现了 F9000X 性能的显著跃升。实测显示,仅三节点集群即可达到 480GB/s 带宽和最高 750 万 IOPS 的领先性能表现,充分满足智算中心、AI 模型训练和推理等高负载应用需求。
随着生成式 AI 技术的迅猛发展,焱融科技长期坚持的高性能战略正在显现战略价值。黎俊鸿强调,尽管业界普遍关注算力本身,但真正的性能瓶颈往往来自底层数据访问的限制。焱融科技通过软硬一体的技术积累,正帮助客户突破这一关键瓶颈,释放 AI 潜能。
在某算力运营商智算平台中,焱融追光全闪存储一体机F9000X用400Gb的InfiniBand网络对接了一个128节点GPU服务器,单存储集群就给客户提供了TB级别的读带宽和2000万以上的IOPS,稳稳支撑了头部自动驾驶客户的模型训练需求。
某家电制造企业使用焱融科技F8000X全闪文件存储系统,构建了匹配大规模GPU可计算集群的数据存储系统,解决了百亿级别小文件和大文件混合场景的数据访问挑战,用更强的数据访问性能,大幅提升了整体的训练效率。
国内某知名大模型开发商使用了内蒙千卡集群的资源,而该GPU集群的AI存储系统中使用了焱融科技F8000X存储系统,支撑前端千卡GPU集群。在这套系统的支持下,大大提升了模型迭代效率,还满足了该服务商对外提供算力租赁服务的需求。
结束语
KVCache技术为大模型应用带来了革命性的效率提升和成本优化。焱融科技凭借其卓越的高性能存储解决方案,特别是与Solidigm的深度合作,成功将KVCache的潜力发挥到极致。
焱融科技致力于打造超高性能存储系统,实践案例也充分证明,高性能存储已成为驱动AI发展的核心引擎,它不仅为各行业的AI创新提供了坚实的数据基础,也进一步印证了——存储,在 AI 时代的重要性不可忽视。