在“带宽、带宽、带宽,AI也是带宽之争”一文中,我从连接带宽的角度切入,对NVLink、灵衢(UB),以及Infinity Fabric等协议主导的计算机体系架构重构进行了对比。其中,生成式AI是这场架构重构的始作俑者,换句话说,传统以CPU、DDR内存为核心体系架构,已经没有办法满足需求,从而引发了重构,也决定了英伟达NVLink作为先行者。
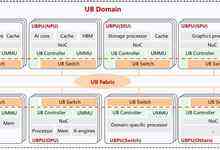
需要注意的是NVLink毕竟还是一个私有的协议,尽管也在不断开放,但还有很多私有的内容。如今,灵衢(UB)从UB 2.0开始采取全面开源的策略,创新性的提出了用UB连接CPU、GPU、NPU、SSU、MEM、DPU、Switch等池化资源,以及其他设备进行高速(高带宽)的互联,其光互联端口技术地采用,实现了8192超节点的广泛连接,“光的连接距离,电的可靠性”,灵衢(UB)构建的AI算力平台似乎更为先进和彻底。
作为一种全面创新的计算机体系架构,灵衢(UB)的价值和意义并非限制超级点和AI,对OLTP数据库、大数据、分布式存储等业务应用,它都能够带来效率的改进和提升。
既然如此,灵衢(UB)这种创新型架构会对现有的产品架构、格局带来怎样的冲击呢?以池化的MEM为例(这里的MEM指的是内存),它会改变HBM、DDR内存分立的格局吗?换句话说,为什么CPU不使用HBM的问题?CPU、数据库不需要高带宽吗?如今,灵衢(UB)的MEM池化会给内存带来怎样的影响?
针对这些具体问题,我也请教了华为集群计算总经理朱照生,得到的答复是:池化MEM中的UMMU(UB Memory Management Unit,可以类比处理器指令架构(ISA)下的MMU(内存管理单元),它用于做内存地址翻译、权限控制等,不是类比DDR5、HBM3等访问内存的物理接口。当UB支持访问其他内存时,会通过电路将UB上的指令转换到对应DRAM、HBM、Flash等介质上的操作,这样基于UB实现对所有空间的访问。
也就是说,无论CPU内嵌内存控制器与DDR,还是GPU透过Interposer与HBM内存的连接,不同类型的内存还是现实存在的,但如今,透过UB协议,UMMU的管理和池化,被CPU、GPU、外设等访问,相信会涉及类似内存一致性的话题。
朱照生指出:x86、RISC-V等各种指令集架构支持UB没有障碍,因为UB在架构设计的时候,不依赖具体的指令集架构,它可以很好的被x86、RISC-V、其他各种场景相关处理器集成和使用。当前灵衢公开后,其他x86厂商的处理器上支持UB需要一段时间,当前阶段,可以通过在x86处理器上的PCIe插槽上支持UB的网卡,就可以平滑的跟所有灵衢处理组件做互通。
“灵衢(UB)一个重要改变是将基于个人电脑架构的处理器,改为了规模直接扩展的一台逻辑计算机。单个处理器封装内能够合入的资源总是有限的,计算系统架构走向UB或者UB类似的体系,这是必经之路。”他说。
灵衢(UB)对于Linux、windows有什么要求吗?这是我的另外一个疑问。
对此,我得到的明确答复是:没有要求,就如同Linux和Windows可以运行在通用的BIOS上,UB在设计之初也做了考虑,它可以支持各类操作系统。但在现实世界中,Windows在数据中心服务器部署中占比较少,需求不急迫,还没有跟Windows展开合作。
如此看来,灵衢(UB)所带来的超高性能和扩展性,对于现有的IT基础设施要求并不高,即使现有的处理器、也可以透过外接UB网卡来实现互通;也可以透过UBoE对用户现有的以太网进行互联。需要注意的是,UB网卡也好,UBoE也好,必然会带来性能上的损失和降低,但也打通了灵衢(UB)与现有通算应用的连接。
如果用户需要应对AI、LLM的挑战,毫不犹豫拥抱灵衢(UB)是可供选择的方案之一,更为难能可贵的是,不仅是AI,灵衢(UB)与现有的IT基础设施,也保持了兼容和对接,为智算、通算结合埋下了伏笔!

我非常感兴趣的是,x86通算会接过灵衢(UB)递过来的橄榄枝吗?