
2019年4月份,英特尔发布了傲腾数据中心持久内存,这是一款具有字节寻址能力的非易失性内存,能被操作系统识别为主内存,英特尔表示,作为主内存其性能表现与DRAM内存相近,究竟有多相近呢?
最近,日本国家先进工业科学技术研究所(AIST)发布了一篇Paper,非常细致的将傲腾持久内存与DRAM内存进行了一番对比,测出傲腾数据中心持久内存延迟是DRAM的四倍。
简介:傲腾数据中心级持久内存
值得小伙伴们注意的是2019年发布的傲腾数据中心持久内存(Optane DCPMM)跟2017年发布的傲腾内存(Optane Memory)可不一样。
傲腾内存(Optane Memory)是插在PCIe NVMe接口上的,而傲腾数据中心持久内存(Optane DCPMM)是插在DIMM上的,如果设置的是App Direct模式的话,CPU就完全把他认作主内存了。
众所周知,傲腾是基于3D Xpoint介质的,3D Xpoint是英特尔跟美光联合研发的产物,在英特尔手里,傲腾被打造成介于低成本NAND和有易失性的DRAM内存之间的方案。
傲腾发布以来引起了许多OEM厂商的兴趣,不过,目前傲腾只能支持自家的处理器,所以测试也选用的是至强处理器。
测试前的操作
测试中研究人员发现,大部分的CPU架构都会预先获取内存,然后进行乱序执行,以此隐藏内存的延迟,为了测到真正的主内存延迟,测试人员进行了很多操作:
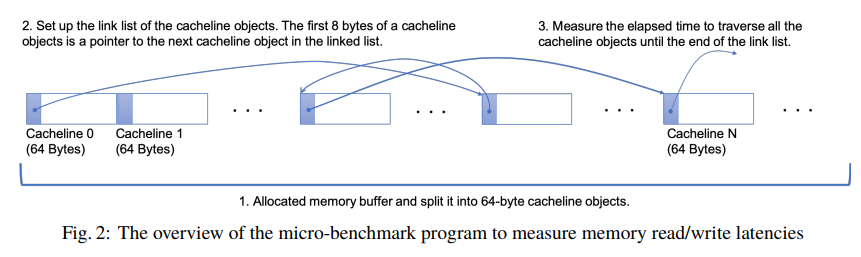
首先,从目标内存中分配一定数量的内存缓冲区,为了不命中LLC,分配的缓冲区要尽可能的大,至少要大于LLC。内存缓冲区拆分成了64字节的cacheline。
其次,将cacheline缓存线对象链表进行随机排序,这样一来,遍历链表会导致跳转到远处的cacheline对象。
第三,测量遍历所有cacheline对象所用的时间,并计算获取cacheline的平均延迟。在大多数情况下,CPU在遍历cacheline链表时候,如果没有命中LLC会有短暂的暂停,这段时间算作是内存延迟。
测试结果
经测试后,AIST在Paper中表示,目前关于傲腾数据中心持久内存的性能报告很少,傲腾数据中心持久内存与DRAM的性能差距很大,相对于NAND的提升也非常大。以下是一些结论:
测试中,AIST使用的是自己的测试工具,测试发现傲腾数据中心持久内存随机只读延迟大约为374ns,随机写的延迟大约是391ns。只读带宽为38GB/s,写带宽为3GB/s,如果不开启内存交错(memory interleave),性能会差很多。
AIST认为,像大型HPC集群,AI工作负载等将从傲腾持久内存受益良多,但DRAM和傲腾持久内存之间的性能差异给系统软件带来了新的挑战,这也是傲腾推广普及中碰到的最大问题之一。
下图有一个比较清晰的对比:
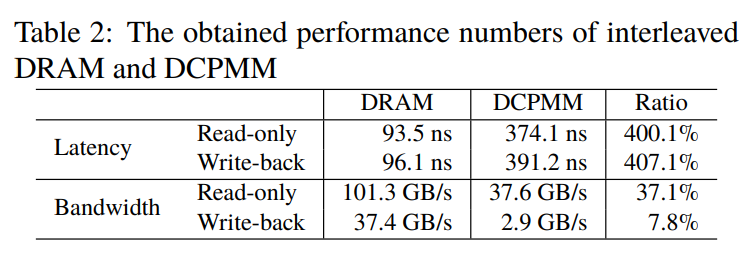
上图非常直观的对比了DRAM内存和傲腾持久内存的性能差异,延迟上傲腾是DRAM内存的四倍,四倍起码还在一个数量级上。但我们也知道,这比毫秒级别的SSD们可快的多了去了。(1毫秒等于1百万纳秒)
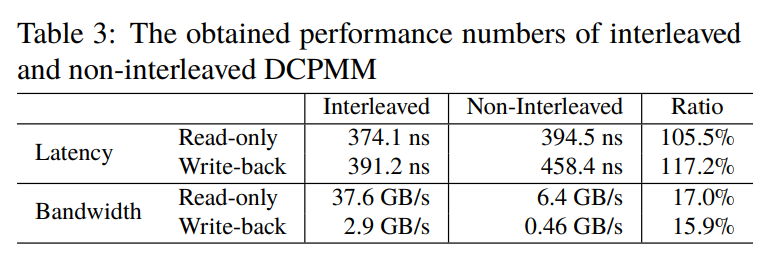
傲腾数据中心持久内存开启内存交错和不开启的差别
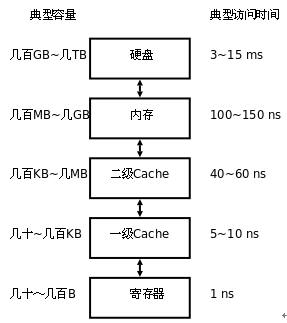
计算体系各层级之间的延迟概况(供参考)
这张Paper技术细节比较多,想看更多细节或者怕被小编误读,最好还是看完整版报告: https://arxiv.org/pdf/2002.06018.pdf 。 (DOIT朱朋博)







