
2022中国数据与存储峰会召开期间,在CXL大内存论坛上,英特尔 数据中心和人工智能事业部技术总监顾小宝详细介绍了CXL技术的缘起,CXL的演进过程,以及在未来如何使用CXL技术来重构数据中心的相关话题。
计算图景里的Load-Store l/O
在计算的图景里,系统通过CPU指令集的Load指令和Store指令,来对数据进行存取,这过程叫Load-Store IO,它与把数据存到硬盘里或者从硬盘读出来是不一样的,Load-Store IO操作的对象是内存或者英特尔傲腾持久内存这种,相比之下,这部分的作用更重要。
计算的本质是处理数据,对数据进行处理就可以从中得到一些更有用的信息,随着数据量来越大,对数据处理的需求也就越大。IDC预计,在2024年全球每年所产生的数据量,会高达160ZB,如何处理这些数据是一个非常大的挑战。
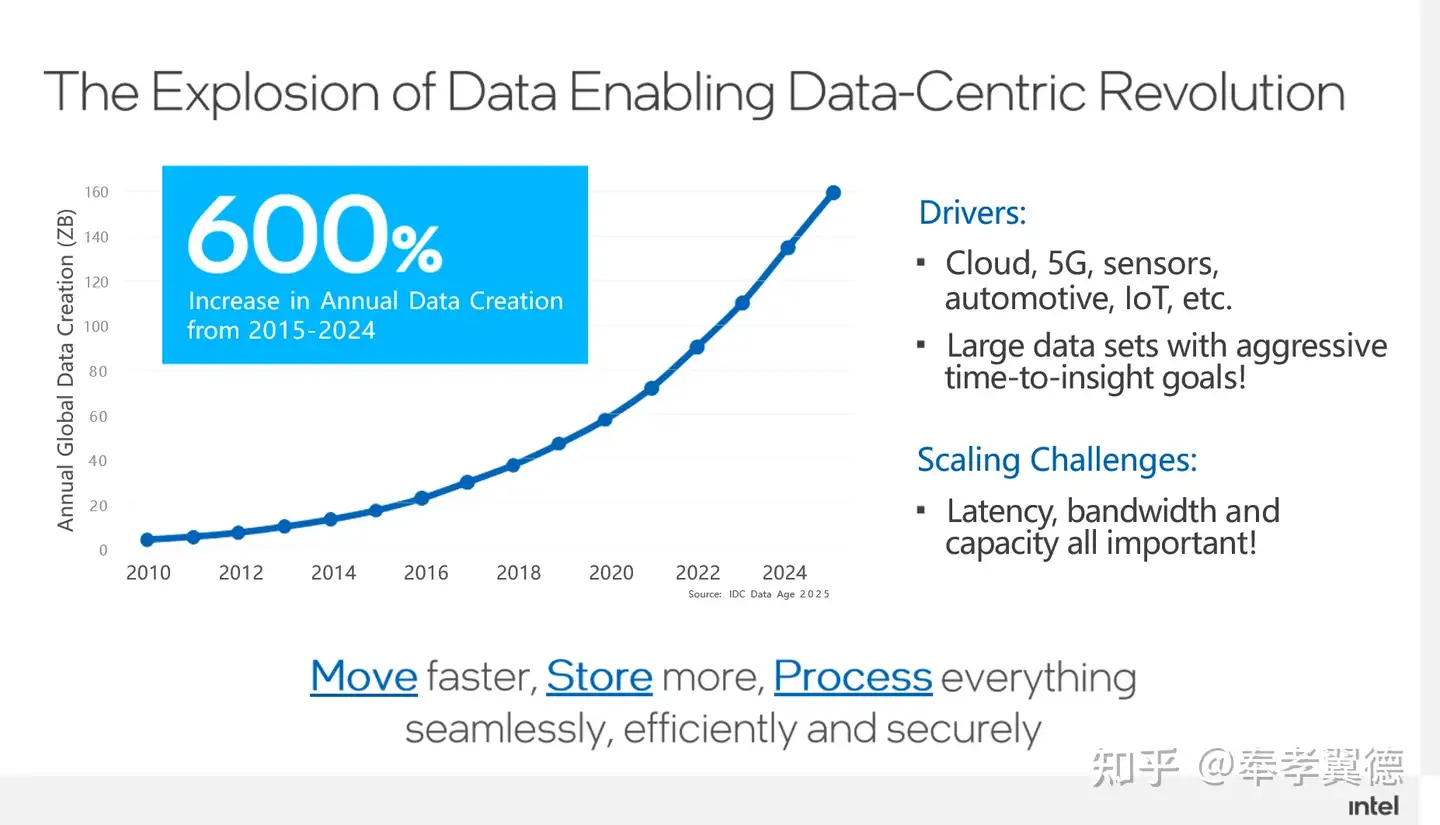
于是,英特尔提出了Move faster,Store more,Process everything的概念,可以处理任何类型的数据就叫Process everything,可以存得更多就叫Store more,在存和计算之间的网络就是Move faster,以此来应对数据爆炸性增长的趋势。
要做到这一点需要解决很多问题,比如如何有效地把大量数据读进来,如何尽可能地降低Latency,如何让带宽Bandwidth越来越高等等。
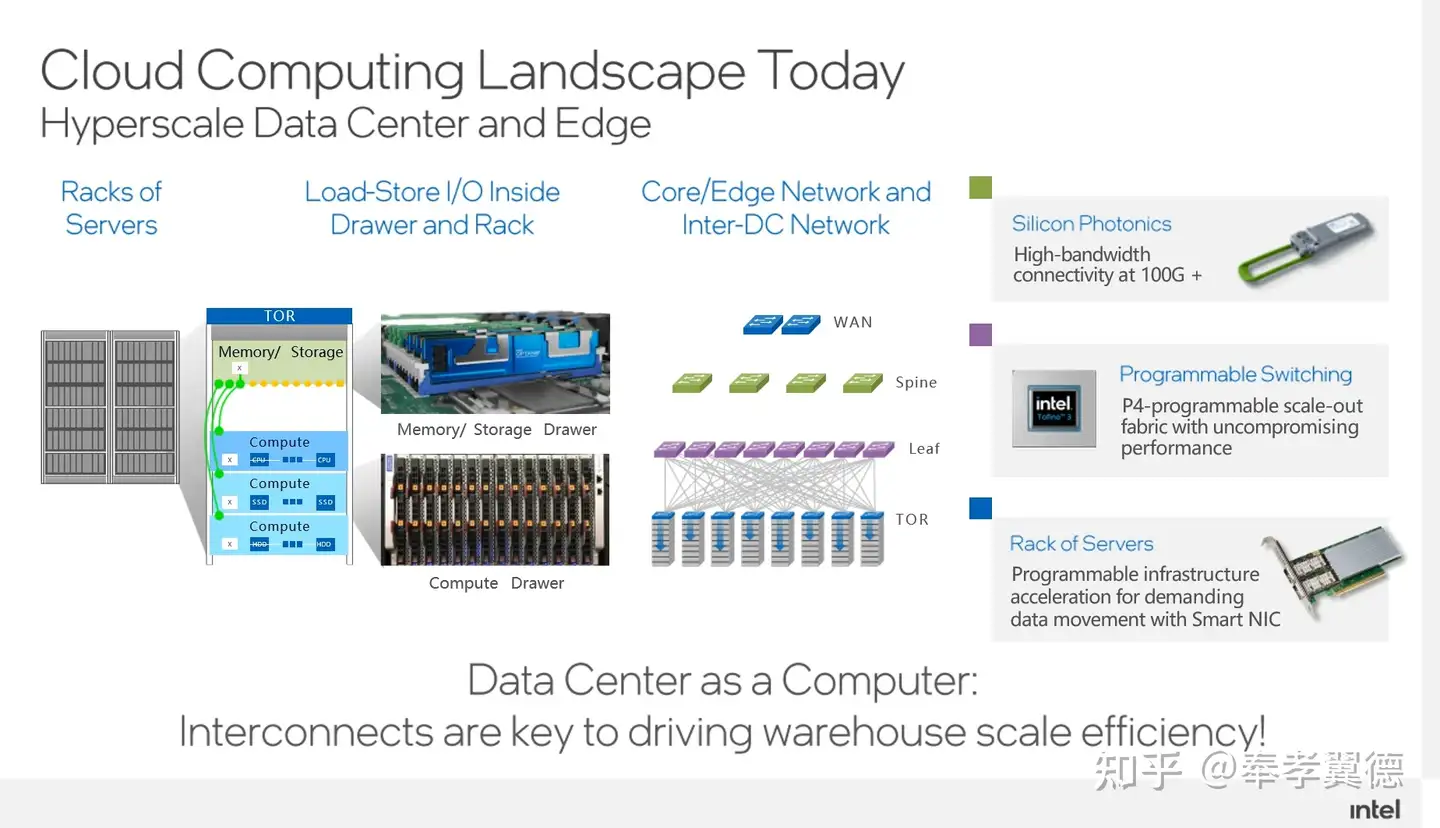
数据中心会有大量服务器,服务器里有内存,有各种板卡,连接网络的网卡,负责存数据的硬盘等等,服务器摆在机架上,机架通过网络相连,每个机架都有TOR swtich交换机,Switch跟Leaf swtich通过全连接的方式相连,Leaf和Spine之间通过胖瘦结构或者其他的结构相连,最上层,通过WAN广域网的出口和外部进行互联。
整体架构中涉及很多网络相关组件,比如硅光就非常流行,英特尔在前几年发布硅光的模块,在市场上取得了领先地位,提供超100G的高带宽,又比如,P4可编程交换机也很常见,它可以使得网络更加灵活。此外,网卡也是非常重要的。
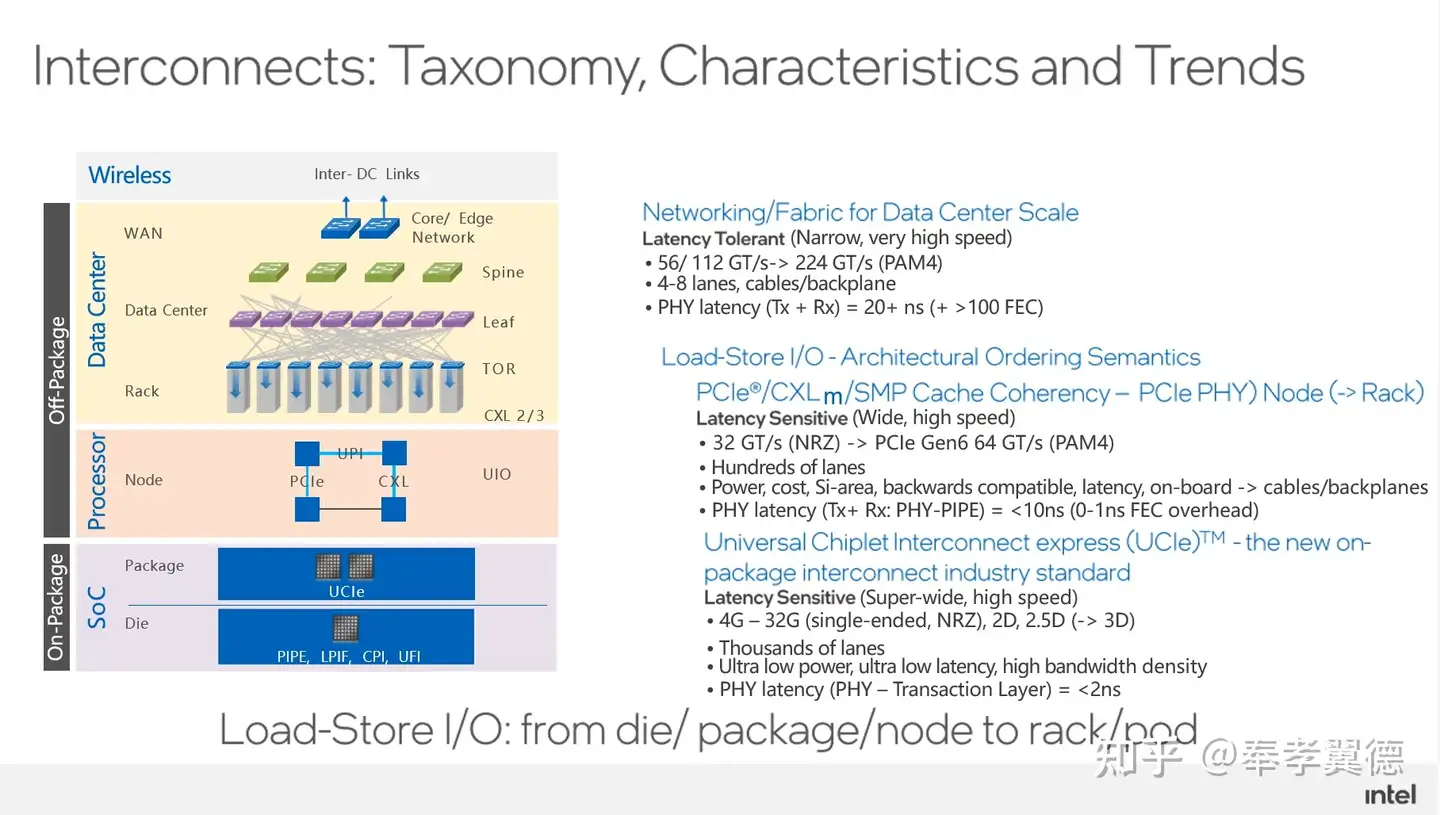
网络图景里,数据中心级别、处理器级别和SoC级别,不同层级有各自的特征。
数据中心规模的网络,其单链路的传输速率会非常高,通常能达到56G甚至112GT/s,同时,在有了PAM4这样的纠错方式以后,速率还会提升到224GT/s甚至更高。
虽然单链路速率非常高,但是它的链路数一般比较低,常见的是4链路或8链路。主要原因在于,如果链路变多的话,交换机会承受不了,通常意味着需要很大体积和很大功耗,都会带来非常大的额外成本负担。
数据中心规模的网络,都有较低的链路数,而且,它的PHY Latency通常都比较高,能达到20多纳秒的级别。
在处理器级别,常用的就是PCIe、CXL等网络。这些网络的单链路速率虽然也比较高,但比不上数据中心级别,同时,它的链路数是非常多,一颗CPU可以上百个PCIe通道,通常,它的PHY Latency在10纳秒以下。
在SoC级别,主要看UCIe网络,UCIe(Universal Chiplet Interconnect Express)是Intel牵头建立的一个新的标准组织,它是一套连接管理的标准,它可以把不同厂商和不同规范的小芯片以标准化的方式集成在一个大的封装里,使得芯片和芯片之间耦合也会变得更松。

UCIe所定义的链路的单链路速率不高,但是它的链路非常多,通常可能有上千条,所以,它的数据通信带宽非常高,而且延时非常低,一般它的PHY延时小于2ns,延迟非常低。
UCIe的价值在于,它能让数据在Chiplet和Chiplet之间快速搬运大量数据,并且能降低搬运大量数据所需的功耗。
目前,UCIe组织成员包括英特尔、台积电、英伟达、AMD、ARM、高通、三星等业内芯片巨头,也有阿里巴巴、GCP、微软、Meta等等互联网公司,已形成了强大生态。
CXL带来的技术变革
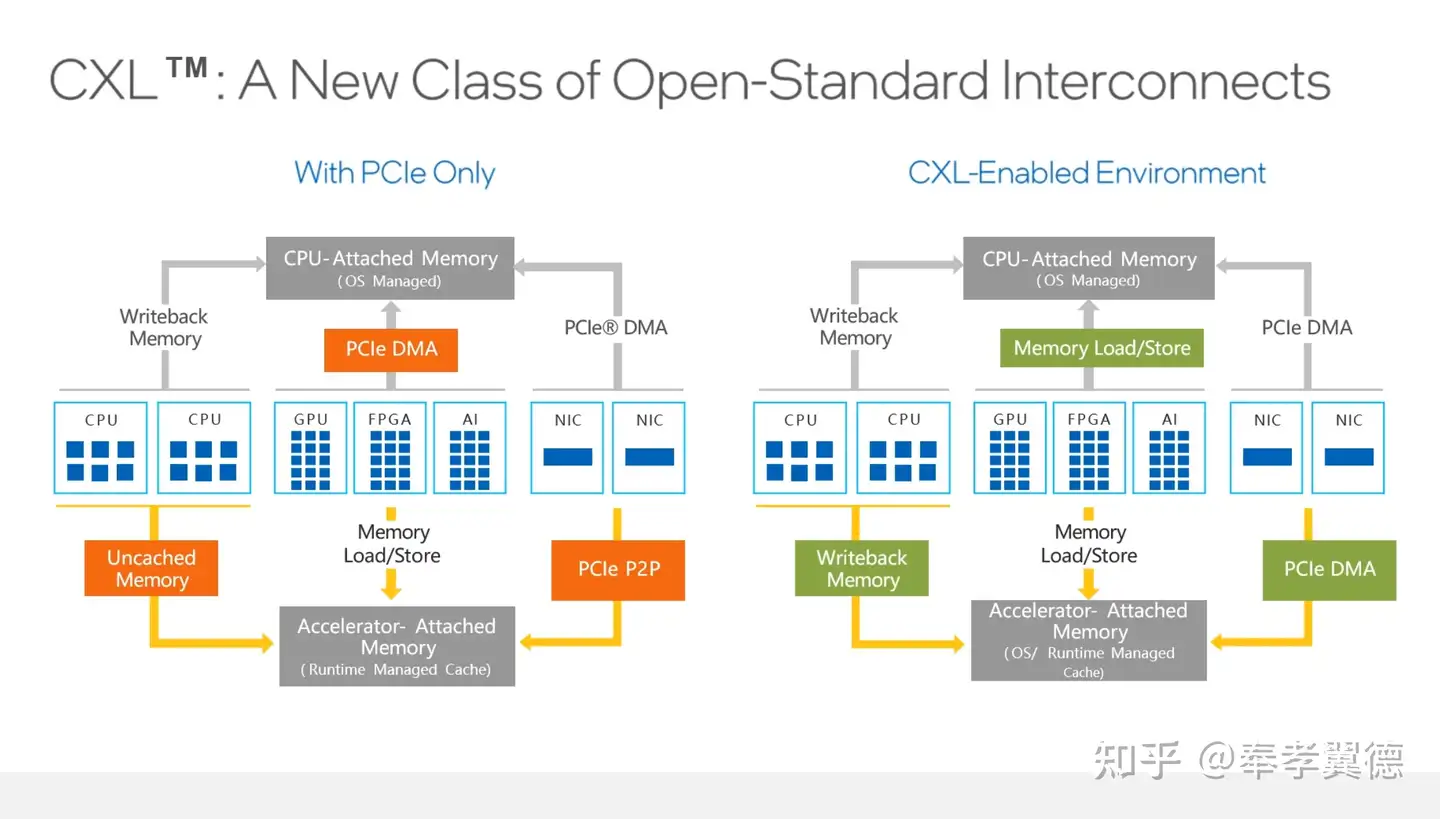
CXL解决了哪些问题呢?
上图左侧展示的是只有PCIe的情况,此时,无论是CPU还是加速器都只能通过PCIe的DMA方式去拷贝数据。
比如要做AI训练的话,CPU通过memory copy的方式把数据拷贝到GPU里,训练完后后再通过memory copy把数据拷回去,数据拷贝全都依靠PCIe DMA。PCIe DMA的效率非常高,但它只适合拷贝大块数据,不适合小块数据。
上图右侧中是有了CXL的情况,在CPU和OS所管理的内存可以通过Load-Store指令与加速器进行通信。所以,它比PCIe DMA的方式更灵活,大块数据用PCIe DMA,小块数据通过Load-Store指令来执行读写。
有了CXL之后就意味着实现了真正意义上的异构计算,这里所说的异构计算指的是CPU和其他加速器的协同工作,加速器分担一部分工作,相互之间进行数据交换,把各自产生的结果进行交换,最终得到一个结果。
CXL让计算方式发生了巨大的改变,既有硬件的改变,也需要软件上的配合。以英特尔为例,在软件方面开发了oneAPI,oneAPI把异构计算的工作都统一到了一个编程框架里来执行。
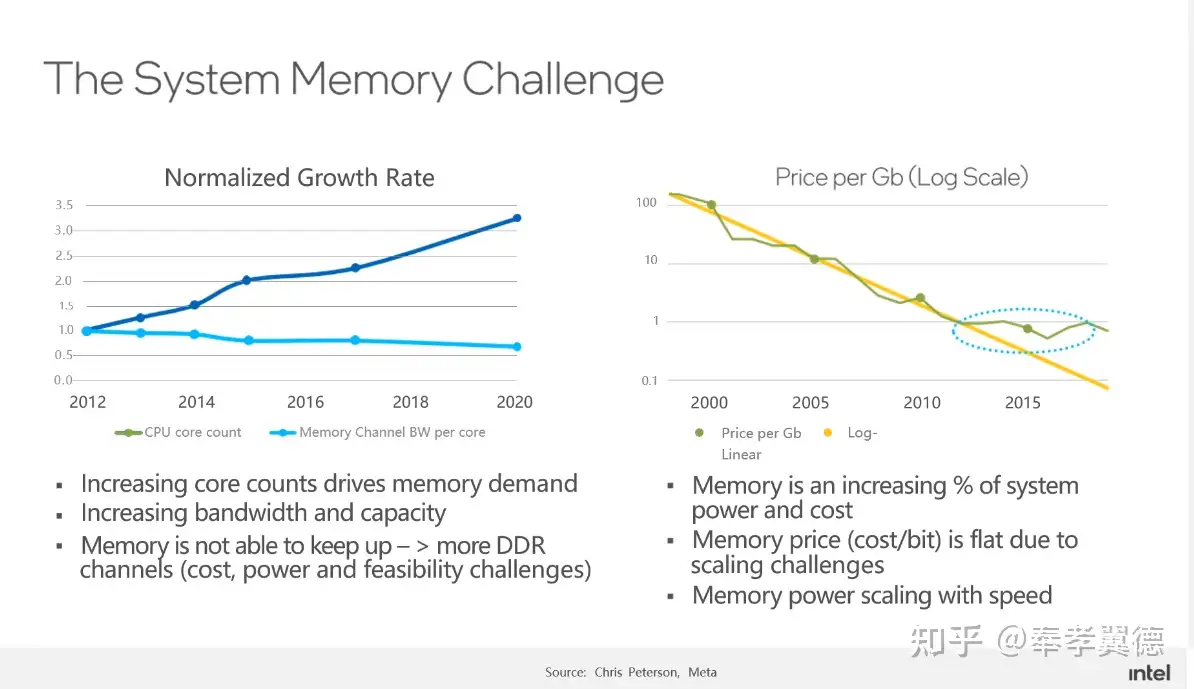
当前的系统架构中,Memory子系统自身面临很多挑战。
如左边图所示,CPU技术的发展使得核心数量实现了比较快的增长,但内存通道数增速则相对较慢。从发展趋势来看,每个CPU核心所拥有的内存通道反而是在下降,这会带来很多问题,很多CPU核心因为不能充分得到数据来处于满负荷的运行状态,会导致整体计算效率下降。
为什么不在增加核心的时候也增加内存通道呢?
其实,这牵涉到了CPU的设计问题,内存控制器是在CPU里的,如果增加内存通道,则意味着会增加CPU的功耗,芯片面积也会变大,PCB走线距离增加,为了保证信号的完整性,对于PCB本身也提出更高要求,所以,CPU的成本和功耗都会增长。
从服务器整机的层面来看,在主板上增加内存DIMM槽,插上更多的内存后,整机的成本也会不可避免地增长,即使内存成本降低,也不会无限度的降低下去,最终会导致整体成本的上升。所以,不能随意的无限度地通过增加内存通道来解决问题。
CXL的出现从新的维度来解决问题。
CXL把内存与CPU的关系从紧耦合变成一个松耦合,通过CXL网络的方式,让CPU访问远端的内存资源,最重要的是,远端由由CXL技术支撑的内存可以任意地扩展内存容量,摆脱了CPU和服务器本身的限制。
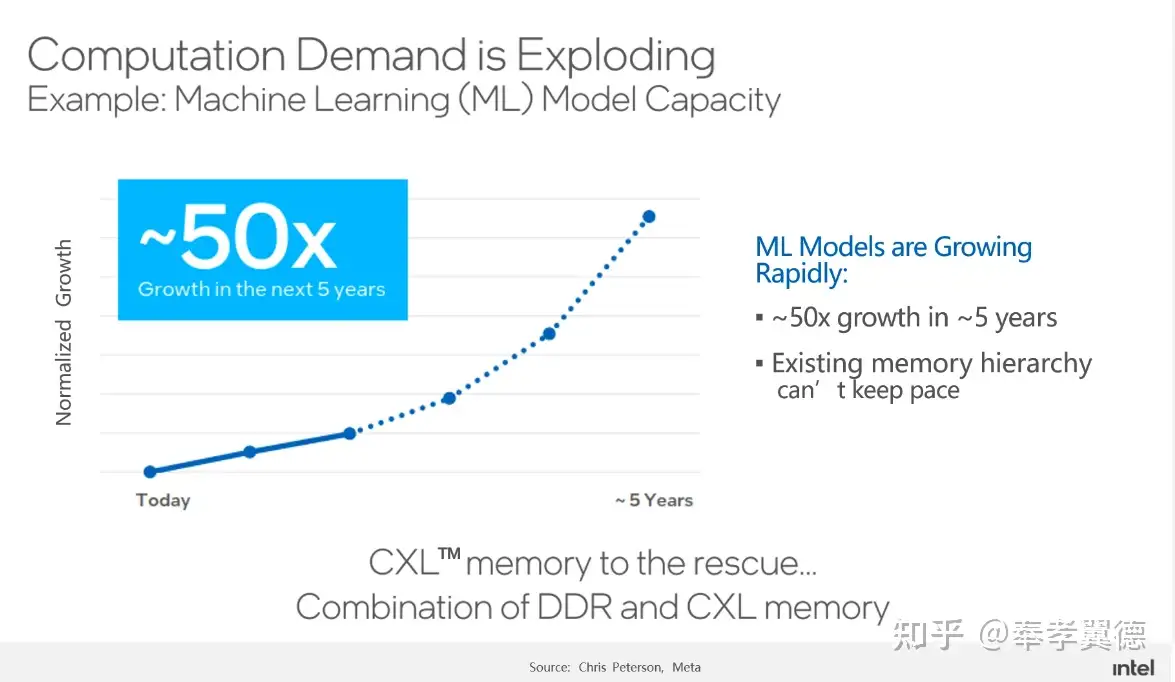
从现实应用的角度看,五年时间里,机器学习模型的规模增长了50倍,对算力的需求也在急剧增长,然而,现有的内存层级完全无法满足算力增长的需求,而CXL将是解决问题的关键。
那么,CXL是什么?CXL要如何解决问题呢?
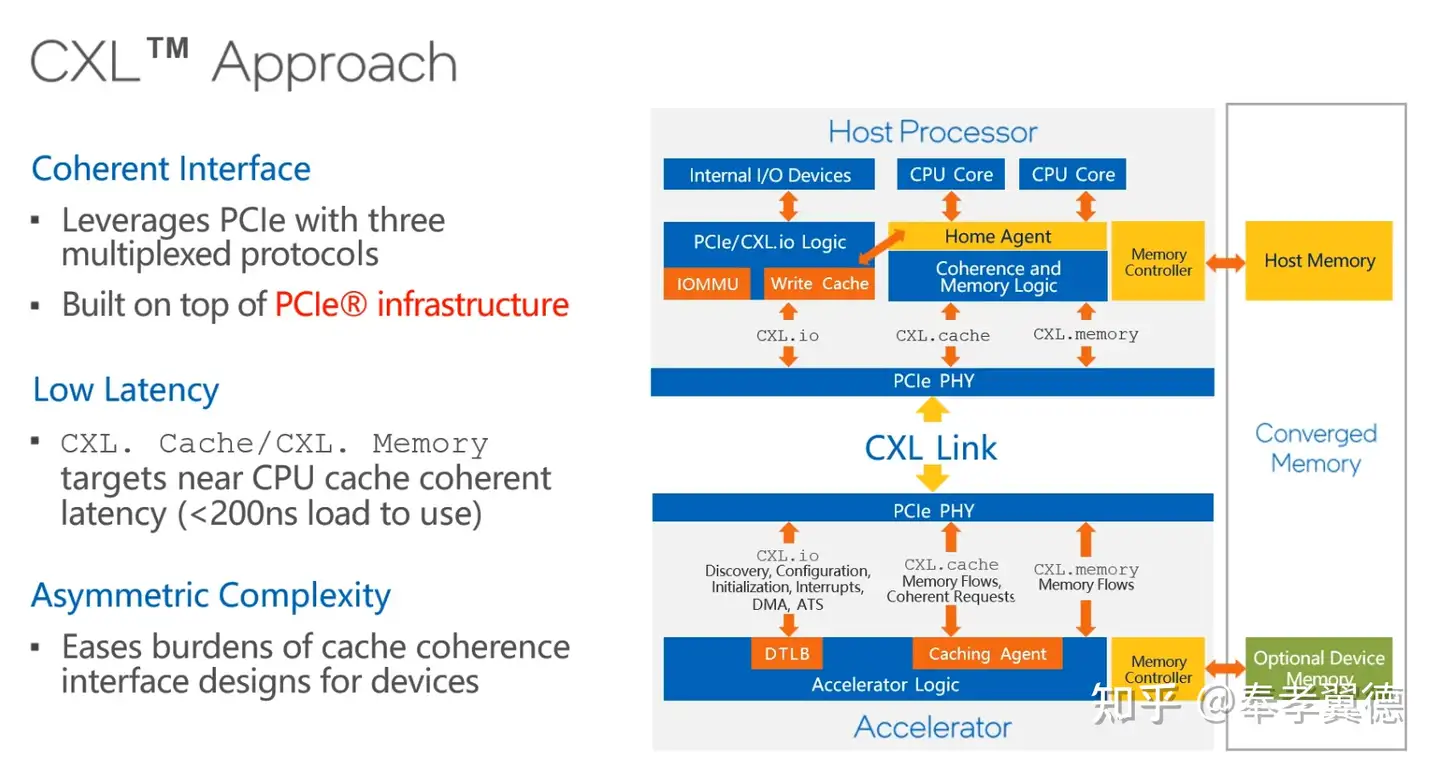
CXL有http://CXL.io、CXL.memory和CXL.cache三个协议:
其中,http://CXL.io就是原来的PCIe,在CXL的建立连接、设备发现、配置等过程中发挥重要作用,连接建立后,CXL.cache协议负责做cache一致性的工作,CXL.cache和CXL.memory配合起来用来做内存扩展。
CXL.cache和CXL.memory对于latency的要求会比较高,尤其CXL.cache对延迟要求非常高,因为这关系到计算的效率。
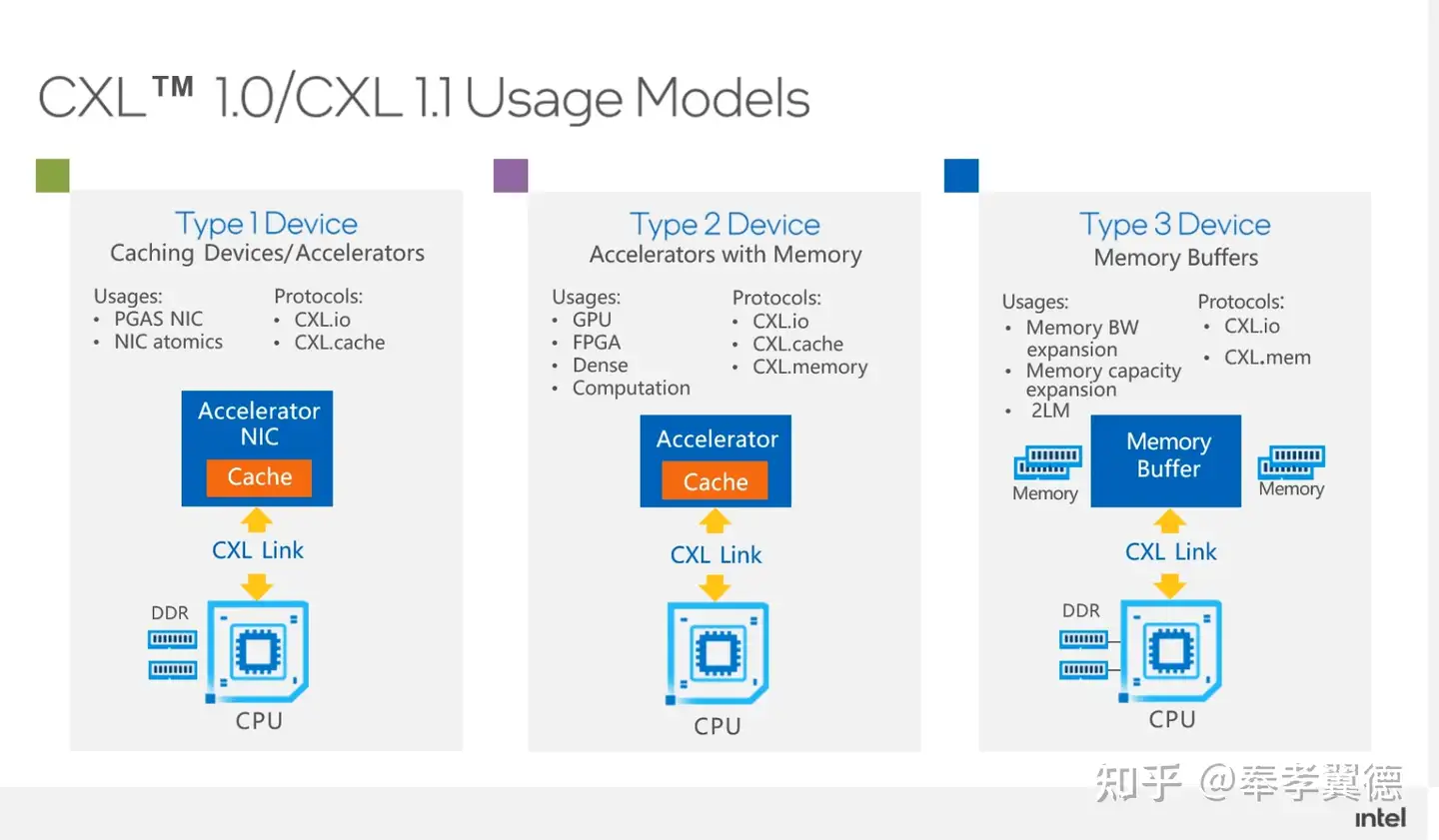
在CXL1.0和1.1规范定义了三种Device:
Type1Device主要的应用场景是高性能计算里的网卡(PGAS NIC),它支持一些网卡的原子操作,它主要利用的协议就是http://CXL.io和CXL.cache。
Type2Device主要指的是带有内存的加速器,包括GPU、FPGA等加速器,它使用的协议包括用来做链接的http://CXL.io,做cache一致性的CXL.cache,用来做内存扩展的CXL.memory。
Type3Device主要用作内存的Buffer,做内存的扩展。它主要利用http://CXL.io和CXL.memory的协议。如图所示,CPU除了可以用本地的DDR内存,还可以通过CXL去扩展远端内存,远端内存可以是一个大的内存池,这里的内存可以共享给不同的CPU来用。

CXL2.0规范实现了机架级别的资源池化。
云计算强调资源可以像水和电一样按需获取,云计算的技术潮流下,追求不同资源之间的松耦合,为的是提高使用效率,为了提高使用效率,要实现的是相同资源的池化。
随着技术的发展,未来的服务器不再是传统意义上的服务器,它不再具有现实的形态,用户从云服务商那里申请云主机的时候,主机的CPU是从CPU池里拿出来的,内存是从内存池里拿出来的,CPU池和内存池通过CXL连起来的。
使用从资源池里拿出来资源组成逻辑上的服务器,这就是资源解耦和资源池化在未来能带来的变化。
CXL2.0规范在资源池化方面有所强化,同时,也还增加了CXL switch功能,它可以在一个机架内通过一套CXL交换机构建成一个网络。
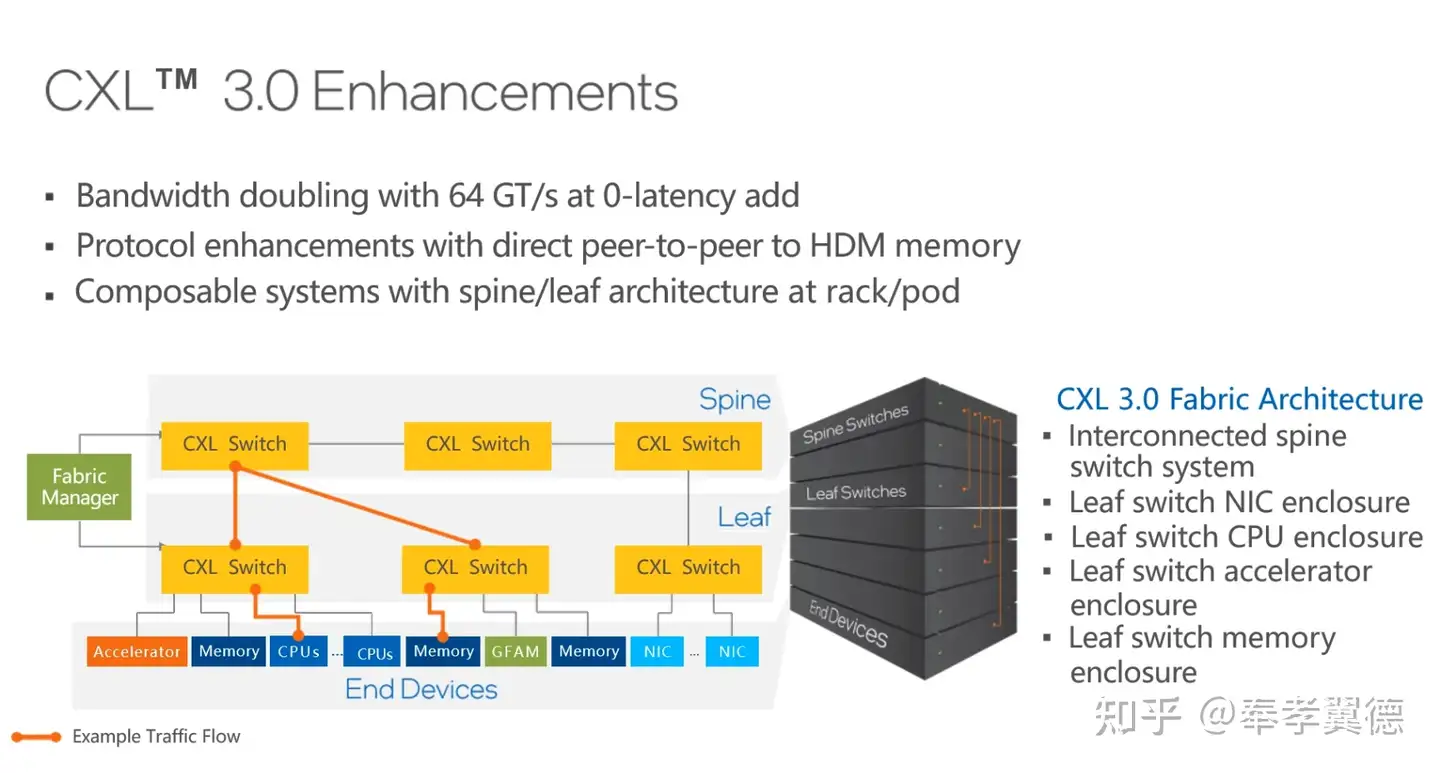
2022年,新发布的CXL 3.0规范又新增很多特性。
首先,CXL 3.0 PCIe 6.0规范,它的速率从32GT提升到了64GT,在相同的链路时,带宽翻倍。并且,Latency也没有任何变化。
第二,CXL 3.0新增了对二层交换机的支持,也就是Leaf spine网络架构,如此便可以更好地对资源进行解耦和池化,做更多的资源池,比如CPU资源池、内存资源池、网卡资源池和加速器资源池等,Leaf与Spine之间通过Fabric manager软件构建各种拓扑和各种路由方式。
CXL 3.0不但可以更好地在一个机柜内实现计算资源和存储资源的池化和解耦,而且,可以在多个机柜之间建立更大的资源池,如此一来,对于云计算服务商的资源管理效率和成本优化都会带来很大帮助。
CXL的未来发展方向
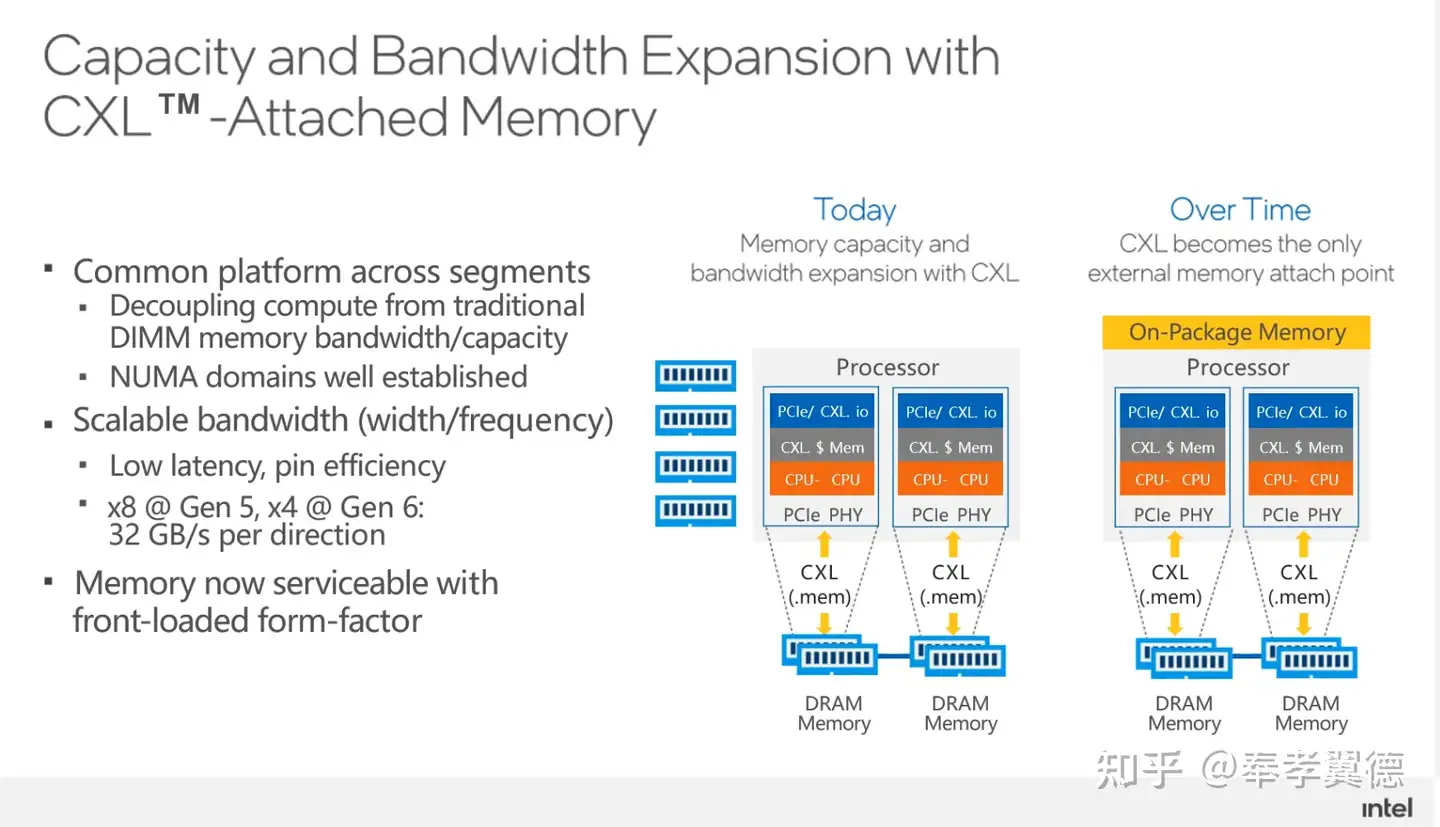
第一,用来扩展内存的容量和带宽,这是非常重要的一个方面。在使用服务器本地内存的同时,还可以通过CXL利用远端内存,远端内存的成本和价格相对更低,而且,它能让CPU和内存之间的配比变得更灵活。
进一步发展之后,未来完全可以取消近端本地内存,全部都使用远端内存,这有赖于摩尔定律的作用,让计算芯片和存储芯片都有更进一步的发展。
与此同时,CPU上会有比DRAM更高速的内存,比如可能会把HBM与处理器封装到一个die里,使得CPU有更多的高速内存。
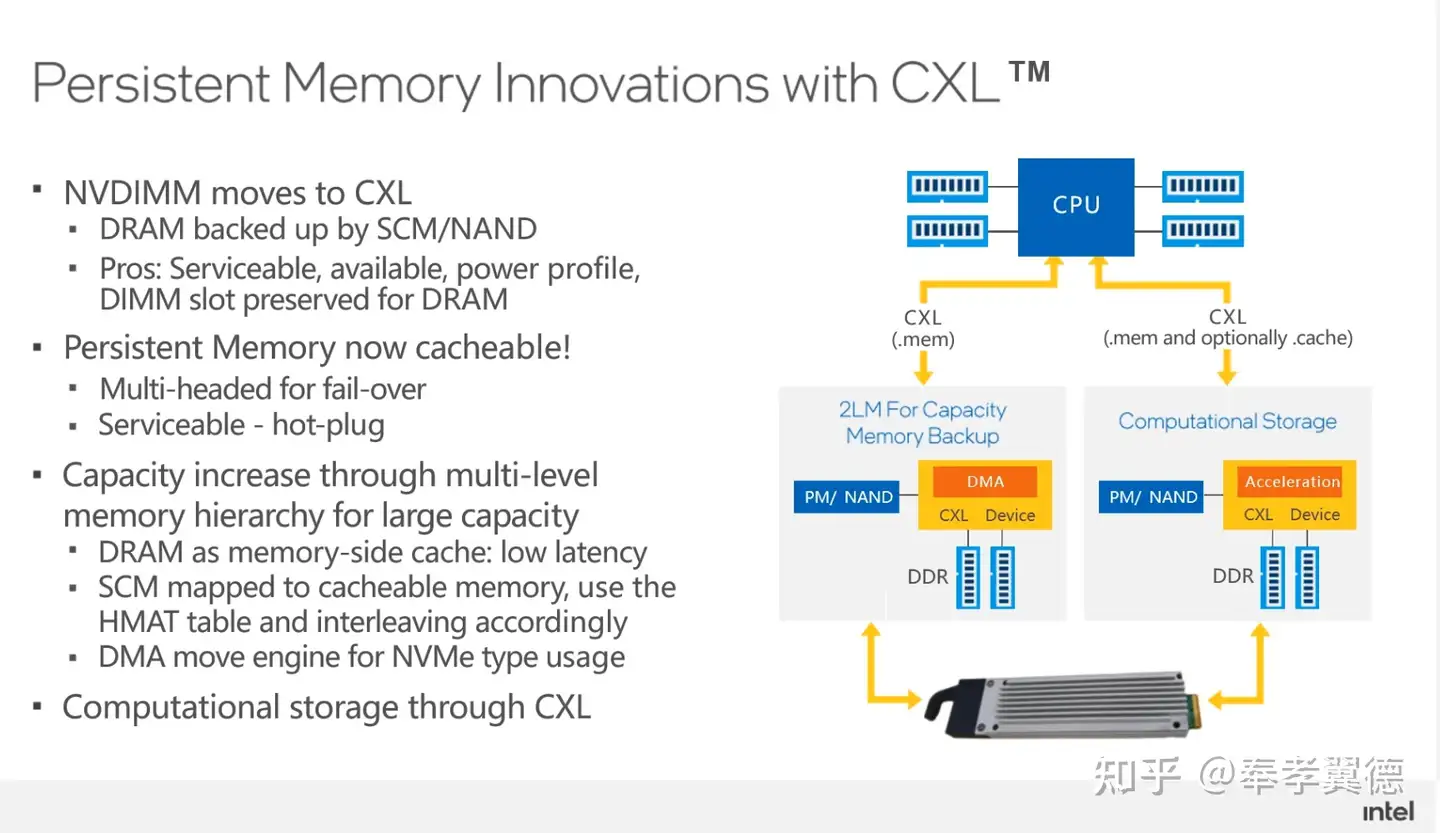
还有一个趋势在于远端内存的持久化,目前,英特尔就有傲腾持久内存,但因为一些原因,英特尔宣布不再继续研发了,不过,业界还有很多替代方案,比如NVDIMM,配合CXL将这些持久内存作为远端内存,还能够提供多种实用功能。
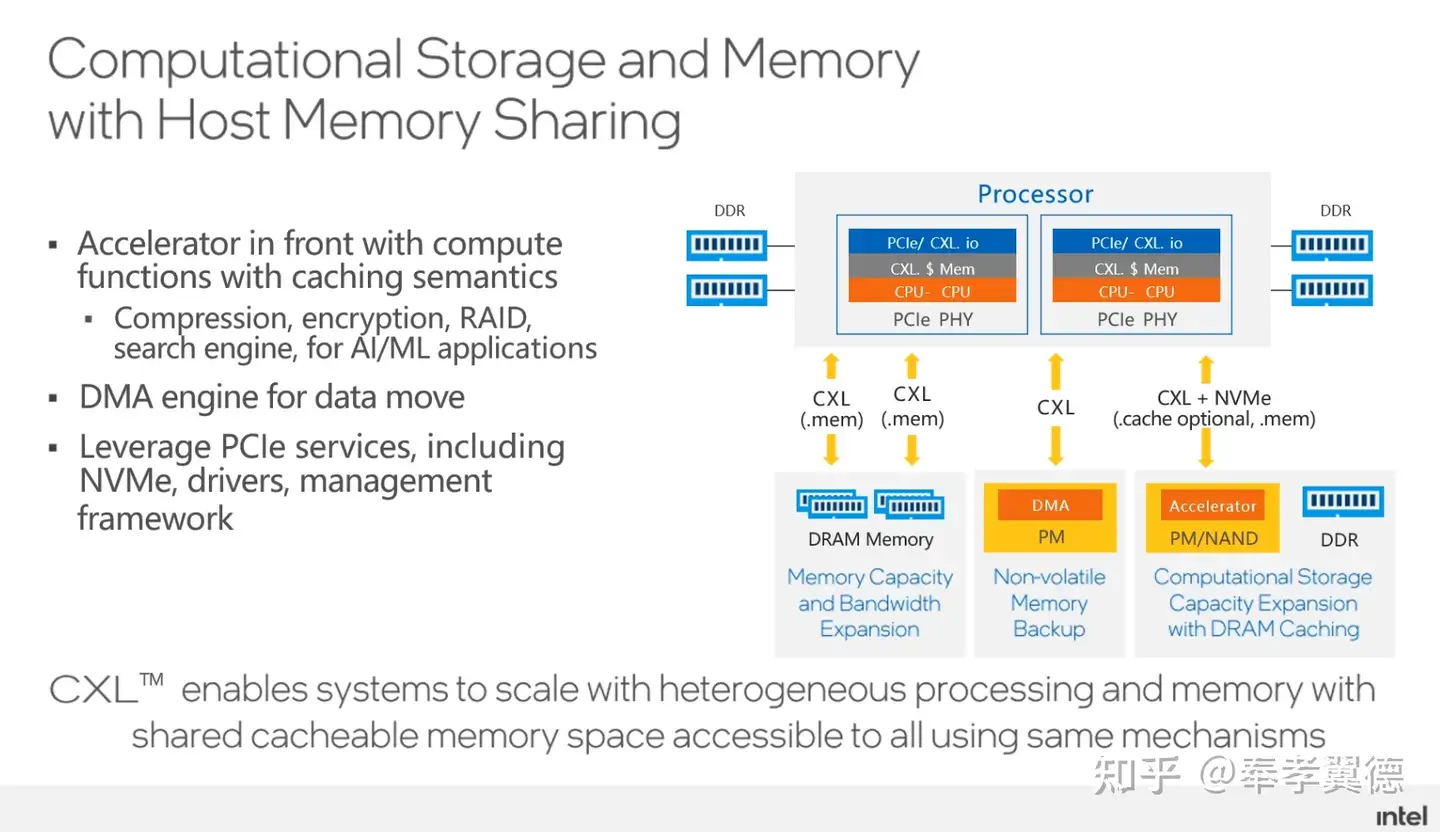
除此之外,还能利用CXL技术实现Computational Storage,通过CXL利用内存资源,在存储上做一些压缩或者解压缩的操作,类似可以在远端实现的功能还有很多。
CXL带来的改变从单节点开始,扩展到机架规模,而后是Tor级别,最终会影响到数据中心级别,CXL将要重构未来的数据中心。
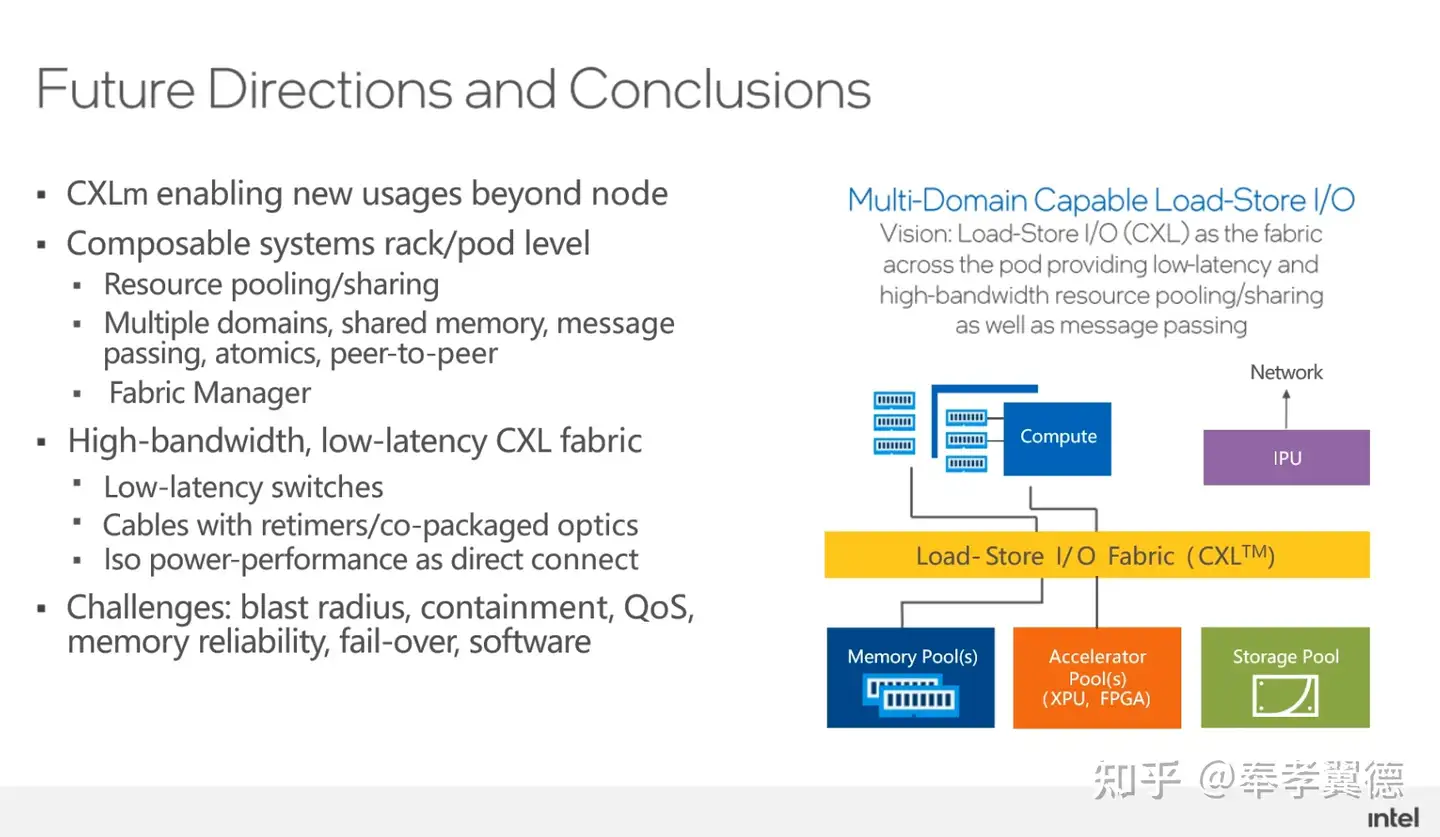
数据中心利用CXL做解耦和池化,CXL技术能够让不同的资源从紧耦合变成松耦合,让相同的资源变成池化资源,会形成CPU资源池、GPU资源池以及内存资源池,各个资源池通过CXL连接。
在未来发展中,随着CXL技术的逐步落地,IPU承担的任务也会越来越多,既作为CXL的端点,又作为以太网的端点,会有很多功能和负载卸载到IPU上,架构上会有很多变化,将会有很多新的创新。
比如把存储offload到IPU上,未来还有一些块存储或者其他内存相关服务也都可以用IPU来承载,通过CXL连接到相应的资源池上,总之,未来有非常多的想象空间。
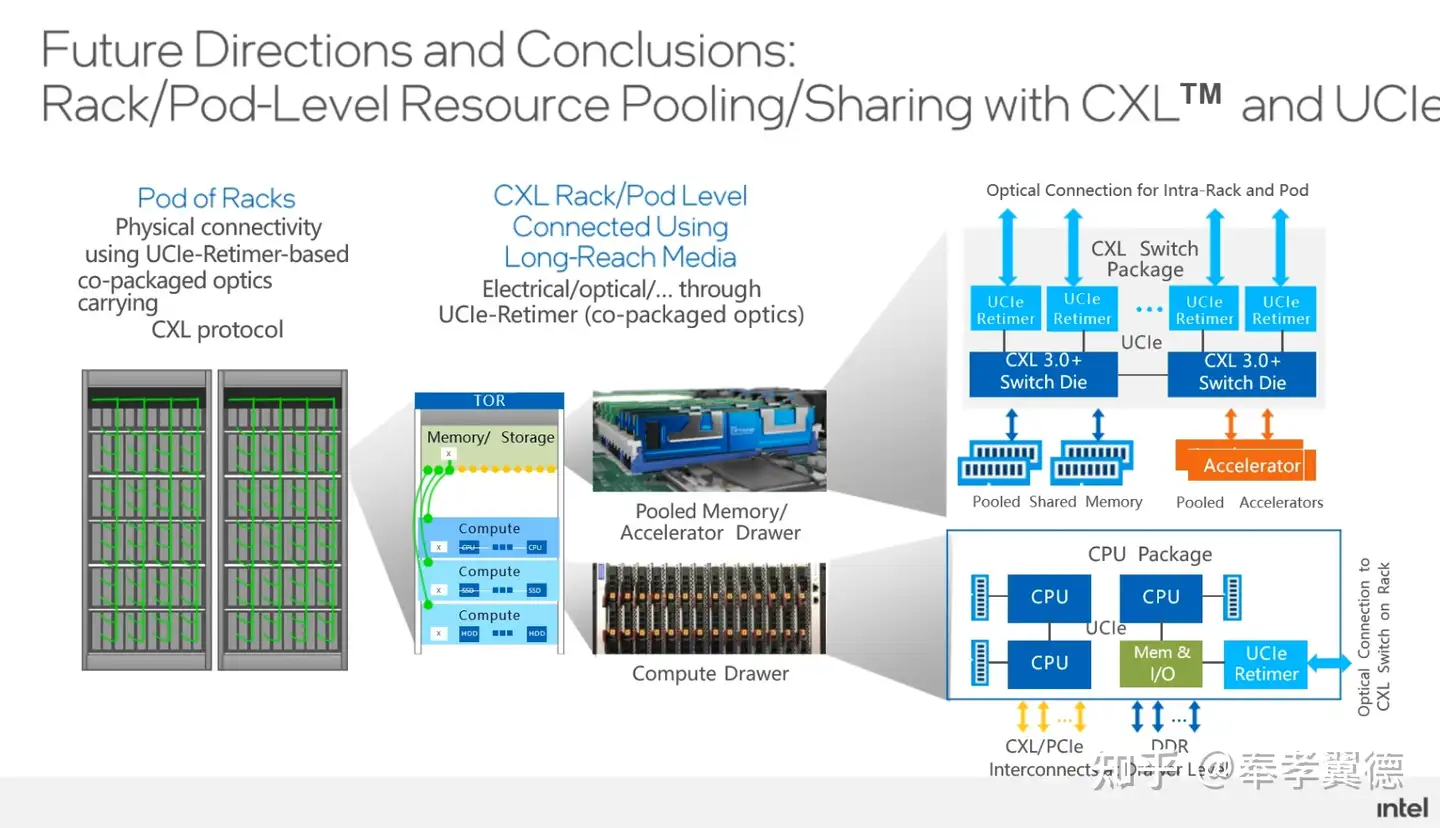
作为总结,不得不说的是,未来的发展方向中,最终就要实现彻底的解耦和池化,过程是逐步从Rack级别,提升到资源池的级别,甚至是数据中心级别,而这些池化资源之间的共享就靠CXL和UCIe来实现。
本文来源于DOIT传媒,文章内容仅供参考,不构成投资建议。


评论列表