人工智能毫无疑问是当前最热的商业话题之一,从上层的语音识别、翻译及机器学习,到Python等适用于深度学习的语言以及各式算法,与人工智能相关的议题总不缺乏热度。人工智能潜力巨大,但是万丈高楼平地起,任何一个人工智能的算法或者系统都需要一个高效的底层平台进行支撑。
深度学习:算法是灵魂 基础架构是引擎
深度学习是人工智能最广泛的应用领域,它使用高性能计算机识别海量数据中的模式和关系。算法可以说是深度学习的灵魂,训练模型、处理数据的方式都由算法定义,而算法需要在基础架构驱动下才能高效运作,基础架构也是整个人工智能的引擎。
2018年4月28日,HPE Apollo6500 Gen10服务器在全球发布,单台服务器最高支持8个NVIDIA Tesla GPU,支持PCIe与NVLINK 2.0的双重选择,并具备高带宽和低延迟的网络。HPE Apollo 6500 Gen10服务器由Gen9系列迭代发展而来,不仅全面继承了HPE在服务器上多年的设计经验,并且软硬件都进行了全面的升级。
随着这一新品进入市场,基于GPU的主流服务器在算力等参数上将上升到一个全新的高度,各类深度学习的场景也将有一个更加高效、易用、成熟的服务器选择。
Apollo6500 Gen10:
深度学习场景的最优引擎
业内领先的硬件配置与性能参数,加上HPE与英伟达在服务器及GPU领域的影响力,使得HPE Apollo 6500 Gen10系统成为人工智能领域最高端的引擎。不仅是GPU与计算架构进行了升级,要使得整个系统的性能不留瓶颈,就需要计算、网络和存储都使用最高性能的方案,HPE Apollo 6500 Gen10服务器在此三个方面有了诸多新的设计,所以可以从计算、网络和存储三个方面解读这一人工智能神器。

HPE Apollo 6500 Gen10前视图
首先是最高8颗GPU的计算架构,并且支持NVLink2.0,这是相比上一代产品的一个重要升级。简单的说,NVLink是一个能够在GPU-GPU以及GPU-CPU之间实现高带宽直连通讯的快速互联机制。单个NVIDIA Tesla V100 GPU 即可支持多达六条NVLink链路,总带宽为300Gb/秒,这是PCIe 3.0带宽的10倍。
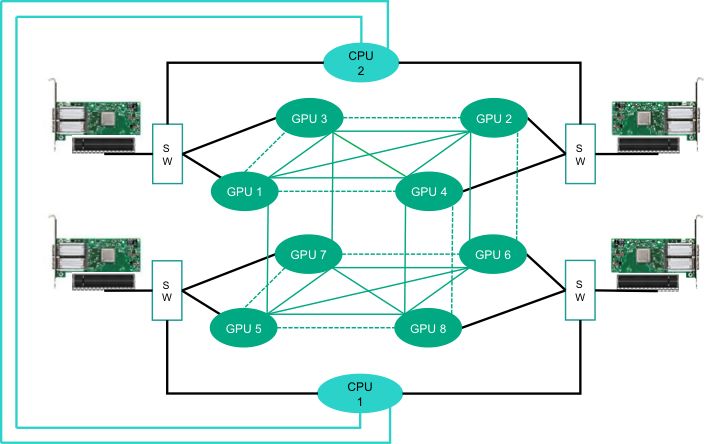
基于NVLink 2.0的超立方网格拓扑架构
采用NVLink2.0的高效混合立方网格是目前最为高性能的解决方案,不同的GPU之间通信带宽已经接近极限。另一方面,用户也可以使用基于PCIe的4:1或8:1的GPU:CPU连接。不同拓扑在高性能与易用性上各有优势,适用各种场景,用户可以根据业务模型灵活的选择。
网络层面,每台服务器支持多达4个高速适配器,除了以太网,还支持拥有更高速度的Omni-Path架构、InfiniBand EDR结构以及未来的 InfiniBand HDR,满足深度学习场景高带宽的需求。
存储层面,HPE Apollo 6500 Gen10支持NVMe SSD,相比SAS SSD,NVMe SSD拥有更高的带宽和更低的延迟,能够保障上层系统应用产生的数据第一时间下刷到存储层,避免存储成为瓶颈。
除了打通从计算到网络再到存储的整个链条上所有环节之外,HPE Apollo 6500 Gen10配备4个HPE 2200W白金电源(2+2冗余),并且每个服务器有5个热插拔风扇模块,提供坚实的供电、散热等保障。

HPE Apollo 6500 Gen10模块化设计
先进的核心计算架构、从计算到网络再到存储的高效模块化设计和精心设计的电源及散热系统,使得HPE Apollo 6500 Gen10不仅能够满足各类深度学习应用场景需求。高度易用性和灵活性,充分降低了构建高性能人工智能系统的门槛,企业可以在HPE Apollo 6500 Gen10构建的坚实基础架构上以最短的时间完成对各类算法的训练。
中国区作为HPE Apollo6500 Gen10服务器首发地,人工智能市场前景广阔。互联网、金融、制造等多个行业,全球市场也需要HPE Apollo 6500 Gen10这样的高速引擎以布局未来,迎接人工智能时代的到来。