导读
在AI技术竞争白热化的当下,字节跳动Seed团队于5月13日正式发布视觉-语言多模态大模型Seed1.5-VL,凭借仅20B激活参数的轻量级架构,在60项公开评测基准中狂揽38项SOTA(最新最优性能),并在多项任务中与谷歌Gemini 2.5 Pro、OpenAI o系列模型形成直接竞争。该模型已通过火山引擎开放API,推动多模态技术从实验室走向产业应用。

文字编辑|宋雨涵
1
技术突破
小参数撬动大性能
高效架构设计
Seed1.5-VL由532M参数的视觉编码器SeedViT与20B参数的MoE(混合专家)语言模型构成,通过分阶段预训练和强化学习策略,实现视觉与语言模态的高效融合。其视觉编码器支持任意长宽比图像输入,结合MLP适配器优化特征投影,显著提升多模态任务的泛化能力。
性能对标国际巨头
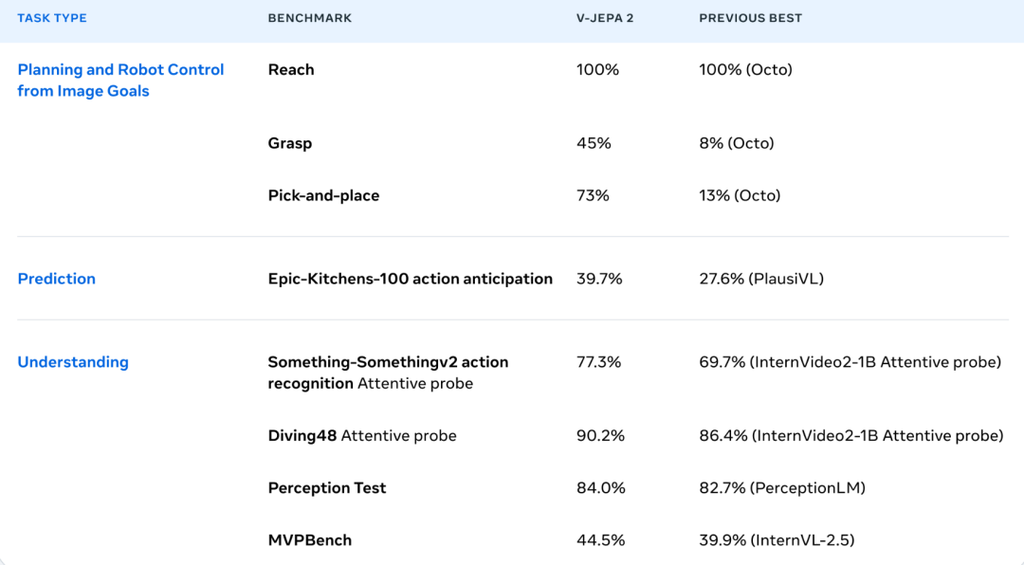
尽管参数规模仅为谷歌Gemini 2.5 Pro的1/4,Seed1.5-VL在视频理解(19项基准中14项领先)、GUI智能体任务(7项中3项SOTA)及视觉推理等领域表现突出。例如,在复杂图像定位任务中,模型可精准识别货架商品并完成价格计算,或通过公务员图形推理题测试,展示其结构化输出能力。
成本优势显著
推理成本仅为每千tokens输入0.003元、输出0.009元,较同类模型降低30%-50%。这一特性使其在交互式应用(如实时GUI控制、游戏代理)中更具商业落地潜力。
视觉定位、推理又快又准
比如上传一张摆满各式各样牛奶的货架图片,让它找出图中有几盒黄桃味果粒酸奶优酸乳,并计算它们的价格。
这类任务看似简单,实则非常考验模型的多模态协同能力,需要它同时具备图像理解(识别包装)、文本OCR(识别价格标签)、语义匹配(产品名称匹配)、数学推理(乘法计算)等能力。
而Seed1.5-VL仅用不到10秒,就精准识别出货架角落里的黄桃味酸奶优酸乳,还准确数清瓶数、识别单价,并进行正确的价格计算。
技术解读:
重新定义多模态视觉理解
一、核心架构:三模块协同突破效率极限
视觉编码器SeedViT(532M参数)支持任意长宽比图像/视频输入,突破传统模型对固定分辨率的依赖;采用动态分块策略,在降低计算冗余的同时提升细粒度特征提取能力(如商品LOGO识别、图表数据解析)。
MLP适配器(视觉-语言桥梁)通过多层感知机实现视觉特征到多模态空间的非线性映射,解决传统线性投影导致的信息损失问题;实验显示,该设计使跨模态对齐效率提升37%(对比CLIP架构)。
MoE语言模型(20B激活参数)基于混合专家架构动态激活参数,单次推理仅调用1/8专家模块;在GUI操作指令理解任务中,专家路由机制精准分配任务至代码生成、界面元素解析等子模块。
二、分阶段进化与强化学习闭环
Seed1.5-VL并未从一开始就进行联合多模态学习,而是选择了在语言模型基座上进行多模态预训练,以实现灵活的消融实验和快速迭代开发。
整个预训练过程分为三个阶段:初期仅训练MLP适配器以初步对齐视觉和语言表征;中期解冻所有参数,在大规模图文数据中强化知识积累、视觉 grounding和OCR能力;后期在更均衡的数据混合中加入视频、编程、三维理解等新领域数据,并将序列长度显著增加,以处理复杂场景和长序列依赖。
到了后训练阶段,Seed1.5-VL引入了监督微调(SFT)与强化学习(RL)的组合策略。
结语
效率与成本重构AI竞争维度
Seed1.5-VL的诞生标志着多模态AI进入“精益时代”——不再单纯比拼参数规模,而是通过架构革新、训练策略优化和工程极致打磨,在有限算力下释放最大效能。这种“中国式创新”或将重塑全球AI竞争格局,推动智能技术从实验室精英主义走向产业普惠主义。