近日,在2023年中国数据与存储峰会“AIGC+存储融合发展论坛”上,腾讯云存储高级产品经理熊建刚老师发表主题演讲,就高性能存储和大模型融合创新相关研究展开探讨,以及腾讯云存储的实践案例,引发关注。

熊老师耕耘存储20年,在腾讯云从事云存储领域的高性能存储以及与大模型融合创新方面的研究工作,致力于推动云技术和人工智能的创新与发展。
如何将存储技术与人工智能、机器学习相结合,从数据存储、处理到智能分析,揭示如何利用存储技术为AI应用提供高效、可扩展的基础,熊老师在演讲中提出了他的思考。
一、存储技术与人工智能相结合:为AI应用提供高效、可扩展的数据存储和处理基础
面对当前如此巨大的数据量,存储产品和技术如何服务好我们的大模型?
以ChatGPT为中心,它的参数指数级发展,已经接近甚至超越人脑神经网络数量。因此后台对应的算力有巨大的诉求,基本上百卡的虽然比较起步了,千卡和万卡,最后我们会有一个巨大的成本的投入。
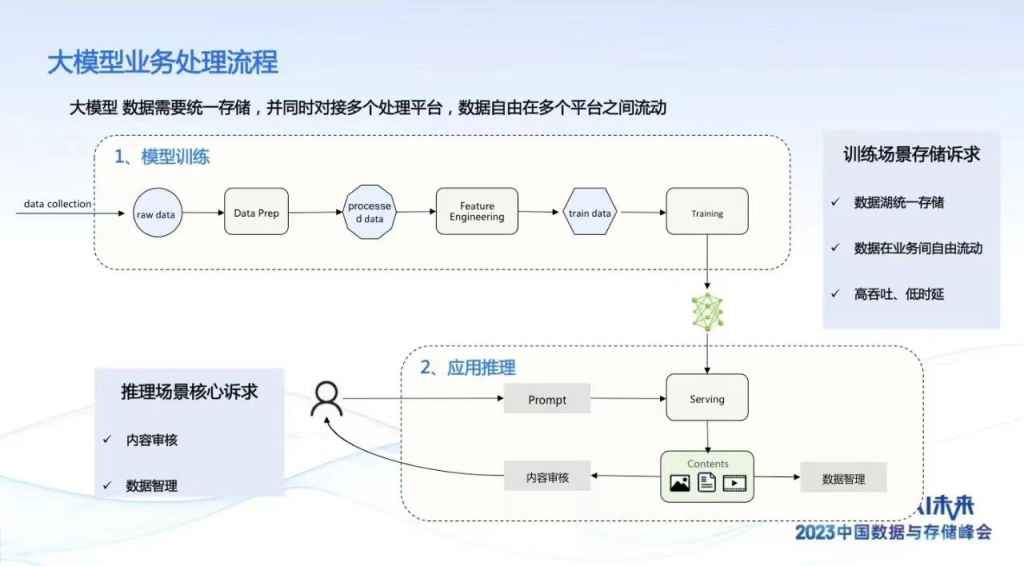
把整个流程站在业务角度我们可以打开来看,从开始的数据的注入,这个注入有很多模式,在大模型维度可能通过我们各种语料的注入,进一步的话,我们做数据的预处理,这里有一些常见的批注,包括数据预想到的结构化的处理。再进一步我们对数据进行训练,通常来说我们比较花钱地方,一轮跑下来比较花钱。
再接着进行数据的训练和推理,推理过程中有对数据安全的检测。整一套流程我们可以在存储的维度提炼出几个诉求,我们有统一的存储模式,一个流程下来,你不需要经过太多的不同的存储的服务的供给,希望一套数据能够进行全流程处理。再接着,我们对数据处理逻辑有一个自身的检测。在AIGC里面,内容审核目前看尤为关键。

我们看到具体展开看有哪些诉求。一开始采集过程中,对于存储来说使用诉求是比较互联网化的,互联网的服务希望是互联网对象存储的协议,数据量体量比较大。
第二个环节数据的预处理,整个环节访问方式比较灵活,有我们常见大数据的,HDFS,还可以用文件的语义。整个处理模型的数据量在百TB级,顺序以大带宽的读写为主。
第三个变成两个阶段,访问接口希望采用文件的语义,将存储数据按照文件方式挂载,进行读取。有顺序的读也有随机读,以及前面专家讲到实时的checkpoint写,这是对存储考验能力的地方。
我们知道整个GPU使用过程中,本身也有一定的不稳定因素,会导致整个训练过程中断,这是比较花钱的,我们最常见的处理方式是把过程写入到存储,一旦有中断的时候存储快速地回滚,将以前计算结果做了很好的保存。后面推理,推理的时候主体读,读的模型以POSIX语义为主,前面处理的模型的数据有一定的结构化,后面对内容进行治理。
二、创新存储解决方案:满足大规模数据处理和AI应用的需求,提供高性能、可靠性和可扩展性
第二个阶段,我按照存储供给方式,第一个维度前面说是比较贵的,量化的数据,我们拿着8核32G的节点,如果插入一张T4的显卡,成本巨大提升,占比超过80%以上。第二,各种因素,原始产能因素,目前宏观的因素,缺货比较严重,后期会半年以上。所以整个因素会导致构建模型的时候是以算力为中心,从我们客户来讲,哪个地方我在腾讯上,哪个地方有算力,赶紧构建环境,希望数据快速地供给。
第二个存储在过往这么多年经验,我们逐渐构建以数据为中心的计算生态,很天然,我们数据是有状态的,你的计算可以就近调度到数据这边来,它是无状态随时拉起。

随着云上数据湖的构建,会构建更优的数据为重要的技术平台。随着大模型的发展对诉求,进一步加强。第一,我们看到可靠可用,对可用性有巨大要求,我希望写入是可靠的。第二,合规有更高的要求。我们以前讲的数据是核心资产,到了大模型里面很多模型就是核心资产。花了那么多价钱算出这个模型,我们要做很好的保存和合规。
第三个随意的访问,这个非常重要,我们之前构建数据湖的时候重要的优势是,一个能够在云上随时随地注入数据的,像湖一样,水从任何地方流入数据湖。第二,能容忍任何数据格式,通常来说,我不用管理你这个数据的模式,数据的格式,你可以让它自然进入到数据湖。
到了我们大模型时代,有进一步地提升,数据在很多时候会出现很大,单体的文件可以想象到很多客户单体文件可以到上百个TB。我们通常讲大文件一般来讲起步是兆,一兆以上是大文件,我们通常能看到一个G的文件也很大了,到了大模型时代,到了TB级,百TB的大模型。
第三个点低成本和扩展能力,这个尤为关键,现在构建的数据湖,我们希望扩展性有极大的空间,这个空间没有任何的限制,你可以轻易构建EB级的数据湖存储。
有了这两个我们发现有一个小小的GAP,原来我们构建以数据为中心的IT模型,有一个GPU为中心,以算力为中心,中间会有一些挑战,以客户来说,数据构建在腾讯云数据湖上,算力是动态的,也就是说有可能在北京的园区,正好能拿到GPU卡,构建大模型的计算,中间就有位置的不匹配。
还有数据湖的构建是以大容量,海量扩展为中心,对GPU来说,投喂数据的带宽是巨大的,单独构建给指定的算力,而存储数据中心以多租户的方式构建给云上的成千上万的企业客户。

技术维度,数据湖的构建,是以云上可以随时随地访问的对象存储,是KV的方式,没有目录结构的,而在以GPU算力为中心,我们刚刚有展示的以语意的方式。有一部分很兼容,投喂语料的时候用云原生的对向接口是可以的,一旦进入到推理环节希望是充分的文件语意。
出现这样一个GAP,我们怎么解决这个问题呢?
第一,我们构建了一个数据加速器,它起的作用是数据还是在以对对象存储为中心的数据湖里,原来数据湖的入湖和湖上各种应用的构建,特别最近流行的湖仓一体,这些分析都没有任何变化。当你需要构建大模型的时候,刚才的例子,我在腾讯云的北京六区,拿到GPU资源的时候,我需要做的事情非常简单,我在腾讯六区构建数据湖的加速器,加速器的存储能力以单租户的形式,跟我们私有化使用是完全一样的体验,这样的话,我保证昂贵的GPU算力得到充分的存储资源的供给,不要因为存储资源任何的不给力或波动导致算力资源的浪费。
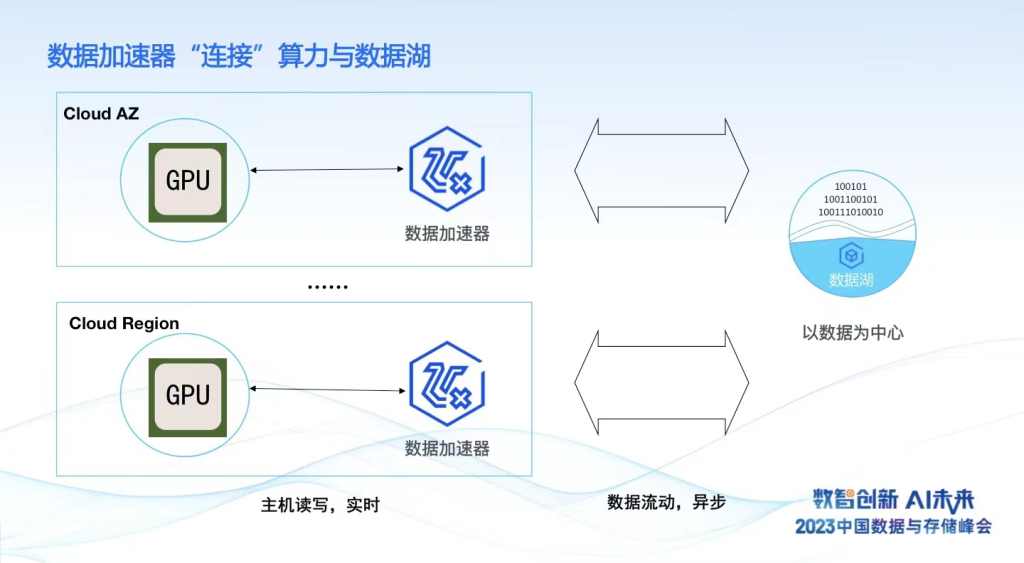
第二,供给过程中,我可以实时根据算力的变化,有可能同时在广州的三区,供给到另外一批GPU,随时可以拉起数据加速器,实现存储资源的供给,整个过程是云原生的方式,满足以算力为中心的调度,哪里有算力,有GPU卡,哪里就能供给到数据加速器。
从存储读写维度,GPU到加速器整个访问路径跟之前的GPU使用模式是一样的,可以当做一个并行的稳定系统进行使用,读写是实时高并发的。另外一个程度,我们的数据加速器和以对象存储为中心的数据湖实现异步的数据流动,这样可以将实时的checkpoint写入,可以将它异步沉降到数据湖里面进行长久的保存。同时,可以将其他地域模型结果加载到另外一个数据中心实现推理,这样实现GPU资源合理的应用以及整个云上资源全局的调度。
三、腾讯云实践分享

腾讯云面向大模型提供了一站式、全流程以及端到端的解决方案,加速大模型训练效率,将数据和算力有效融合。
一站式是站在业务的数量上,每个环节都需要存储的供给,都需要数据的处理,腾讯云提供一站式方案,从最初采集到最后整个训练完以后的推理和审核,整个方案以云原生的方式供给算力,按需进行部署、训练和结果审核。
UGC的审核能力和解决方案,AIGC内容可以被平滑地使用,可以对内容进行各种分类和批注,围绕AIGC,将云的原生能力形成全链路方案的供给。
端到端,从计算,从IT全链路全栈,腾讯云提供了以对象存储COS为底座的数据湖,再到加速层,构成系列的数据加速器体系,到TACO面向GPU的加速的套件,以及面向大模型的加速的网络,这样一个端到端的数据的大模型解决方案,可解决数据兼容原来的数据湖,适配算力按需的供给,高速供数据资源,满足快速的训练和网络的快速交换。
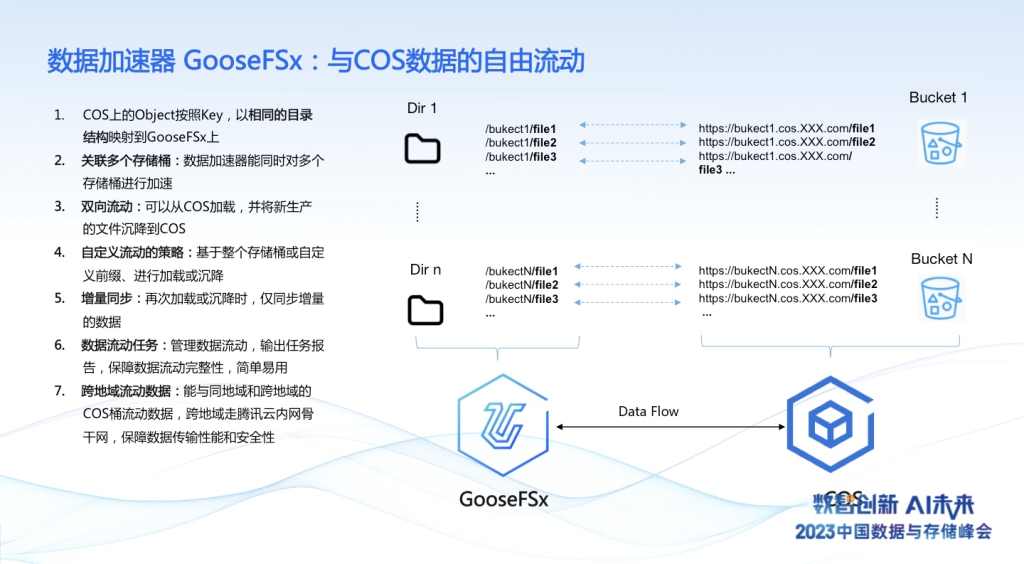
腾讯云数据加速器GooseFS通过全托管云服务,可一键式购买发货,省去部署、调测等运维工作;完全兼容 POSIX 文件语义,工作负载无需进行任何改动;GooseFS按创建容量计费,按量付费、弹性扩容,避免资源闲置;可自动批量部署客户端软件,将GooseFSx挂载到主机的本地目录,简单易用。
更多内容,欢迎您参考阅读原文中的专题视频讲解。