
希望在本地部署推理生成式AI大模型的人,应该都知道,显卡算力不是最重要的,显存才是。显存容量决定了模型能否推理起来更大参数的模型,决定了本地推理模型的智力水平,也决定了本地部署方案的能力创新空间。
截止到2026年初,主流游戏显卡显存仅为8G,但凡想要16、24G或者32G显存,或者使用大显存的专业显卡,都需要花上几倍甚至十多倍的成本。为了控制成本,有些朋友不得不冒着风险选择几年前的二手旧旗舰显卡。

或许是看到了这一痛点,英特尔带着一张有24G显存,售价5000多人民币的锐炫Pro B60专业显卡杀入市场,今天将开始在蓝戟、铭瑄渠道上市,结结实实的成了显存价格屠夫,为那些想以更低成本在本地部署推理模型的人(企业)带来了极具诱惑力的选择。
英特尔锐炫Pro B60用4万块就能提供192G的显存容量
当你的数据不能交出去,要满足数据主权、合规以及隐私要求;当你模型调用量会持续增长,害怕账单失控;当你基于模型运行稳定的业务,无法接受模型本身的变化时,你就需要本地部署大模型了。
首先,需要在DeepSeek、Qwen(通义千问)、Llama或者Mistral这样的大模型中做出选择,同时,要根据需求选择模型的参数大小。接下来,就需要配置硬件,在单机单卡、单机多卡,或者集群方案中做出选择。
集群方案投入大,技术架构复杂,只适合大型企业,对于更多个人用户以及众多中小企业而言,单机多卡的配置更常见。英特尔的Arc Pro B60就瞄准了这一市场——单台工作站插入1到8张B60显卡,约4万多人民币即可获得192GB的宝贵显存。
要知道,4万都不够买一块RTX PRO 5000(72G)的。如果要用英伟达显卡堆出192G显存,需要8块RTX PRO 4000(24G),大概花费10万,如果用8块RTX 5090(32G),也需要16万多,对比之下,英特尔简直是价格屠夫。
细心的朋友肯定注意到了单台工作站8张卡的说法,常见的工作站很难凑够8个PCIe x16插槽,如何放得下8张x16的显卡呢?

确实,常规的显卡都是一张显卡上只有一块显卡芯片,会占用一个PCIe x16的插槽。然而,Arc Pro B60采用的是PCIe x8的配置,铭瑄利用这一特性推出的双芯片版本,在一块PCB板上放有两个B60芯片和48G显存。
这样一来,一台台式机工作站中,仅占用4个PCIe x16的插槽就能放8块B60核心和192G显存了。相较于常规的8卡方案,这种方案节省了插槽和机箱空间。当然,用户选择单张显卡单颗芯片时,则可以按照PCIe数量来灵活配置B60的数量。
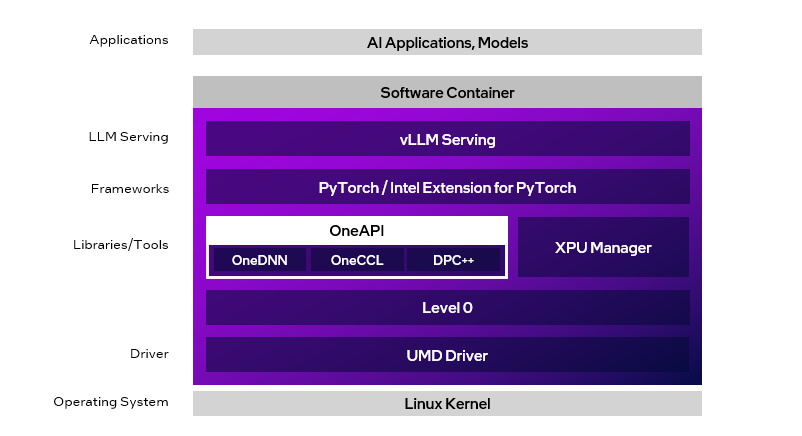
这就是英特尔推出的代号为Project Battlematrix的AI推理工作站解决方案,搭配英特尔至强工作站处理器和英特尔Arc Pro B60显卡,同时还有配套的Linux软件栈,不用担心软件兼容性问题,能以极低的成本,让企业和个人在本地安全地跑大模型。
锐炫Pro B60的大显存,能带来什么神奇效果?
肯定会有人好奇这种堆显卡方案的性能表现。我看到一张英特尔官方公布的性能测试图,图中是1,2,4张Arc Pro B60在推理Llama-3.1-8B-Instruct FP16模型时的性能。横轴表示并发数,纵轴表示每秒Token数,也就是性能参数。
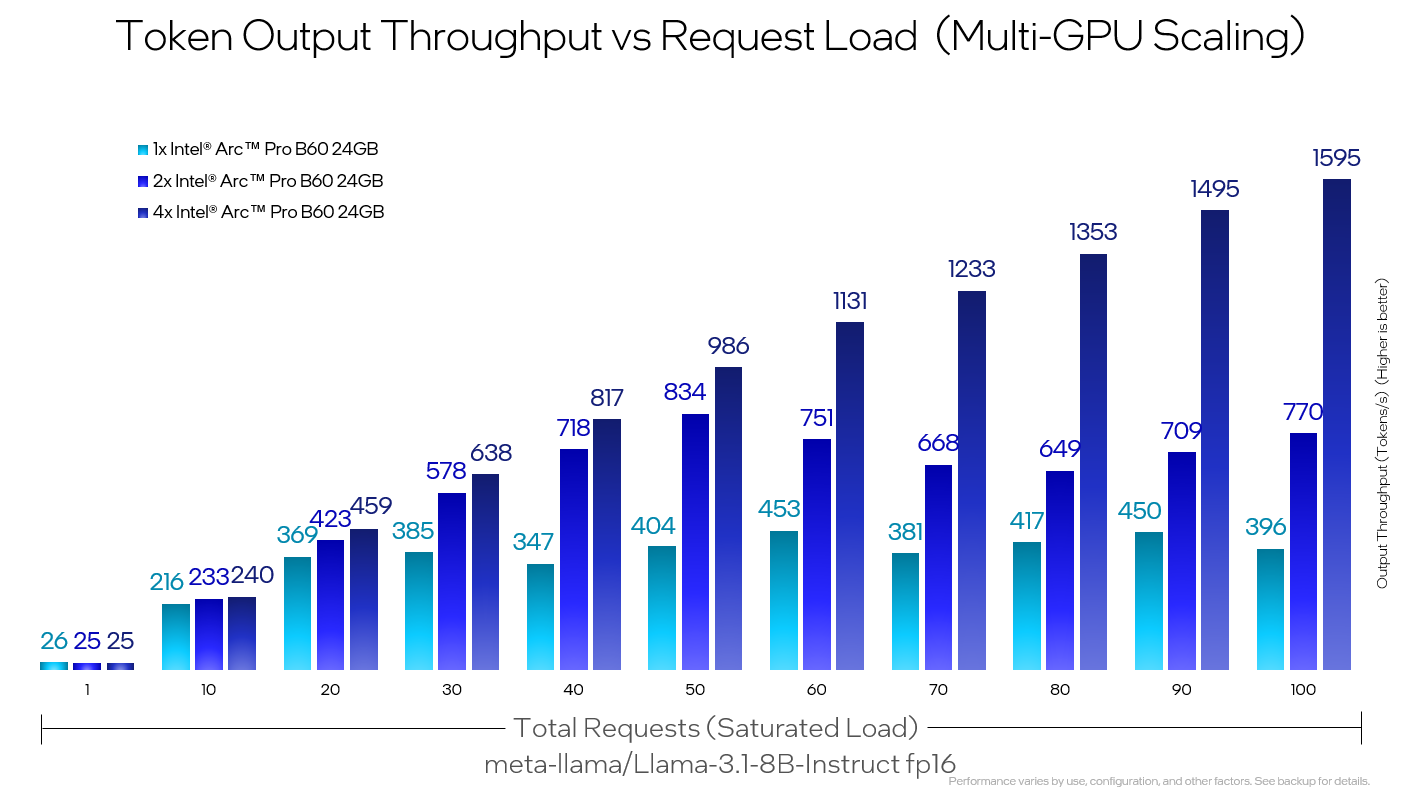
并发少,低负载时,2卡和4卡性能跟单卡没什么区别。而当并发数越来越高,达到100时,4卡方案的性能达到了1595,而单卡方案则是396,几乎刚好是4倍。这说明Arc Pro B60多卡并行效率非常高,说明堆显卡确实可以提高处理能力。
单机4卡方案提供每秒1595的Token数,对于一家有几十上百位员工的企业来说,已经完全够用了。这里没有看到单机8卡方案的性能跑分数据,如果有相关的测试数据,相信会有更强的性能表现。
本地推理,显存为王,有了大显存,就可以干一些以前做不到的事情,比如推理120B参数的gpt-oss-120B。尽管该模型采用了MXFP4格式,能显著减少显存的占用,但实际上也需要至少66GB的显存容量。
用户可以用单张80G显存的卡,也可以通过Tensor Parallel(张量并行)的方式把它分布到四张B60上,4块显卡同时计算同一个任务的不同部分,最后汇总四张卡的计算结果,完成输出。
测试结果显示,低负载时候,每秒Token随并发增长而快速增长,并发在60-70时,性能达到了1000 Token/s,此时性能达到巅峰。
这说明,仅需四张英特尔Arc Pro B60,显卡成本大约2万人民币,就完成了原本需要一张售价约为20多万的H100(80G),或者一张售价6万多的RTX PRO 6000(96G)才能做到的事情。
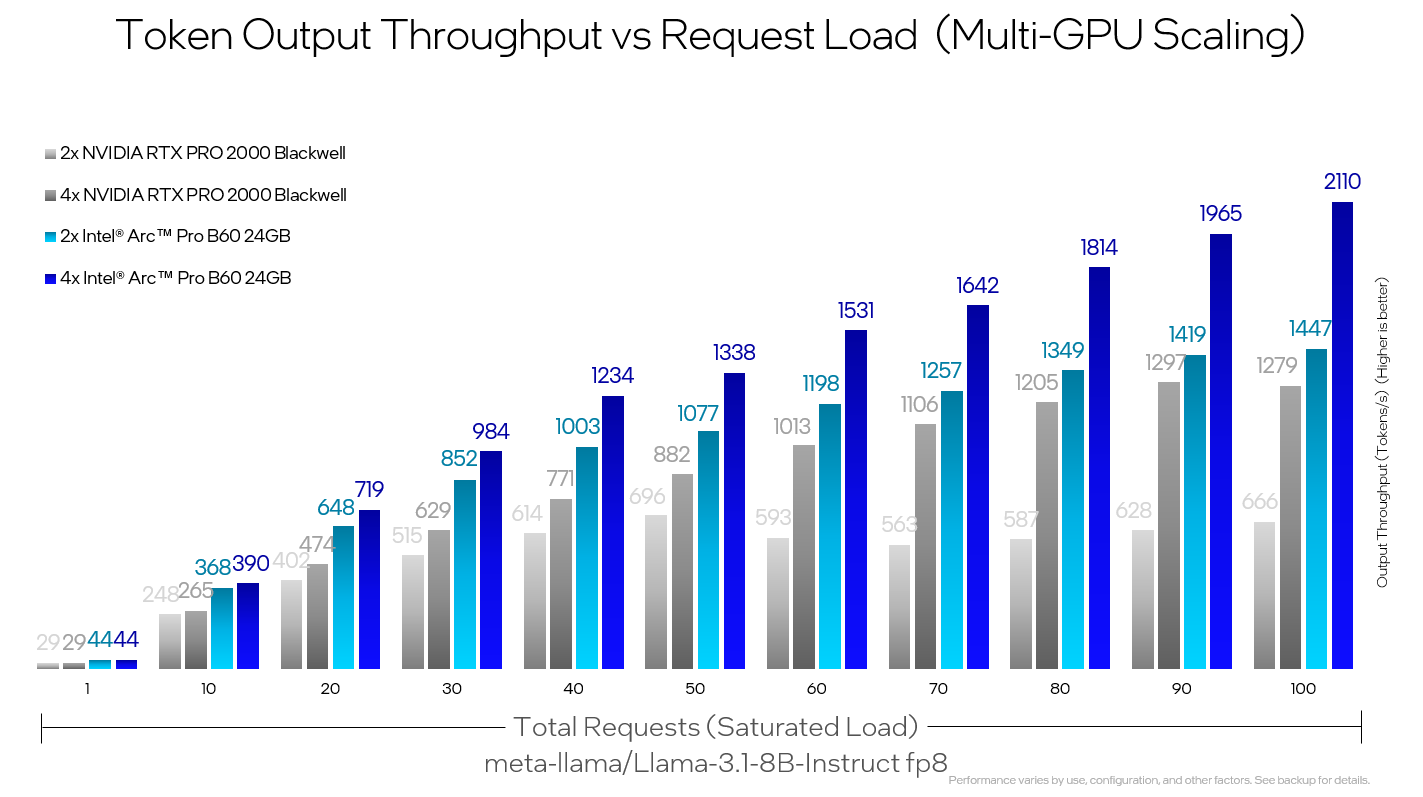
另外一张图也非常有意思,展示了2/4张B60和2/4张RTX Pro 2000(16G)在推理Llama-3.1-8B-Instruct FP8时的性能表现。我们可以清楚的看到,2块英特尔Arc Pro B60的性能也稳稳超越了4张英伟达RTX PRO 2000的表现。
有人说B60是24G显存,RTX PRO 2000是16G显存,两者显存都不一样,对比不公平。上图测试中能看到,2张B60显存总容量是48G,4张RTX PRO 2000显存容量是64G,英特尔方案的显存其实更少,但实际性能更强。
之所以英特尔官方拿这两个卡做对比,可能是因为这两个卡的售价在一个水平。我们再做一个公平的对比:上图中,B60扩展到4卡后,性能还会随并发继续增长,而英伟达的4卡在80并发后,性能增长就变得非常缓慢,英特尔方案的扩展性有优势。
以上,就是英特尔Arc Pro B60的一些性能跑分数据,更低的成本,更大的显存,不俗的性能,还有方案架构上的扩展性。可以说,英特尔是准备用离奇的性价比,在本地中小企业推理场景中杀出一道口子。
英特尔锐炫Pro B60的简要介绍
说了这么多关于性能和性价比的描述,接下来认识一下英特尔Arc Pro B60。英特尔于2022年推出Arc独立显卡,既有游戏显卡,也有专业级显卡,这里的Arc Pro B60是一款专业级显卡,不适合用来玩游戏,适合AI推理和图形渲染。
Arc Pro B60是基于Battlemage(Xe2)架构的第二代产品,B60的B就取自架构名字。第一代产品架构叫Alchemist,所有产品命名都以A开头,对应的产品就是A60,A60显存是12G,而B60直接容量翻倍,带宽也翻倍,显存部分的提升最引人瞩目。
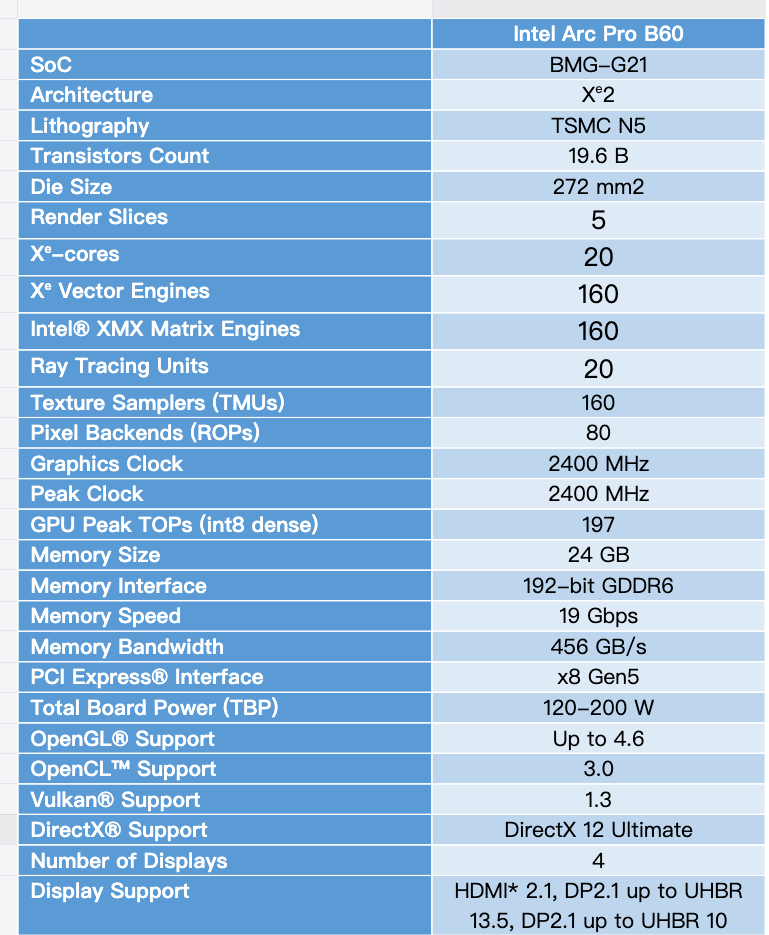
以上是Arc Pro B60的主要参数,为了便于大家对比和理解,这里简单介绍一下主要的信息:
上图中的Xe-core的概念对应的是英伟达的SM,就是基本的计算单元。此外,Xe Vector Engines(XVE)向量引擎的概念对应英伟达的Cuda核心,XMX Matrix Engines对应英伟达的Tensor核心,Ray Tracing Units对应英伟达的RT核心。
Arc Pro B系列采用了第二代的Xe-core,与上代相比,每个核心性能提升70%,能效提升了大约50%。全新升级的光追单元,将吞吐能力最高提升了2倍。第二代XMX AI引擎能帮助本地设备实现更强的本地推理性能。

具体到Arc Pro B60,它有20个Xe-core计算单元,每个Xe-core有8个Xe Vector Engines(XVE)向量引擎,每个Xe Vector Engines(XVE)向量引擎都配备有一个XMX AI引擎,一共有160个XMX AI引擎,具有197 TOPSAI算力。
XMX AI引擎对于AI场景的性能表现影响比较大,每个引擎的计算能力在每个时钟周期可完成2048次FP16运算,或4096次INT8运算。除了支持FP16和IN8,XMX还支持其他常见的AI数据格式,比如TF32、BF16、INT4和INT2。
XMX AI引擎是专门为AI推理设计的计算单元,用它跑INT8的高效推理,比用传统的乘加运算(MAC)方式最高能提高到16倍,所以,像XeSS 2(面向实时图形的AI推理负载)这类AI功能才能又快又省电。
结束语
德勤预测,到2026年,推理将占所有人工智能计算能力的2/3。换言之,推理会越来越多,推理上的相关投入也会越来越多,如果有一些新的技术方案,能以更低的成本实现打造可灵活部署的推理方案,也是非常有意义的。
英特尔的Arc Pro B60虽然不追求极限算力性能,但24GB的显存、良好的多卡扩展能力,以及极具冲击力的价格,对于中小企业以及部分专业用户在本地做推理,还是非常有价值的,可以说,已经很难被忽视了。







