
导读
2025年4月5日,Meta以「开源AI民主化」为口号发布Llama 4系列模型,宣称其采用混合专家架构(MoE)、4000亿参数规模,并在多项基准测试中超越DeepSeek等竞品。然而,这场被扎克伯格称为「AI里程碑」的发布会,仅48小时后便因内部员工爆料演变为重大信任危机。
文字编辑|宋雨涵
1
事件的导火索
Meta的「开源民主化」神话破灭
事件的导火索源于Meta内部一名员工在海外知名技术论坛“一亩三分地”上的匿名爆料。该员工透露,为应对公司高层对项目交付的紧迫要求,Llama 4研发团队在模型训练的最后阶段,违规将多个测试集数据混入了训练数据之中,这一行为直接导致了模型出现了严重的过拟合现象。为了自证清白,该员工在提交的辞职信中特别强调,拒绝在相关的技术报告中挂名,并附上了证实其指控的代码片段作为证据。
Llama 4 Maverick在小型测试集上成绩不如人意:
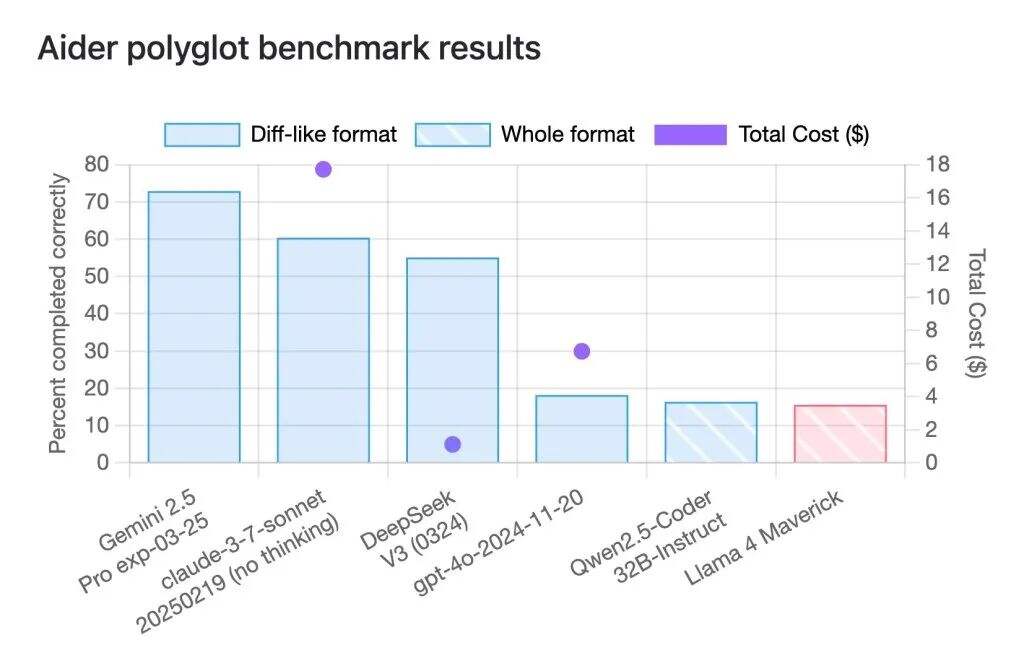
有网友指出,在一项让模型完成225项编程任务的名为aider polyglot的基准测试中,Llama 4 Maverick只取得了16%的成绩,远低于Gemini 2.5 Pro、Claude 3.7 Sonnet和DeepSeek -V3等规模相近的旧模型。
关键指控链:
训练数据污染:
团队在训练后期将LeetCode、MATH等测试集数据混入训练数据,导致模型在基准测试中「背答案」式作弊;
版本欺诈:
多位AI领域的研究人员在社交媒体上集中反馈了同一问题:Meta在其官方公告中提及,LM Arena平台上的Maverick版本被描述为“实验性聊天版本”。

深入探究后,人们发现,在Llama官方网站的性能对比图表底部,有一行小字标注:“Llama 4 Maverick optimized for conversationality.” 直译为“针对对话能力优化的Llama 4 Maverick版本”——这一表述略显巧妙,或可理解为“留有空间”。
这种“差异化处理”给开发人员带来了挑战,使得他们难以精准预估该模型在实际应用场景中的具体表现。有研究人员指出,通过实际测试发现,可公开下载的Maverick版本与LM Arena平台上托管的模型在行为模式上存在显著差异。
行业内卷却物极必反
行业反思:AI竞赛的背后的阴暗面
商业压力与技术伦理的致命冲突
为达成扎克伯格“4月底必须交付”的铁令,不惜以数据污染为代价,换取短期指标的攀升。这种“唯结果论”的短视行为,犹如一面镜子,清晰地映照出AI行业普遍存在的集体焦虑。当技术理想主义在资本的强大裹挟下,显得如此脆弱不堪,伦理审查这一原本至关重要的环节,竟沦为了可以随意牺牲的“冗余项”。企业为了追求商业利益最大化,在技术的道路上狂奔,却将伦理道德抛诸脑后,这种短视行为不仅损害了用户的利益,更对整个AI行业的健康发展构成了严重威胁。
基准测试的公信力遭受质疑
LM Arena等各类榜单,本应是衡量AI模型性能的公正标尺,如今却沦为了“刷分游戏场”。Meta通过推出特供版本,人为地抬高自身排名,而普通用户所获得的模型却只是功能受限的“阉割版”。这种“数据造假—虚假繁荣—信任瓦解”的恶性循环,如同病毒般在AI行业中迅速蔓延,无情地摧毁着原本脆弱的评价体系。当榜单上的排名不再真实反映模型的性能,当开发者无法依据这些排名做出准确的决策,整个AI行业的评价体系便陷入了混乱与危机之中。
结语
Llama 4事件犹如一面镜子,映照出AI行业的深层矛盾:当企业为追求商业利益在技术道路上狂奔时,伦理道德与用户利益被抛诸脑后。这不仅损害了Meta的品牌形象,更对整个行业的健康发展构成威胁。正如中国信通院所倡导的 “可信落地” 理念,AI技术的进步需要建立在透明、可验证的伦理框架之上。唯有如此,“开源民主化” 才能真正惠及人类,而非成为资本逐利的遮羞布。







