
导读
人工智能算力需求呈指数级增长的今天,如何突破传统AI集群的算力瓶颈,成为全球科技巨头竞逐的焦点。
近日,华为正式发布新一代AI数据中心架构CloudMatrix及其首款量产级产品CloudMatrix384,通过重构硬件互联范式和软件协同机制,在6710亿参数的DeepSeek-R1大模型测试中,展现出超越英伟达H800/H100的能效表现,为万亿参数时代的AI基础设施建设树立新标杆。
文字编辑|宋雨涵
1
颠覆传统架构:
全对等互联开启“算力革命”
面对MoE(混合专家)模型带来的稀疏计算挑战和上下文窗口扩展引发的存储爆炸,传统AI集群的层级化设计已逼近物理极限。华为CloudMatrix384首创全对等互联架构,通过自主研发的Unified Bus(UB)网络,将384颗Ascend 910C NPU与192颗Kunpeng CPU无缝互联,实现:
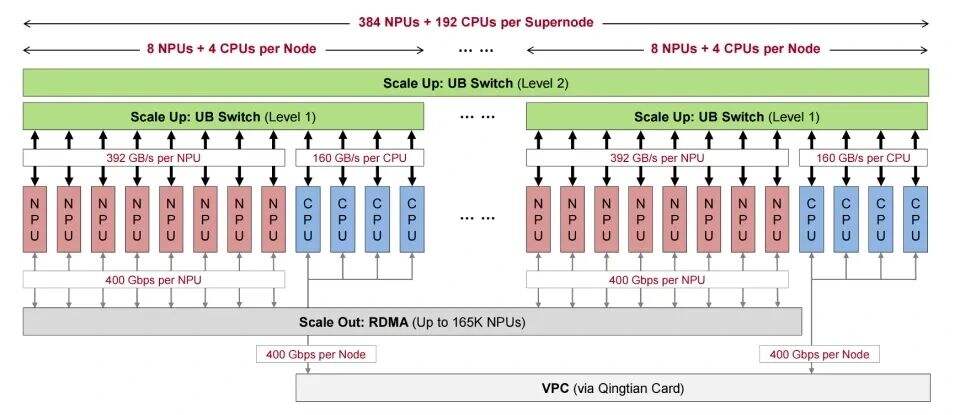
▲CloudMatrix384超级节点的点对点硬件架构
零距离通信:UB网络提供392GB/s/芯片的跨节点带宽,跨节点通信效率损耗不足3%,将传统集群的"孤岛式计算"升级为逻辑统一的超级节点;
异构资源池化:CPU内存、NPU显存与SSD存储通过UB网络形成统一资源池,KV缓存访问延迟降低86%,有效支撑百万级Token长上下文处理;
弹性扩展能力:支持从32路到320路的专家并行度动态调整,单芯片专家独占模式使MoE层延迟压缩至传统方案的1/3。
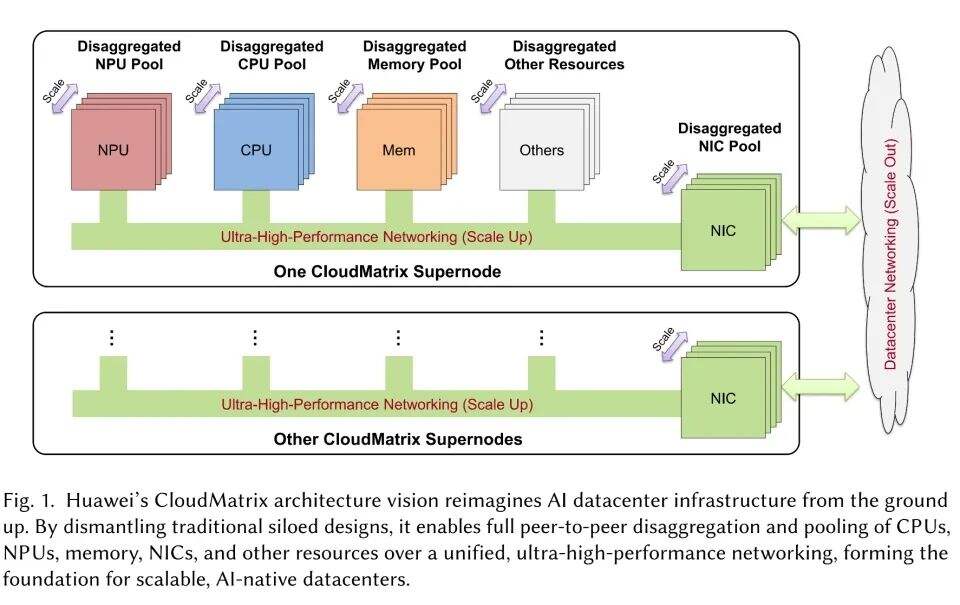
▲华为CloudMatrix架构愿景概述
CloudMatrix-Infer:LLM服务的新范式
此外为了充分发挥CloudMatrix384的潜力,华为提出了CloudMatrix-Infer,这是一个全面的LLM服务解决方案。CloudMatrix-Infer采用了去中心化的服务架构,将LLM推理系统分解为预填充(prefill)、解码(decode)和缓存(caching)三个独立的子系统。这种设计不仅简化了任务调度,还提高了缓存效率,优化了资源利用率。
2
性能实测:
双指标超越英伟达,低延迟场景优势显著
对DeepSeek-R1模型的广泛评估表明,CloudMatrix-Infer实现了卓越的吞吐量。
其在预填充阶段为每个NPU提供6688tokens/s,在解码期间为每个NPU提供1943tokens/s,同时始终保持每个输出token低于50ms的低延迟。这些结果对应的计算效率为:预填充阶段计算效率达4.45 tokens/s/TFLOPS,解码阶段1.29 tokens/s/TFLOPS,这两者都超过了NVIDIA H100上的SGLang和H800上的DeepSeek等领先框架的公布效率。
此外,CloudMatrix-Infer有效地管理了吞吐量-延迟的权衡,即使在更严格的低于15ms的TPOT约束下,也能够维持538tokens/s的吞吐量。
INT8量化策略在各种基准测试中进一步保持了与DeepSeek的官方API相当的准确性。
在6710亿参数DeepSeek-R1 MoE模型测试中,CloudMatrix384展现压倒性优势:
| 指标 | CloudMatrix384 | NVIDIA H800 | 优势幅度 |
| 预填充吞吐量 | 6,688 tokens/s/芯片 | 约5,060 tokens/s/芯片 | +32% |
| 解码能效 | 1.29 tokens/TFLOPS | 0.98 tokens/TFLOPS | +32% |
| 15ms延迟下吞吐量 | 538 tokens/s | <400 tokens/s | >34% |
实践落地六大优势:
重构AI算力架构的关键所在
目前,基于CloudMatrix的超节点集群已经在芜湖、贵安、内蒙规模上线,其六大技术创新点更是为AI算力架构的重构注入了强大动力。
在5月16日的华为云AI峰会上,华为云副总裁黄瑾在峰会上发表了主题演讲,深入介绍了CloudMatrix 384超节点的技术优势与细节。黄瑾在演讲中指出,随着大模型训练和推理对算力需求的爆炸式增长,传统计算架构已难以支撑AI技术的代际跃迁。在此背景下,华为云推出的CloudMatrix 384超节点架构应运而生,它不仅是技术的突破,更是以工程化创新开辟了AI产业的新路径。CloudMatrix 384超节点具备六大领先技术优势,包括MoE亲和、以网强算、以存强算、长稳可靠、朝推夜训以及即开即用。这些优势共同构成了新一代AI基础设施的核心竞争力,重新定义了AI基础设施的标准。

▲华为副总裁黄瑾
MoE亲和架构:从“小作坊”到“超级工厂”
在传统架构下,MoE模型训练容易因通信延迟导致算力浪费,而CloudMatrix 384超节点的分布式推理平台专为MoE大模型而生。对比一卡多专家的“小作坊模式”,超节点更像“大工厂模式”,通过高速互联总线,能够实现一卡一专家高效分布式推理,单卡的MoE计算和通信效率都大幅提升。这一优势使得政务、零售、医疗、保险、制造、矿山、旅游等各行各业的客户,能够基于华为云昇腾AI云服务部署DeepSeek模型的创新应用,在智能助手、智能客服、互联网搜索、内容创作等各种场景落地。
以网强算:双层网络破解“数据堵车”
当AI算力走向规模化部署,如何由点及面地激活算力矩阵的共振效应成为关键。CloudMatrix 384构建了AI专属高架桥,通过MatrixLink服务将单层网络升级为两层高速网络。一层是超节点内部的ScaleUp总线网络,确保超节点内384卡全对等高速无阻塞互联,卡间超大带宽2.8T,纳秒级时延;另一层是跨超节点间的ScaleOut网络,可支持微秒级时延,资源弹性扩展;同时,基于全局拓扑感知的智能调度算法,保障客户任务长稳运行。这一双层网络架构有效破解了“数据堵车”问题,提升了算力的整体效能。
以存强算:弹性内存改写“算存绑定”
华为云首创的EMS弹性内存存储,打破了传统GPU算力与显存绑定的关键障碍,通过内存池化技术,实现显存和算力解绑。一方面,用EMS替代NPU中的显存,可使得首Token时延降低,最高降幅可达80%;另一方面,当NPU的显存不足时,EMS独立扩容,不必再通过堆NPU以获得更多内存。同时,EMS还支持算力卸载,使得系统吞吐量提升,有的场景达100%的提升。这一技术创新大幅提升了资源利用率、性能和吞吐量,为AI大模型的训练和推理提供了更加高效的存储支持。
长稳可靠:故障自愈的“AI医生”
随着模型训练需求的不断接入,大集群的运维难度大、复杂性高的问题日益凸显。华为云开发了昇腾云脑运维“1-3-10”标准,即1分钟感知、3分钟定界、10分钟内恢复。通过5层压测、静默故障感知技术,昇腾云脑可将硬件故障感知率从40%提升至90%。同时,覆盖计算、存储、网络、软件四大种类故障模式库也打通了全栈故障场景,这一全栈故障知识库能够覆盖95%常见问题以实现故障快速定界;在恢复机制上,3层快恢技术、快速建链技术、图编译缓存等技术能够实现万卡故障快速恢复。这一故障自愈能力为AI大模型的稳定训练提供了有力保障。
朝推夜训:算力资源“错峰用电”
在大模型训练中,提升算力利用率,避免算力闲置是企业关心的重点之一。CloudMatrix 384超节点通过“训推共池”“灵活调度”两大关键技术实现朝推夜训,白天进行模型推理,晚上闲时进行模型训练,算力资源利用率可提升30%以上。这一“错峰用电”模式不仅提高了算力资源的利用率,还降低了企业的运营成本。
即开即用:“算力水电”普惠模式
为助力客户更好地专注业务模型开发,华为云已经在全国三大枢纽数据中心——乌兰察布、贵安和芜湖完成了超节点规模布局,支持百TB级的带宽互联,10毫秒时延圈覆盖全国19个城市群,让客户能够第一时间享受到即开即用的AI算力资源。同时,华为云拥有专业的超节点运维团队,在为客户免去繁琐的管理和维护的同时,保障资源的稳定运行。这一“算力水电”普惠模式为AI技术的广泛应用提供了有力支持。
结语:
CloudMatrix384的颠覆性在于:它以通信效率革命替代传统算力堆砌,用架构创新将摩尔定律延伸至集群维度。当英伟达受制于“通用GPU路径依赖”,华为以超节点证明——在万亿参数时代,决胜关键不是单颗芯片的制程,而是整个系统的“脑神经网络”效率。这场胜利不仅属于技术,更属于千行百业即将爆发的AI普惠浪潮。
本文来源于DOIT传媒,文章内容仅供参考,不构成投资建议。


评论列表