
如果我们想搭建一个企业级的大模型应用,不管使用开源的基础模型自己来发布,还是使用类似于 ChatGPT 的闭源 API,我们都需要搭建一个大模型流水线来管理应用体系中除了基础模型之外的功能模块。
Replit 的一篇博客(https://blog.replit.com/llm-training)里列出了一个非常典型的使用私有数据来训练和伺服私有大模型的流水线:

当然,绝大部分企业或者机构都不会太需要自己去训练一个私有化的大模型,但是即使是做一个简单的 RAG(Retrieval-Augmented Generation)系统,我们也需要一个完整的文档处理流水线来持续转换文档,划分文档为合适的文本块,选择合适的 embedding model 和向量数据库,然后使用 prompt engineering 来构建合理的问题提交给大模型。
在目前来说,类似于 LlamaIndex 或者 LangChain 的工具在使用集成的第三方 API 或者内嵌的数据库来实现快速原型是很方便的,但是如果我们想尝试独立的 embedding 模型,高速的分布式向量数据库,定制化的文档划分策略,或者是细分的权限管理,还是有很多额外的工作要处理。
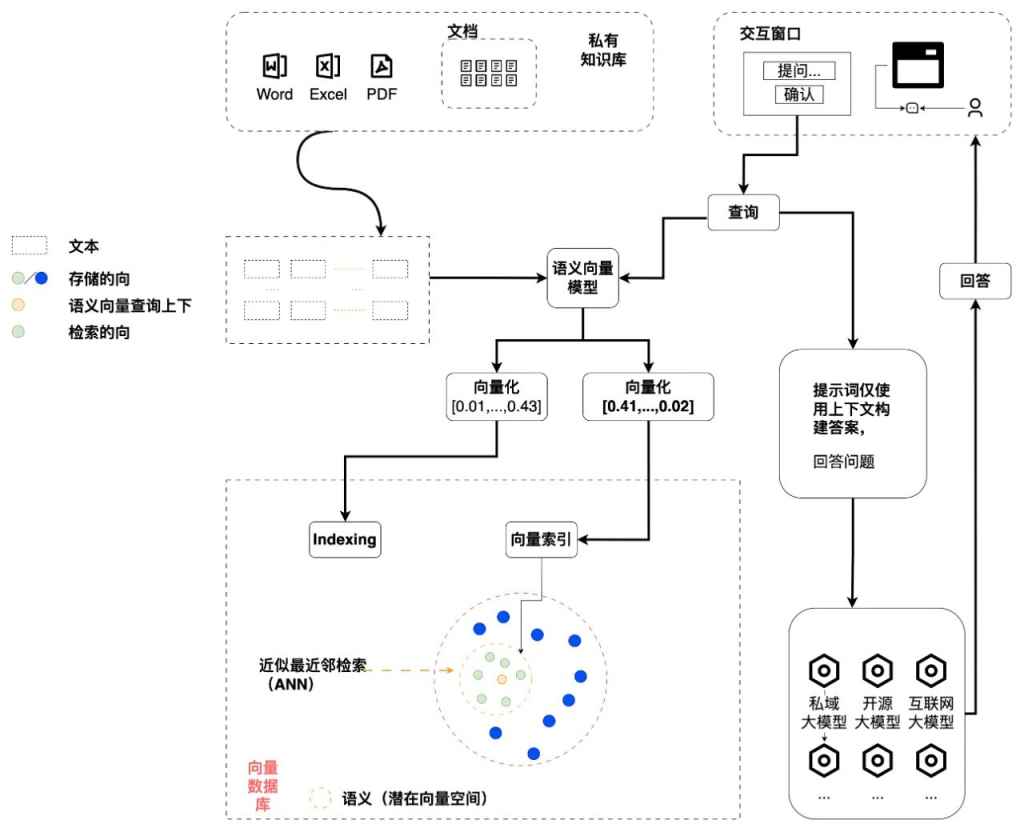
除了基础大模型之外,大模型生态系统中用来建设一个模型流水线的工具组件可以分为两大类:
第一类是作为第三方库被其它应用调用,从最底层的 CUDA,PyTorch,Pandas, 到中间的各种 tokenizer, quantization, 到上层的 Transformers, Adapters 等等。
第二类一般是作为建设一个完整模型流水线时的一个应用组件,可以独立运行并完成特定的任务。
当然,有些开源系统两种使用形式都存在,例如向量数据库,很多既可以独立运行,又可以作为一个内嵌的组件供应用使用。作为最终模型流水线的搭建者来讲,我们直接打交道的大部分是第二类应用组件类型的工具,它们又会去调用很多第一类的第三方库来完成自己的工作。下面列出了一些常用的应用组件类别以及其代表性开源组件。
1. Model Serving
模型服务工具,将训练好的模型部署为可供应用程序使用的服务。这些工具通常提供 API 接口,允许开发者轻松地将模型集成到现有的系统中,支持高并发请求,确保模型的响应速度和稳定性。
- vLLM: 一个高吞吐量且内存效率高的推断和服务引擎,主要使用了 PagedAttention 和定制的 CUDA kernel 来提高性能。
- GPT4All: 支持在日常硬件上(主要是 CPU 上)训练和部署 quantized LLM。
- Ollama: 方便的在私有化环境下一键发布和运行各种开源大模型,提供通用命令行推理工具以及兼容 OpenAI API 的 API 接口。
- LocalAI: 主要目标是 OpenAI API 生态体系的本地替代品,允许在本地运行大模型服务,与 OpenAI backend 无缝切换。
2. Training Framework
训练框架,提供了工具和 API 来简化大规模模型的训练过程。这些框架优化了数据处理、模型构建、训练循环和资源管理等过程,使得开发者可以更专注于模型的设计和实验。
- Megatron: NVIDIA 提出的一种用于分布式训练大规模语言模型的架构,针对 Transformer 进行了专门的优化(也就是大矩阵乘法)。
- Lightning: 支持在大规模分布式环境下使用 PyTorch 进行 AI 模型的预训练、微调和部署,而无需修改代码。
3. Scheduling and Orchestration
调度工具,将模型运行在云上或者分布式集群中。
- SkyPilot: 主要支持在公有云服务上一键运行 LLM、AI 和批处理作业,而无需手动去购买资源以及配置服务器,它可以自动寻找最合适的配置,并在运行完成后自动释放资源,提供成本节约、提高 GPU 使用效率。
- Ray: Ray 是一款基于 PyTorch 的框架,专为并行处理 AI 和 Python 应用程序设计。它提供了高级 API,可用于处理数据、模型、超参数和强化学习等任务,以及核心原语,可用于构建分布式应用或自定义平台。
4. Document Processing
文档处理工具,专注于从非结构化数据中提取信息和结构,如从 PDF、图片或文本文件中提取文本内容和元数据。
- Unstructured: 提供了用于摄取和预处理图像和文本文档的开源组件,例如 PDF,HTML,Word 文档,和更多其他格式。它的模块化功能和连接器形成了一个统一的系统,简化了数据摄取和预处理,使其能适应不同的平台,并有效地将非结构化数据转化为结构化输出。
- Apache Tika: Apache Tika 工具套件可以检测并提取来自一千多种不同文件类型(如 PPT、XLS 和 PDF)的元数据和文本。所有这些文件类型都可以通过单一接口进行解析,使 Tika 对于搜索引擎索引、内容分析、翻译等都非常有用。
5. VectorDB
向量数据库,专门用于存储和检索向量数据,主要用于实现基于相似性搜索和 RAG 系统中。
- Milvus: 主要特点是支持分布式发布以及并行处理,底层使用 etcd, MinIO, Pulsar, RocketMQ 等分布式处理组件,在生产环境上可以快速支持弹性扩展。
- Chroma: 主要特点是安装快速方便,资源开销小,依赖简单,适合用在嵌入式场景下,快速构数据搜索应用。
6. Application Framework
应用框架,提供了构建特定应用程序的基础设施和组件,如语言模型的索引和检索、聊天机器人的对话管理等。
- LlamaIndex: 简化 LLM 和外部数据源(比如 API、PDF、SQL 等)之间进行交互的工作,可以快速实现基于数据的大模型应用。它提供了对结构化和非结构化数据的索引,有助于简化处理不同的数据源。它能够存储提示工程所需的上下文,处理上下文窗口过大时的限制,并在查询期间帮助平衡成本和性能的关系。
- LangChain: 将各种大模型功能以 chain 的方式集成起来,帮助开发人员低代码快速开发端到端大模型应用。LangChain 提供了一整套的工具、组件和接口,能够方便地处理与语言模型的交互,连接多个组件,以及整合额外的资源,如 API 和数据库。
7. Finetune
微调工具,允许开发者在特定的数据集上调整预训练模型的参数,以提高模型在特定任务上的表现。
- Llama Factory: 基于 PyTorch,用于微调和二次训练 LLM 的框架。支持多种微调方法和优化技术,如 LoRA、QLoRA、P-Tuning 等,可以在有限的算力和数据下,定制开发专属的领域大模型。还提供了一个名为 LLaMA Board 的网页界面,可以方便地调整模型参数和查看训练结果。
- HuggingFace TRL: 一个基于 PyTorch 的框架,用于使用强化学习训练 Transformer 的模型。它提供了一整套工具,从监督微调(SFT)、奖励建模(RM)到近端策略优化(PPO)等步骤,可以方便地定制和优化语言模型的性能和品质。它还支持多种预训练模型、数据集、采样方法和训练辅助功能,涵盖了不同的任务需求。
8. RAG: RAG(Retrieval-AugmentedGeneration)
是一种结合了检索和生成的技术,用于提高语言模型在特定任务上的表现,如问答和文本生成。
- PrivateGPT: 私有发布的 RAG 平台,使用 LlamaIndex 搭建 RAG 流水线,在本地运行 Chat UI,提供大部分模型管理以及文档管理功能,同时提供 OpenAI API 兼容的接口,可以方便地与现有的应用集成。
- LocalGPT: 使用 LangChain,llama-cpp 和 Streamlit 搭建的 RAG 平台,主要特点是支持各种 quantized LLM 和 CPU 运行,可以快速在单机上运行。
9. ChatBot
集成聊天机器人,专注于构建和部署交互式对话系统,一般提供对话管理、提示词工程管理、历史管理的功能。
- NextChat: 用于快速创建和部署跨平台的 ChatGPT/Gemini 应用,可以快速地搭建自己的私人聊天机器人,支持 GPT3, GPT4 和 Gemini Pro 等多种语言模型以及提示词管理,历史管理等核心功能,提供 Linux / Windows / MacOS 客户端。
- Jan: 提供了一个跨平台的本地 ChatBot 桌面应用,支持 Linux / Windows / MacOS,内嵌使用其自主开发的 Nitro 推理引擎来运行大模型,可以作为一个完全离线的 ChatGPT 替代产品。
然而,使用这个生态系统搭建模型流水线的一个主要挑战是管理和维护各种依赖项的兼容性,包括 Python 版本、第三方库版本、CUDA 版本以及硬件和操作系统的兼容性。这些因素共同构成了一个复杂的环境,经常导致版本冲突和不兼容的情况。
此外,如何将各个组件的配置统一管理起来,不用重复配置,不用手动配置各种端口以避免冲突,动态管理依赖,也是常见需要解决的问题。除了应用运行之外,数据在这些组件之间的流动也需要完善的管理以保证数据的正确性以及数据任务的及时完成。这些问题听起来是不是有些熟悉呢?
是的,这些问题其实还是属于传统数据流水线(Data Pipeline)和运维(DataOps)的范畴,只不过多了几个特定功能场景:使用 GPU 或者 CPU 来发布大模型,用 sequence 数据(大部分是文档)来 finetune, pretrain 大模型,或者用大模型来进行 inference 服务或者以 agent 形式提供自动操作。
在 A16Z 的“Emerging Architectures for LLM Applications”博客中列出的大模型应用技术栈中,除了 Data Pipelines 本身就属于这个技术栈的一部分之外,类似 Embedding Model, Vector DB, Logging/Observability, Orchestration 这些组件,其实和 DataOps 中相应的组件的管理运营方式差别不大,特别是在云原生和容器化这个方向上,基本是一致的。
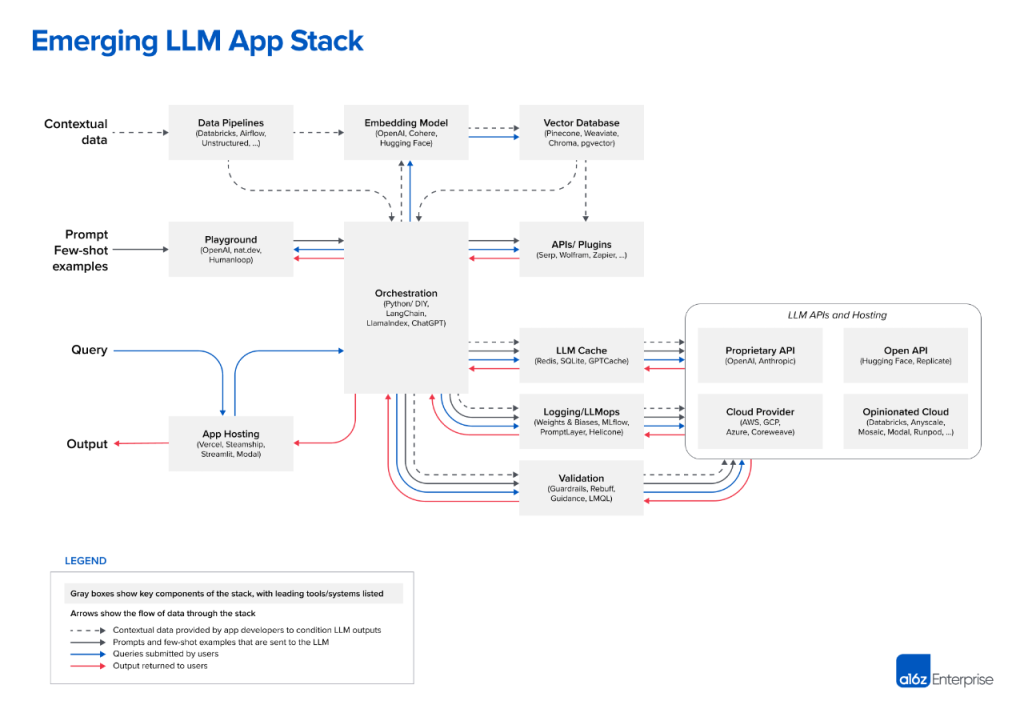
所以,我们认为,将这些组件以容器的形式实现标准化发布(上面的组件中很多都已经提供 Docker 发布方式),使用类似于 Kubernetes 这样的资源调度平台来管理这些组件的运行,可以大大降低大模型流水线的使用门槛,提高大模型应用发布和运行的效率。
而且,不管后端的基础大模型如何变化,这样建设流水线的工作都是需要的甚至我们可以说,为了适应快速迭代的基础大模型,我们应该以云原生,容器化,服务化,标准化的方式建设我们的大模型流水线,允许我们在不同的私有发布,公有发布的大模型之间随意切换,选择最适合我们应用场景和和价格最合适的大模型使用模式。
我们将会在”容器中的大模型”系列博客中,以不同的大模型应用场景(例如 RAG,Text2SQL 等等)为例,展示如何以容器化的方式发布这些开源大模型应用组件并合理地将它们组织起来来完成具体场景的工作。希望这些博客能为准备建设大模型流水线的读者提供一些参考,也非常期待大家的反馈和建议。
本文来源于DOIT传媒,文章内容仅供参考,不构成投资建议。


评论列表