
在移动计算进入AI优先时代的关键节点,Arm推出的Lumex计算子系统(CSS)平台通过架构级革新与全栈优化,重新定义了端侧智能的性能边界。

一、Arm C1 CPU集群:SME2赋能的端侧AI算力跃迁

作为Arm Lumex CSS平台的计算核心,基于Armv9.3架构的Arm C1 CPU集群通过硬件级AI加速与异构核心设计,构建了从旗舰到边缘设备的全场景算力底座。其最核心的技术突破在于第二代可伸缩矩阵扩展(SME2)的原生集成,这一技术专为AI工作负载设计,通过增强矩阵运算单元的并行性与内存访问效率,实现了计算密度的质的飞跃。

从实测数据看,启用SME2的Arm C1 CPU集群在生成式AI、语音识别等典型场景中展现出颠覆性性能:在Whisper Base语音模型中,语音转文字的延迟从1495ms降至315ms,降低4.7倍;Google Gemma 3大语言模型的编码速度从84 Token/s提升至398 Token/s,性能提升4.7倍;Stability AI Stable Audio音频生成时间从27秒缩短至9.7秒,提速2.8倍。
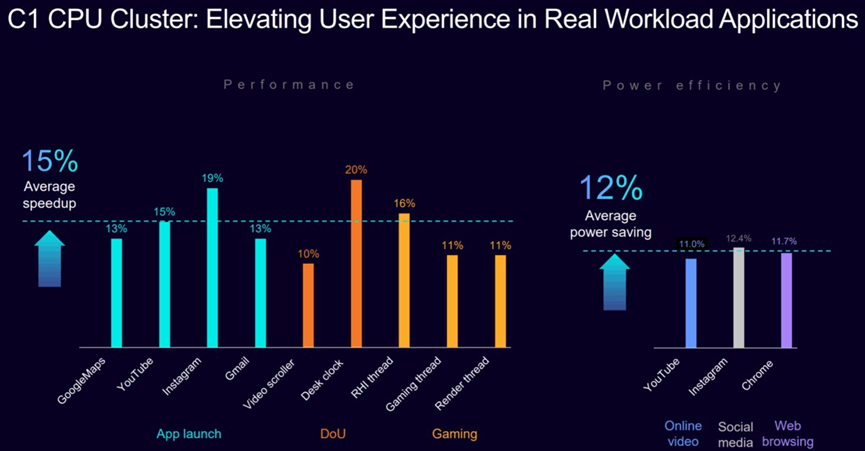
异构核心的精准分工是Arm C1 CPU集群的另一大技术亮点。Arm C1-Ultra作为旗舰核心,通过业界领先的前端设计与最宽微架构(10宽发射),实现了较上一代Cortex-X925高达25%的单线程峰值性能提升,其每时钟周期指令数(IPC)的两位数增长,确保在大模型推理、计算摄影等场景中瞬间释放算力。而Arm C1-Premium作为首款次旗舰核心,通过缩减35%的核心面积,在SPECint2017基准测试中保持与C1-Ultra相当的性能,实现了面积效率的突破。
面向能效敏感场景的Arm C1-Pro,通过增强型分支预测器(预测准确率提升8%)与内存系统更新,在相同主频下较Cortex-A725实现16%的持续性能提升,同时在视频播放、网页浏览等日常负载中能效优化12%。而Arm C1-Nano则通过解耦预测-取指流水线设计,在核心面积缩小2%的情况下,SPECint2017性能提升5.5%,能效较Cortex-A520提升26%,成为可穿戴设备的理想选择。
系统级协同方面,全新Arm C1-DSU(DynamIQ共享单元)通过动态电源管理与带宽优化,较上一代DSU-120功耗降低26%,同时支持最多8个核心的灵活配置。例如,启用了SME2技术的Arm C1-Pro与C1-Nano的组合可使中端设备计算密度提升两倍,满足实时翻译、智能助手等场景需求。
二、Mali G1-Ultra GPU:光线追踪与AI推理的硬件级融合
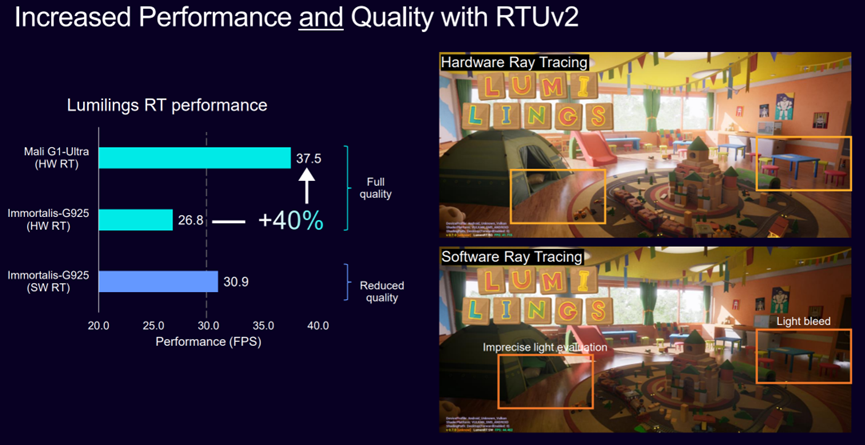
Mali G1-Ultra作为Arm Lumex CSS平台的图形与AI加速核心,通过架构重构实现了移动设备上”视觉保真与智能响应”的双重突破。其第二代光线追踪单元(RTUv2)采用单光线模型与独立硬件设计,较上一代RTUv1实现两倍光线追踪性能提升,在《Mori 林间鼯语》演示中帧率从26.8 FPS提升至37.5 FPS,同时支持完全独立的电源域控制,可在设备空闲时断电,从而为其他任务节省电力。
在游戏性能方面,Mali G1-Ultra通过双堆叠着色器核心设计(内部带宽提升100%)与快速访问统一寄存器,在主流游戏中实现全面提升:《暗区突围》性能提升25%,《崩坏:星穹铁道》提升19%,《原神》提升17%。此外,Mali G1-Ultra还引入了Arm图像区域依赖(IRD),使GPU可同时处理屏幕不同区域的渲染任务,从而在复杂场景中提升性能并减少空闲时间。
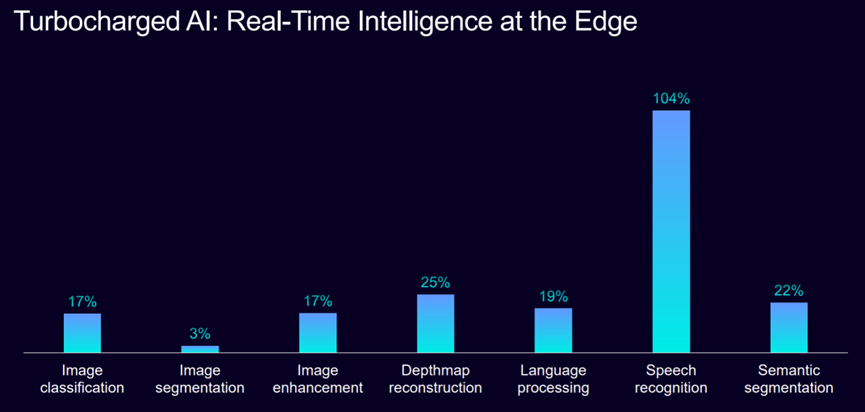
AI加速能力上,Mali G1-Ultra新增的FP16矩阵乘法单元(MMUL)专为端侧实时智能设计,较上一代Immortalis-G925实现20%的AI推理加速,其中语音识别性能提升104%,图像增强提升17%。通过扩大L2缓存与优化的互连设计,该GPU可大幅减少内存瓶颈,并确保实时体验的灵敏响应与流畅运行。
三、系统架构与软件生态:高性能与可扩展性的底层支撑
Arm Lumex CSS平台的卓越表现离不开系统级互连与内存架构的革新。全新SI L1系统互连配备业内先进的,且具有出色面积效率的系统级缓存(SLC),泄漏功耗较标准RAM降低71%,显著减少设备待机功耗。该互连支持Arm内存标记扩展(MTE),可提供一流安全性。

软件生态方面,Arm KleidiAI库实现了SME2加速的无缝调用,已与阿里巴巴MNN、Google LiteRT、微软ONNX Runtime等主流框架深度集成。开发者无需修改代码,通过框架自动优化即可获得性能提升。Google的Gmail、YouTube等应用已完成SME2适配,设备上市即可启用优化功能。
工具链方面,Arm Lumex CSS提供自顶向下的遥测解决方案,结合Vulkan计数器与RenderDoc调试工具,开发者能够实时分析工作负载、调优延迟,并精确平衡电池续航与视觉效果。
技术总结:重新定义端侧计算的黄金标准
Arm Lumex CSS平台通过Arm C1 CPU集群的SME2加速、Mali G1-Ultra的架构革新与系统级协同设计,构建了”性能-能效-面积”的最优解。其核心突破在于:实现AI工作负载五倍性能提升的同时能效优化三倍;光线追踪性能提升两倍且支持桌面级视觉效果;通过灵活配置覆盖从旗舰手机到可穿戴设备的全场景需求。
随着搭载Arm Lumex CSS平台的移动终端产品陆续落地,智能手机将真正迈入”实时端侧AI”时代——从10亿参数大模型的本地运行,到4K HDR视频的实时AI增强,再到主机级游戏体验的持续输出,Arm Lumex CSS平台正在重塑用户与技术交互的每一个瞬间。







