错过了电商,错过了微商,错过了自媒体,难道你还要错过XXX吗?经典的微商语录换成机器学习竟毫不违和,毕竟很多人说机器学习将来是要抢人类饭碗的,如果不能拦住机器,那么不如加入他们。
自我介绍:我的pre-ML之路
先自我介绍,我目前是一名IT网站编辑。在学校读的电子专业,毕业实习自学Java、C#编程,只做了一年程序员就改行做编辑工作,已经7年多没有以编程为主业了。
人工智能的火热,想转行人工智能的人真不少,过去一两年里,我看到许多人都成了人工智能、机器学习专家了,朋友圈里,微信号里,全是教你入门人工智能的海报,扫码看看介绍,再看看价格,便宜的三五十,贵的好几千,想入人工智能的门,先交了钱再说,优质课程确实有,但骗钱的更多。
当然,对ITer来说,不能说人工智能,要说机器学习(ML)才有范儿。
好不容易碰到优质内容,耐着性子看完的人却也不多,更尴尬的是,居然有人学了几个月,连一个基本的模型都没有训练出来,不是没有配置好环境,就是代码运行出各种Bug,调试半天最后还是以失败告终,机器学习果然还是挺有门槛的东西啊。
曾经,我凭借中学时代折腾电脑积累的电脑常识,按照网上教程搭建了机器学习环境,并根据别人提供的代码和数据训练出了机器学习模型,不过,前后花了不少时间。
因为,这期间,我学习了几天速成的Python编程语言教程;我认识了Jupyter Notebook,Tensorflow,Anaconda,CUDA等软件和方案;知道了机器学习的一些基本原理;了解了几个常用算法;也知道了拟合、过拟合等专业术语;当时,最大的感想居然是:数学还挺有用的,数学老师,我错了!(PS:为此还花重金购买了猴博士的大学数学课程,有挂科倾向的同学可以关注下这个推荐,不谢)
总起来说,过去几年,我业余时间学习了机器学习课程,了解了一些基本概念和基本操作,但还远没有入人工智能的大门。
Amazon SageMaker把入门机器学习的门槛降到了最低
直到遇到Amazon SageMaker,才发现自己绕了大圈子,想训练一个模型根本不用这么麻烦!
作为AWS的Free Tier用户,个人觉得AWS的控制台友好度比较高,所以,我满怀期待地打开了Amazon SageMaker,印象比较深的是,这里有已经安装好的Jupyter Notebook (笔记本)还有各种机器学习常用的库,做训练时需要把数据传上来,把代码传上来就行,这里的计算资源要多少有多少。
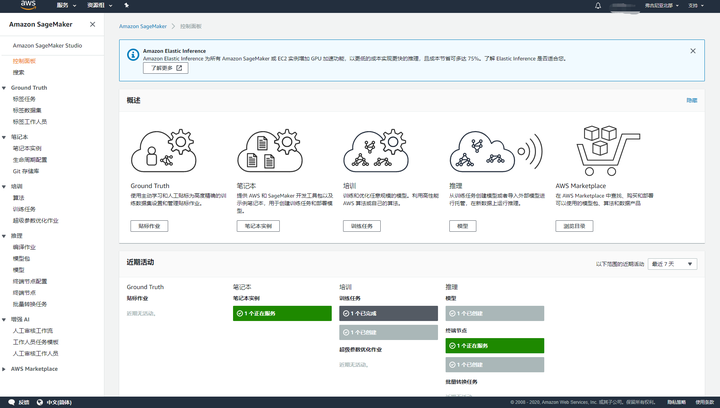
截图中的是海外区域的版本,与中国区的版本差别不大,4月30日,中国区的SageMaker也正式开放,而且,我还嗅到了羊毛的气息,真的有有免费套餐可用,AWS 中国(宁夏)区域提供一个月免费套餐,看完我的简短体验后,马上就可以免费体验了(薅羊毛了)。
对我来说,Amazon SageMaker不能把我这样什么都不懂的人变成机器学习专家,但Amazon SageMaker真的可以降低机器学习的门槛。
由于很多机器学习相关的工具都不够成熟,经常存在兼容性的问题,这些工具不能像安装手机应用那样一键安装和运行,用起来很不方便,还经常有各种Bug。在人人都得学点大数据技术,学点机器学习技术的时代,这些局面一定会改变,但需要时间。Amazon SageMaker的出现是为了改变这一局面。
在Amazon SageMaker这里,用户只需要带着自己的算法和代码,以及准备好的数据,就能在这里开始训练并部署模型了,看起来就像拎包入住。即便是没有自己的算法和代码,也没有数据,也可以和我一样利用SageMaker自带的demo体验一把。
动手吧,零基础小白用十多分钟训练一个模型
话不多说,赶紧和我一起动起手来,用十来分钟体会训练并部署机器学习模型的过程吧。
示例代码非常简单,它使用的是非常简单的K-means聚类算法和非常常见的mnist数据集来做一个手写体识别,说简单点,就是识别手写图片里0到9这十个数字。我要做的就是打开一个带有代码的笔记本实例,一路Shift+Enter就能完成训练,然后……然后就结束了。
2018年的时候,我曾经用SageMaker的笔记本实例训练并部署了一个模型<2018年旧稿子的链接>,经过两年的发展迭代,SageMaker有了许多新的功能,所以,这次我试着用全新发布的SageMaker Studio重新走一遍当初那个超级简单的机器学习训练过程。
如果您对于机器学习的训练过程有一点点好奇,可以看看这几张截图,如果对具体步骤不感兴趣,可以跳过这些截图。
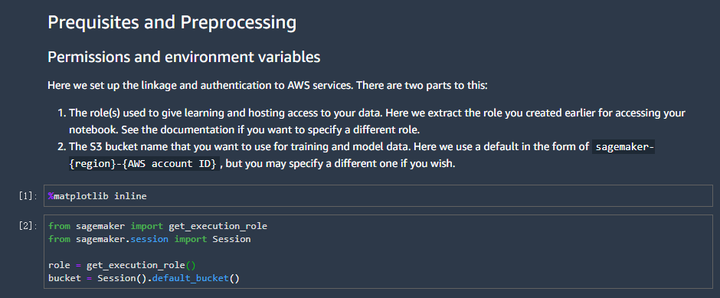
第一张截图的含义是:在SageMaker进行一些设置,这样就能访问AWS的各种资源了。
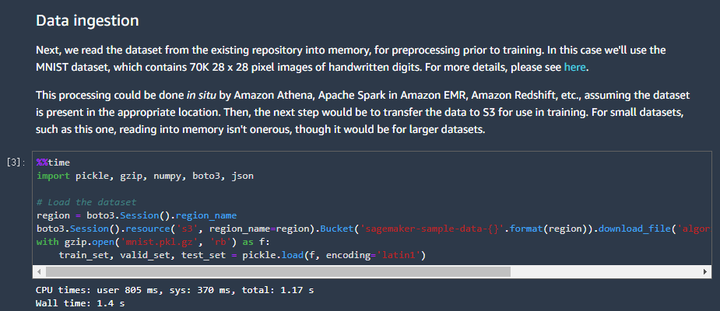
第二张截图的含义是获取需要用来训练的数据。这些数据非常规范,不用做任何额外操作直接就能来训练。
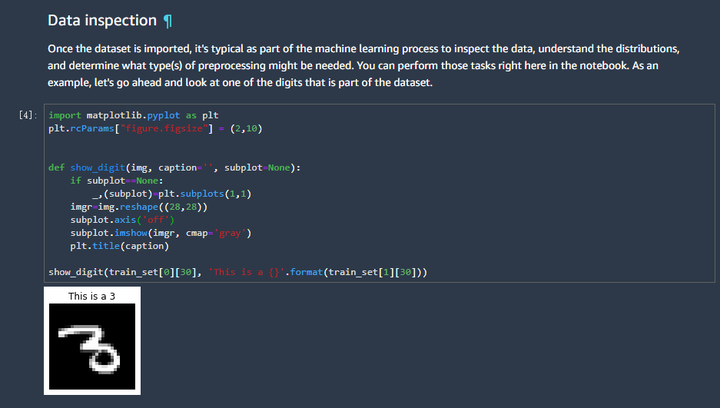
第三张图的含义是:观察数据集的特征,然后按照数据集的特征进行下一步的处理。
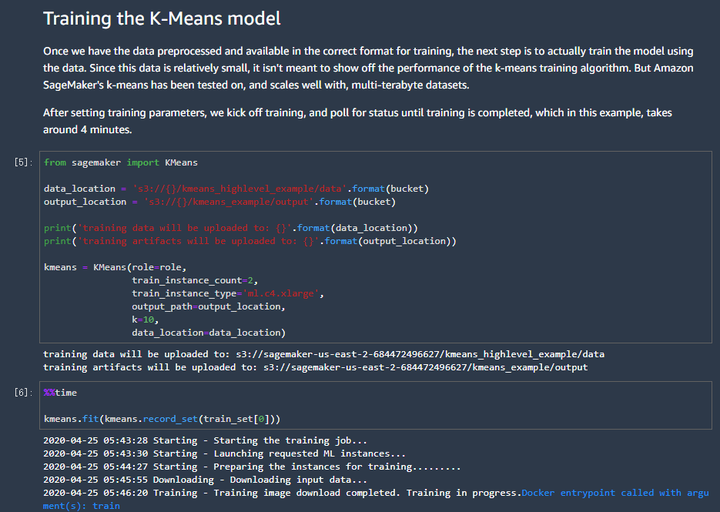
第四张图的含义是训练模型,由于数据集比较简单,算法也简单,很快就会训练出一个模型。

第五张图说的是训练完成了,训练时间大约花费了四五分钟。
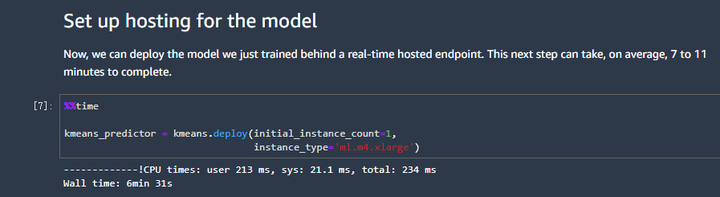
第六张图的含义是:模型训练完成后,要部署在线推理服务,设置需要运行模型的主机类型。
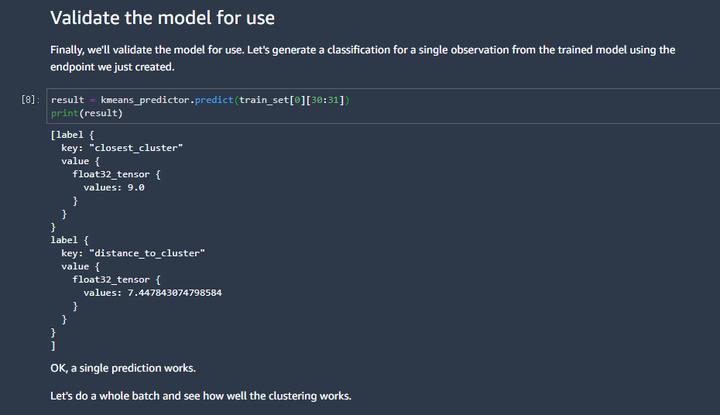
第七张图的含义是:做了一个验证,看看模型的准确度。不过,这里看的不是特别直观。
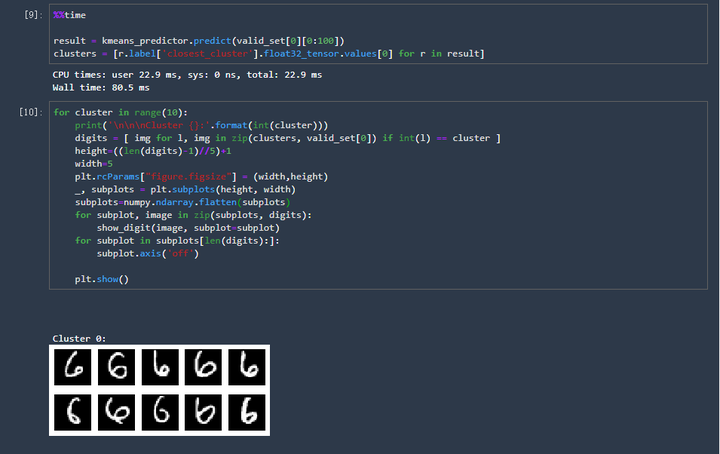
第八张图的含义是:做了一个分类,系统认为这几个数字的写的比较像,所以才放在一起。我们再多看几张图。

从上面两张图,我们的肉眼就可以大致感受到这个准确度。最后,记得删除刚才启用的主机资源,不然,一直运行着可是要一直扣钱的。
以上就是我训练一个简单模型的全部过程,可以说不能更简单了。唯一的门槛就是,你最好认识几个常用的英文单词,不然会觉得过程有点无聊。
所以,以上就是SageMaker的一些主要功能了。
SageMaker非常适合那些需要实验算法和调参数的人。比如,你突发奇想,想去试一个新算法,但身边的电脑性能太差了,而且电脑上的工具经常出问题,有了SageMaker之后就没有这些麻烦了,只要你有代码和数据,完全可以在这里用完即走。训练速度很快,成本也不高,起码不用买动辄好几千甚至上万块钱的显卡。(PS:万一发现自己不适合机器学习,这显卡出二手可就……请联系我。)
进阶需求:Amazon SageMaker Studio把该做的都做了
我曾在个人电脑用LSTM网络训练一个古诗生成的模型,训练次数少的时候,模型给出来的唐诗看着很别扭,训练次数多起来看起来会自然一点,当然,内容并没有什么含义。前者几分钟就训练完成了,后者则花了一个晚上,我如果想改变其中一个参数,那么就需要再训练一个晚上,让电脑嗡嗡响一晚上,而且希望不要意外关机,不然前功尽弃啊!
数据科学家训练一个复杂的模型,一次训练可能需要好几天,一次训练只能说明一次算法或者参数的表现,如何证明算法和参数合适不合适则需要N多次的训练。如果每一次尝试都要等上好几天的话,那么,那么数据科学家的工作也太轻松了吧!如果5天出一个结果,训练1万次,那这个项目大概需要两代人前赴后继。orz
以前,虽然Amazon SageMaker已经有很多功能可以加速训练过程,但对于用户的调参和优化算法使用还没有那么方便,而这,恰恰是真正需要的东西,要知道,除了准备数据,数据科学家们绝大部分时间都在改算法和调参数。
AWS去年十二月又推出了Amazon SageMaker Studio,集成了多个功能。这里我挑几个我个人觉得有意思的介绍一下:

Amazon SageMaker Experiments主要就解决了多次实验迭代管理这个问题,它可以帮你跟踪、记录和比较数千个机器学习任务,包括任务的里数据集,算法还有参数,模型,平台配置,参数设置等,都能通过图形或表格的方式灵活观察迭代变化的情况,对比一下看哪个表现最好,调出表现最合适的模型。系统自动记录,再也不用手动记录了!一会儿我们可以试试这个功能。
另外,我还发现Amazon SageMaker Studio还有一个非常实用的协作功能。当你调参或者改代码的时候碰到问题了,想请教别人解决,但是你不能把你电脑搬过去,也没办法要求别人配置一套跟你完全一样的环境,也不方便把AWS账号给他,那怎么调试呢?最好的办法就是加入协作机制,给你直接用我的环境,你看到的东西跟我看到的完全一样,所见即所得地就地解决问题。这协作效率~
Amazon SageMaker Studio是一个在线的IDE(集成开发环境)工具,IDE常有的功能他都有,包括Debug和在线监控等等功能,Amazon SageMaker Notebook也包含在其中。Amazon SageMaker Notebook可以说是Jupyter Notebook的加强版,它在Jupyter Notebook基础上做了许多强化。
个人觉得AWS的Amazon SageMaker Debugger功能非常良心,它能提前发现超参数的问题,如果没有它,超参数有问题在训练任务运行期间不会暴露,训练完之后可能会发现,如果能在早期发现问题的话就不用白等了。
Amazon SageMaker Studio最受我这种新手菜鸟推崇的功能可能就是Amazon SageMaker Autopilot了,它可以自己做数据预处理,自己选择算法,自动调整模型,自动调用各种计算和存储资源。是自动化的机器学习功能,是一个让机器训练机器的功能。当然,目前还是有一定局限性的。
初体验:体验SageMaker Studio自动化的机器学习
带着满满的好奇心,我试着用Kaggle上下载的“泰坦尼克号获救”数据来进行自动化的机器学习,我这样啥也不懂的也体验了一下自动化的机器学习。出乎意料的是,整个操作过程还非常简单!
如下图所示,我先把下载下来的数据传到了S3上。(原版的数据只有891条数据,SageMaker Autopilot要求最少得有1000条数据,于是,我手动复制了109条数据,测试才得以进行,这个操作非常不推荐,但为了体验自动化的机器学习,就这样吧)
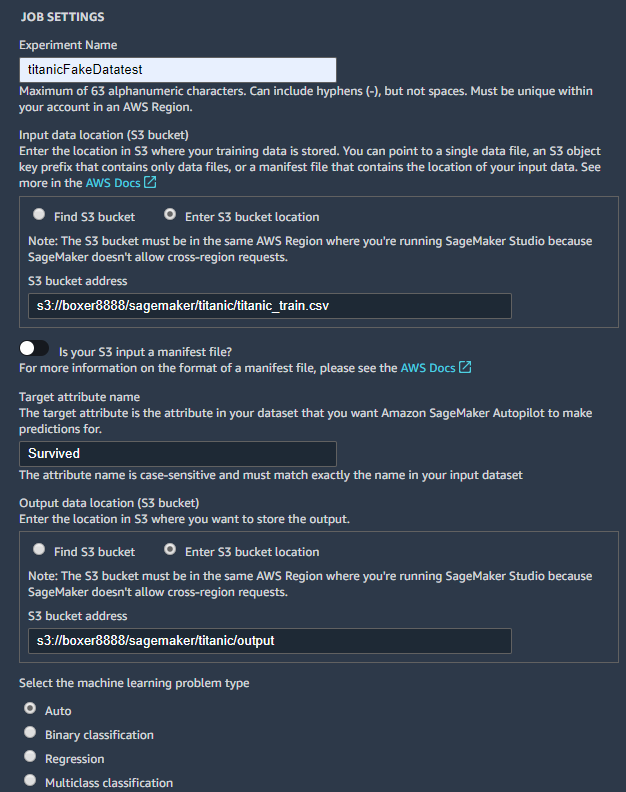
我指定了训练数据(S3存储中里的csv表格)和要预测的参数(Survived-获救与否)后,点确定之后就什么都不用管了。
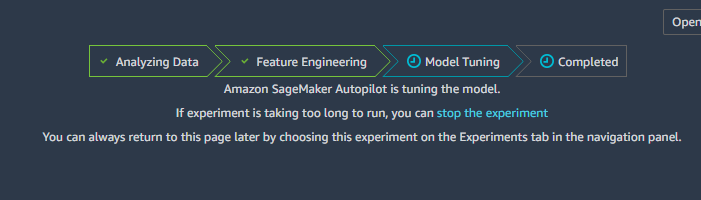
如上图所示,整个过程需要经过上图所示的四个阶段。所有操作,包括数据预处理,选择算法还有调整参数的操作都由系统自动完成,缺点是等候的时间比较长。
看到这里,其实整个体验就完成了,如果您对于自动化的训练过程有兴趣,也可以接着往下看几张截图。
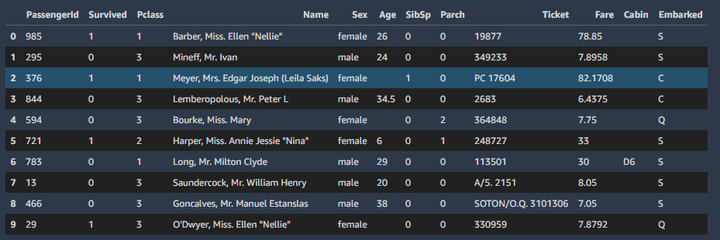
等待中我还看到我提供的数据的概况,我的数据其实还需要进行处理,Autopilot会自动进行数据预处理,有朋友可能会好奇,听着挺高大上的,啥是数据预处理呢?
举个栗子:如上图所示,“Age”部分有的数据是空的,要进行运算的话,必须以合理的方式把数据补上,类似的,字符串数据也要处理掉。总之,数据预处理还是挺麻烦的,是个时间黑洞,还好Autopilot能自己搞定,幸福感up!up!
当进行到参数优化的模型调优阶段后,会看到Objective目标值,也就是模型预测的精准度在不停的变化,虽然不一定下一个就比上一个好,但大体上,目标值是在不断提高的。
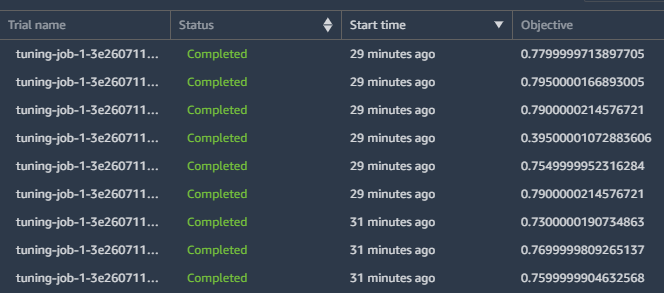
所有操作都是自动完成的,大概等了两个小时候后,训练终于完成了!
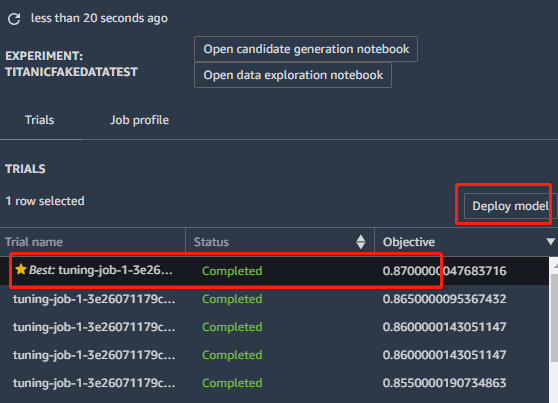
本次体验,在SageMaker Experiments的自动化的参数优化过程中,一共训练出了250个模型(要是手动训练250次,会不会疯?),最后选一个模型进行部署即可。那么,选哪个模型呢?下图中,SageMaker Experiments会自动给你标注出来哪个是最好的!是不是很贴心。
结语
通过上述经历,我想说,亚马逊云服务(AWS) 的Amazon SageMaker对于想成为数据科学家的人非常实用,希望本文对想了解它的人能有所帮助。(更多动手体验类文章可查看微信公众号:云体验师)