
以Chat GPT为代表的聊天机器人所表现出来的理解和推理能力让人惊叹,也让视频脚本、文案、翻译、代码,论文、邮件撰写等需要人类创意的工作变得简单。Chat GPT的背后是算力、算法和数据的支撑,按照国内云计算专业人士公认的一个说法:1万枚NVIDIA A100芯片是做好AI大模型的算力门槛,而A100的价格不菲。
根据研发ChatGPT的OpenAI公司的训练集群模型作为参考,1746亿参数的GPT-3模型,大约需要375~625台8卡DGX A100服务器(对应训练时间10天左右),训练一次的成本,需要花费460万~500万美元。这不是一般企业可以承受之重。
“别人笑我太疯癫,我笑他人看不穿;不见五陵豪杰墓,无花无酒锄作田。”
你看到的是结果和市场的潜力,我看到的是其背后巨大的花费和支出。如果说算力是Chat GPT等AI大语言模型必须付出的代价,那么,好钢就需要用在刀刃上,人尽其才、物尽其用,任何的效率低下和损失,所带来的损失将是倍增的效果。
压榨算力的关键并不在于CPU、GPU,其关键在于DPU和网络基础设施,试想一下,因为网络带宽和传输效率的问题,宝贵的CPU、GPU资源一旦出现等待,“没有声音,再好的戏也出不来”,在高性能计算领域,这样的情况就经常发生,考虑到规模,这样的局面不应该在AI大模型的应用中重演。

所谓专业的人做专业的事情,引入DPU与高性能的以太网网络平台和InfiniBand网络网络平台将是提高网络传输效率的关键,其中,高性能网络好理解,主要解决传输带宽的问题,因此关键在于DPU的使用。
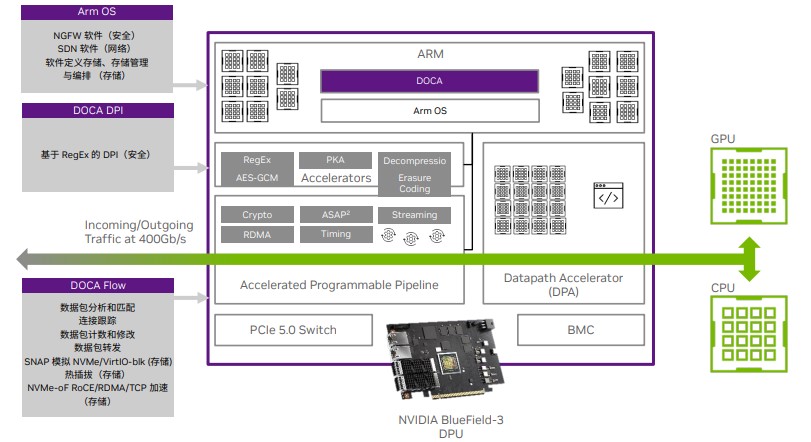
通过集成ARM、ASIC和RISC-V处理器,NVIDIA BlueField-3 DPU可以对包括SDN软件定义网络、NGFW新一代防火墙、数据存储加速,DOCAFLOW 库、通信通道(Communication Channel)库、正则表达式(RegEx)库、App Shield SDK以及OVN IPsec 加密完全卸载等功能进行单独处理和加速,对遥测(Telemetry)、基于主机的网络(Host Based Networking)以及流量检测器(Flow Inspector)等功能服务进行了加强。如此一来,在降低CPU、GPU消耗的同时,大大提升网络处理和传输的效率。其中的原理也很简单,一来CPU、GPU不擅长处理这些事情,二来让CPU、GPU处理也消耗带宽的资源,增加等待的时间。
除此之外,DPU也被用于加速云计算,支持云托管更多虚拟实例;被用于多租户云的安全隔离,将业务应用域和基础设施域进行隔离,提供零信任安全的部署的平台;可以对Redis事务处理等进行加速,通过IPsec功能卸载,提升效率的同时,降低数据中心的能耗。
如果说,DPU的引入是关键,那么,DOCA 就将为DPU注入灵魂,这是一个面向DPU开发者的软件开发平台,如今,DOCA迎来了新的2.0 版本。
据了解,以后的BlueField 系列DPU都是运行在DOCA软件架构之上,它实现了底层硬件从驱动、库到相关的加速,很多功能都可以被卸载到DOCA,它向上提供编程接口,方便开发者利用DOCA进行编程。目前DOCA向下兼容以前的版本,比如最新发布的DOCA 2.0,也能运行在上一代BlueField-2 DPU上,差别在于有些功能没有办法完全实现。
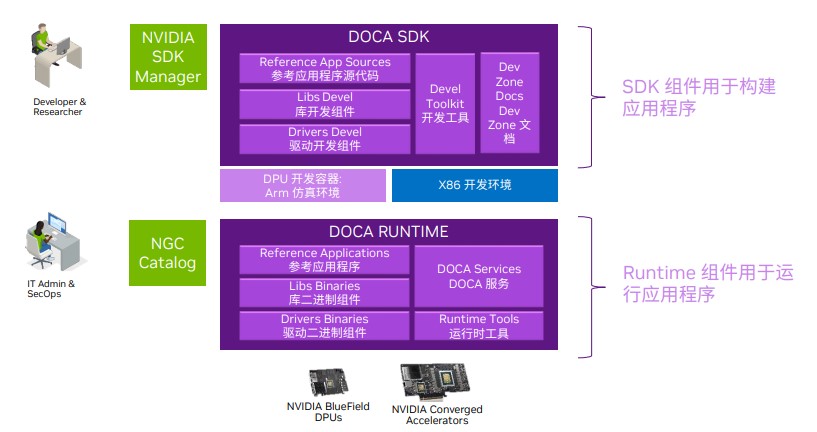
DOCA环境非常体系化,分为SDK、RUNTIME运行时两部分,其中,SDK主要是驱动库、开发工具包括X86笔记本电脑上去模拟DPU构建的ARM开发环境,让你在笔记本电脑上也可以做DOCA的开发。而RUNTIME运行时提供了基本的DOCA服务,以及一些组件和一些已经写好的参考程序,用于帮助IT管理员和运维人员简化部署。
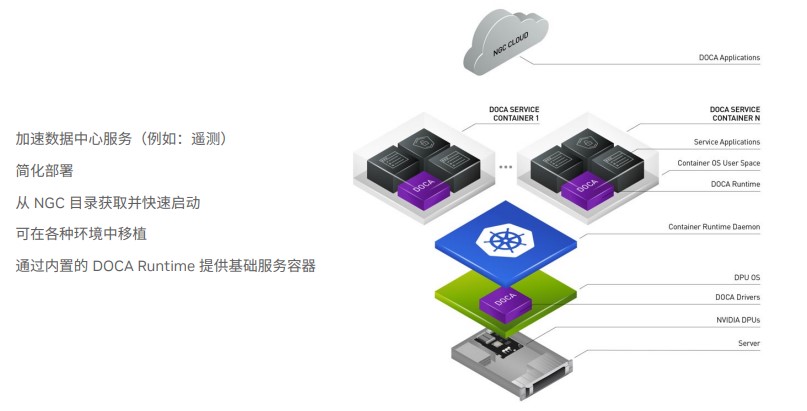
DOCA服务包括遥测等简单的功能,可以通过NGC可以简化部署,不用敲那么多命令行,几乎一键式就部署在服务器、甚至数据中心。通过虚拟化、迁移手段可以对不同硬件,比如x86进行迁移。

通过引入了DPA计算子系统(基于RISC-V),BlueField-3 DPU可以对设备仿真、IO密集型应用、高插入率、网络流处理和客户协议、集合和DMA操作进行了优化。
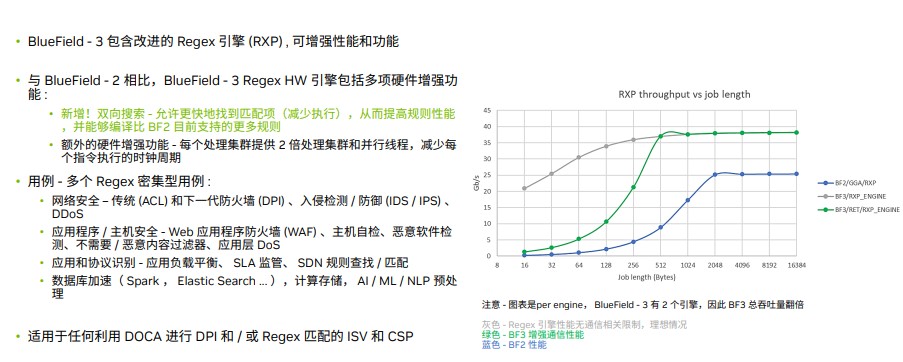
新的BlueField-3 DPU中改进了Regex 硬件引擎,增加了多项硬件增强的功能,如双向搜索,可以更快的找到自己需要的匹配相关内容的包;与此同时,在网络安全、应用软件/主机安全和应用协议识别和数据库加速等,新的功能非常有助于预防高并发的DDos攻击,实现高性能的恶意软件检测,有助于提升大语言模型AI训练的效率。

BlueField-3 DPU新增加了用于提升存储特性的SNAP v4,直接从DPU将相关数据交给GPU做训练,不用再经过CPU调度。未来,SNAP v4会被NVIDIA放在NGC,即可一键部署。
工欲善其事必先利其器,AI大模型也好,高性能计算也好,正在逐步演变为DPU之争,效率将会成功关键要素,需要引起足够的关注。







