
即使你不上灵衢的车,为了构建超节点,也要在 NVLink、UAlink、SUE(Scale-Up Ethernet)、CXL、灵衢(UB)、HSL、ETH-X、ALS、OISA 之间进行选择!
原因也很简单:
超节点的技术核心就是算力单元间的高速互联,以 NVIDIA GB200 为例,采用 NVLink 5.0 可实现 GPU 间 1.8 TB/s 双向连接带宽;如不走 NVLink,改用 PCIe 5.0 x16,带宽仅有 126 GB/s,将是彻头彻尾的伪超节点。
目前 灵衢(UB) 访问带宽为 1.25 TB/s,稍逊于 NVLink 5.0,但在单跳延迟上,UB 以 150ns 优于 NVLink 5.0 <1.5μs 的性能表现。
这些性能指标之外,合理高速互联协议,还要关注一些细节的技术问题。
3 月 5 日,DOIT 视频号特邀上海交通大学计算机学院教授、博士生导师吴晨涛,对相关技术进行了解读:
1)强一致性内存访问 vs 最终一致性内存访问
NVLink 采用强一致性缓存访问方案,传承自传统高性能计算(HPC)的架构,也更适合小规模集群。
以 576-GPU 全互联域(8×NVL72)为例,任意 GPU 可直接读写其他 GPU HBM 内存,由硬件自动维护缓存一致性,一个 GPU 写数据,其他 GPU 缓存行自动失效 / 更新,对外呈现统一地址空间、统一内存池。
如果NVLink方案要构建更大规模集群,则需要通过 NVLink Spine + 以太网 / InfiniBand 级联多个 NVL72,本质也是 Clos “脊 — 叶(Spine-Leaf)” 架构分层组网,dan更大规模集群无法保证强一致性缓存访问的需求。
与之相比,灵衢(UB)采用 UB-Mesh 组网(nD-FullMesh)+ Clos 的混合组网方式,通过灵衢 (UB)将 CPU、GPU、DPU、NPU、内存、存储进行对等连接,实现全局内存地址统一编码。
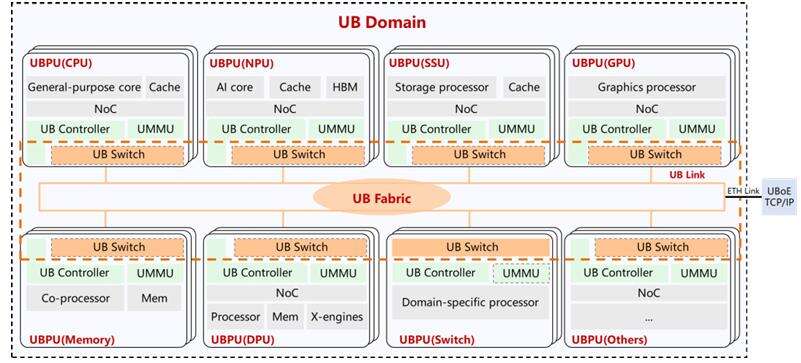
这意味着,所有通过 UB 连接的处理器、控制器可以对等访问对方内存,实现 Load/Store 操作;在缓存一致性保证上,采用的是最终一致性方案。
2)大模型训练 AllReduce 场景性能表现
大模型训练技术本质是对训练数据、模型参数拆分,通过SP/TP/EP等并行计算的手段,对模型进行迭代。有拆分就有聚合,其中 AllReduce 就是负责对分布式训练的参数进行全局聚合,将涉及 “整块整块显存”数据地求和,也是大模型分布式训练中非常频繁、关键的操作,这个过程对通信带宽、时延要求极高,可以作为超节点计算水平高低的“试金石”。
AllReduce并不需要缓存强一致性的约束, 只要AllReduce结束时全,局状态一致,模型训练就不会崩、精度不会掉,所谓最终一致性(eventual consistency)。
既然如此, NVLink 为什么要采用缓存强一致性访问?
NVIDIA 从 P100/V100 时代就开始做 NVLink + P2P + 统一虚拟地址,这套设计初衷并非面向大模型训练,而是为了兼容历史 HPC 架构;后来大模型爆发,该架构被直接沿用,强一致性也随之保留下来。
如今,NVLink 和 UB 都将 AllReduce操作下沉到交换芯片执行。
二者的核心区别在于:NVLink 方案跨节点计算时,需要依赖 InfiniBand 或无损以太网;而 UB 超节点可直接通过 UB 完成跨节点计算。
3)数据传输瓶颈问题
为了解决 AI 训练与推理应用中的数据存储存在的性能瓶颈问题,NVIDIA 发起了 StorageNext 合作计划,发布了、AIMP SSD等成果方案。其中,HBF依托 H3 架构,弥补 HBM 容量小、成本高的问题;AIMP SSD 则借助PCIe 7.0连接,使用X-FLSH、QLC SSD 等存储介质,以SSD盘的方式提供分层存储资源,它们都属于节点内存储分层的方案。
通过 GDS、RDMA 等技术,以全闪存阵列设计为主的外部存储方案也可以用于数据存储分层。
而在 UB 方案中,由于存储资源池已直接接入 UB 互联,整体架构更简洁、更彻底。凭借总线级互联、协议归一、对等协同、全量池化、大规模高可用组网等创新,灵衢(UB)为超节点设计提供了方案选择。
小结
如今灵衢(UB)已通过灵衢互联社区走上开放之路,借助以开放生态,让技术普惠应用,已经成功迈出了适合中国算力发展的道路。在灵衢(UB)、HSL、ETH-X、ALS、OISA 等众多国内标准方面,独树一帜!
展望未来,众多的国内标准会形成统一战线吗?

更多精彩内容,敬请收看「为什么要上灵衢的车?」直播回看!







