
新一代Sandy Bridge核心将改变GPU理念
相比之前,英特尔这次将大幅度增强Sandy Bridge的图形核心性能。而增强的主要部分,总体上是现在的"GPU核心"化。换句话说,随着NVIDIA和AMD逐渐都朝着GPU内核的方向发展,英特尔也开始朝着相同方向迈进。不管是英特尔过去的特有架构,还是和其他公司合作的众多架构都将面临着巨大的改变。
简而言之,就是特别重视低成本化,英特尔的CPU已是普遍销售了,但图形核心还没达到此种程度。这是因为其性能效率以及程序通用性都比较弱。与此相反的是,Sandy Bridge的图形核心比较注重GPU性能和电源效率之间的成本比,更多的考虑了通用性。
Sandy Bridge图形核心的目标在于,将较高的3D图形性能和面向通用计算功能,以及有效进行媒体处理组合为一体。具体来说,(1)固定在处理器上的功能单元组合保证了3D图形的有效实现,(2)补充面向通用计算和媒体处理的指令和功能,(3) 由此强化媒体处理的固定功能单元。这些的改进将从新一代Sandy Bridge开始。
这些改进多半是为了跟进其他公司在GPU内核上的发展。而英特尔独有的部分与其他公司的GPU内核技术上还存在着许多差距。英特尔在其9月举办的英特尔信息技术峰会(IDF)上已做过简要的说明,从其说明看来,传统英特尔图形的弱点还是显而易见的。而NVIDIA和AMD的GPU的优势也是相当明显的。
基本的整体架构继承了传统的英特尔图形核心
Sandy Bridge图形核心的整体架构遵循了英特尔传统的内核架构。下图是根据英特尔的基本描述而得到的标准GPU结构图。利用这样的方式可以清楚地说明英特尔所保持的大框架相关内容。

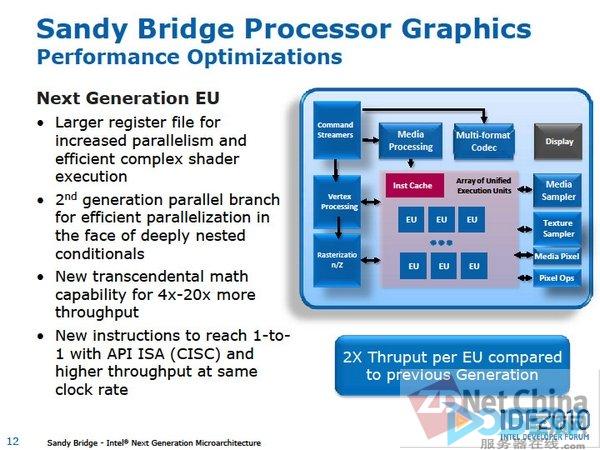
Sandy Bridge图形内核的整体架构
图上方的排列是3D通道和控制单元群。这些图形通道顶部是必要的像素处理单元,可进行早期的Z检验。
Intel架构中的各个处理器被称之为"EU(执行单元)"。如果要计算Intel图形处理器的数量,一般以EU来计数,EU实际上就是SIMD(单指令多数据流)型的运算处理器。
EU阵列右上角是媒体堆栈。除有固定功能的视频解码器, EU阵列还运行媒体处理和控制单元。
EU阵列右边是从内存中读取数据的纹理采样器处理单元。纹理采样器在内存中读取纹理以过滤3D图形管道,它为各个EU所共有。
纹理采样器内存(Sandy Bridge内部的环形总线)直接连接在总线的内存接口。传统的英特尔图形核心从缓存中读取纹理。从图中可推断,Sandy Bridge的图形核心可能采用了相同的结构。而核心的存储器层次结构则可能发生了变化。
另一个是媒体采样器,是媒体处理专用的过滤器。它也与系统内存接口相连,并有可能与纹理采样器共享。
此外,也像普通的GPU一样进行像素单位操作(ROP)。像素操作内存(Sandy Bridge内部的环形总线)也是与系统内存接口直接相连。
因此,Sandy Bridge图形核心具备了一般的GPU单元。而这一点,即使是同样的英特尔架构几乎也没有固定处理功能块,而软件处理器Larrabee就大为不同。Larrabee的光栅和ROP单元没有GPU所必需的功能块。
固定硬件的处理器运行EU的卸载
Sandy Bridge图形核心的基本结构遵循了英特尔传统的图形核心。而在3D图形和媒体处理方面却与传统存在着很大区别。这是处理器的软件处理等固定功能单元执行的硬件处理。
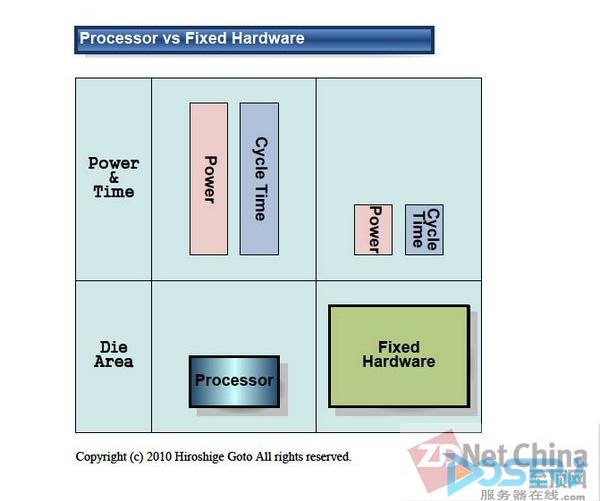
软件处理和硬件处理的比较
据说新一代英特尔集成显卡设计已在处理器EU的3D图形管道中模拟了许多内核程序的固定处理。英特尔表示这是为了减少图形核心的晶片面积。减少固定单元所占有的晶片面积,可降低核心的可编程单元。
这种方法使得每晶片面积的性能有所提高,但在电力消耗方面却表现不佳。通常,固定功能单元功耗最低,而可编程处理器功耗更多。因此,传统的英特尔图形核心每瓦的性能决不会很高。于是,3D图形管道的固定功能基本是封装在固定硬件上。
英特尔研究员兼图形架构总监Thomas Piazza 表示:"过去曾考虑过每部分管道是否可以运行程序,如果可能的话,将会被设计用于运行程序。然而,Sandy Bridge考虑是否需要运行程序,如果没有必要,将通过硬件封装固定功能来实现"。
卸载固定硬件的驱动程序
处理器运行的同时,也尽可能多的卸载固定功能单元。这是优先考虑吞吐量和电力效率的常规性方法。这样一来便可提高图形处理的电源效率,降低延迟,增加吞吐量。
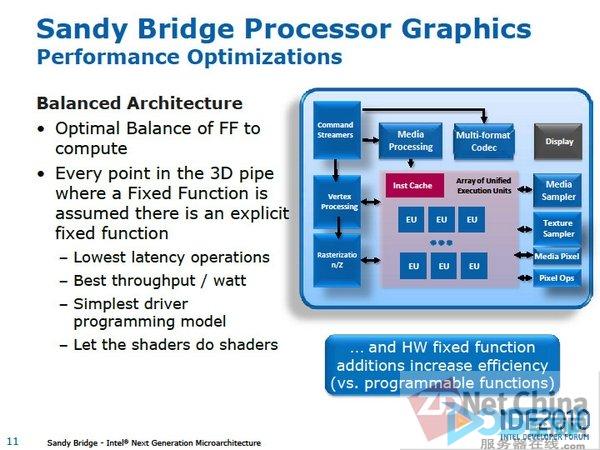
Sandy Bridge图形核心的这些改进结果原理上不只提高了每瓦的性能,还卸载了驱动程序。因为具有固定功能的API,将不再需要处理器程序的JIT编译器进行转换。Piazza表示:"驱动程序相比之前在运行时间上将有显著的减少"。
英特尔表示降低了驱动程序所需的CPU性能如时钟,也降低CPU功耗。换句话说,当图形处理时,图形核心的电源效率以及驱动程序的运行时间都将有所改善。
英特尔新的图形核心改善了固定功能硬件效率,它对比于其他厂商,并没多大创新。而重要的一点是,英特尔设计策略的180度大转弯–"GPU图形核心猜想"。
这和Larrabee时"CPU的图形核心猜想"是完全相反的。固定硬件将尽可能消除英特尔Larrabee试图用处理器进行处理的情况。
扩展现有EU运行的应用软件
由于在3D图形管道中固定处理,固定处理硬件可实现高效率运行3D图形。EU将本来集中处理的利用固定功能模拟分开。Sandy Bridge架构这样的改进已经开始。

Sandy Bridge的改进点
同时Sandy Bridge处理器EU的改进使它们可以得到更广泛的应用。更复杂的着色器和非图形通用计算程序的改善使得处理器更容易运行媒体处理程序。
具体来说,扩展寄存器文件,强化控制矢量的流量控制,减少数量的复合必须加强定点整数运算,通过削减指令步骤来减少 CISC(复杂指令集计算机)指令复合,强化固定硬件的整数运算,附加数据格式转换及其他指令,变换矢量大小,增加超越函数吞吐量,以上均由官方在IDF 上发布。Sandy Bridge EU的这些改进部分不仅提高了架构的吞吐量,还拓展了程序有效的运行范围。
消除在增加寄存器时寄存器的溢出量
首先, EU寄存器文件大小增加了。到目前为止,英特尔图形核心寄存器文件是有限的,但寄存器是不够的。因此,EU必须有能力处理寄存器文件溢出,这就不得不从高速缓存和内存寄存器撤出数据。
然而,这样处理寄存器溢出可降低吞吐量,通过移动不必要的数据也可减少电力消耗。因此,英特尔Sandy Bridge扩展寄存器文件,在大多数情况下,都必须存储在物理寄存器中。Piazza 解释道,据估计寄存器溢出功能都是由硬件负责处理。
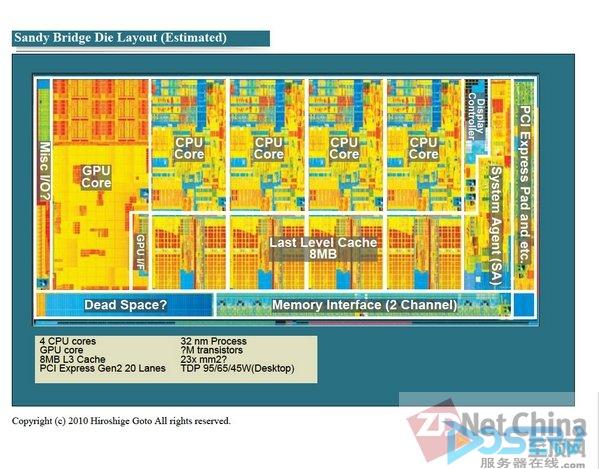
Sandy Bridge的晶片布局
一般而言,GPU在每线程的物理寄存器的数量是不固定的,比如在本地着色器在运行期间被分配给图形指令。通常图形只需要少量的寄存器(一般4到8个),而通用程序最佳情况是需要32个寄存器。但当启动一个线程时,必须减少寄存器的每个线程。
GPU的多线程较强的隐藏了内存延迟,大量的启动线程需要大量的寄存器。如果限制启动线程数量,将有可能停顿内存延迟。隐藏CPU缓存延迟,也将隐藏GPU的寄存器延迟。
通用程序和复杂着色器需要更多的寄存器来压入寄存器文件。在这种情况下,要启动一定数量的线程,物理寄存器将从内部和外部存储器上读取数据以避免不回收而造成的数据丢失。据推测目前的英特尔图形就是这种情况。
这将解决寄存器文件扩展名的问题。当然增加寄存器数量也会占据晶片面积。事实上,NVIDIA和AMD的GPU都存在着寄存器占用晶片面积的情况。英特尔图形核心也将面临这种情况。







