
引言:近日,“昇腾万里 共赢智能新时代”峰会在深圳成功举办。峰会集聚了人工智能产业界权威专家、学者和商业领袖,共商人工智能产业发展趋势,共同推动人工智能产业繁荣发展。大会现场,中国工程院院士、鹏城实验 主任、北京大学教授高文发布《鹏城云脑支撑鹏程系列大模型基础研究》主题演讲,如下是高文院士演讲全文要点。
各位专家、各位来宾,大家好!今天我主要是讲鹏程大模型和自然语言处理有关的赋能。
鹏城实验室是国家为了中国科技长期能够稳定支撑整个国家的发展,所布局的战略科技力量当中的一支团队,主要聚焦宽带通信和新型网络方面,包括高效能云计算服务。今天我讲的基于昇腾基础软硬件所做的工作就是属于高效能云计算服务中的一块,主要是通过鹏城云脑来实施这个战略。
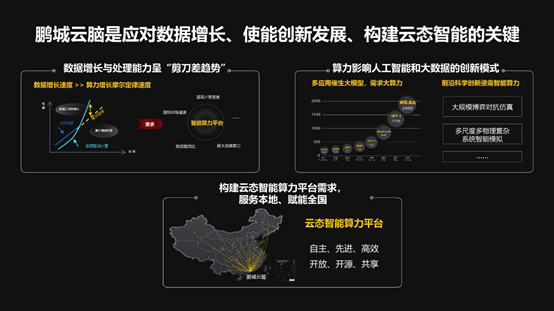
为什么要做这个?道理其实大家很容易懂,现在有了人工智能,因为数据增长速度非常快,算力又满足不了要求,应用又很急切,我们怎样把这些东西全都打通?需要有一个非常强的算力平台作为支撑,能够处理大规模的数据,能够有好的算法,在这个算力平台上把想要的解决方案提供出来,所以有这样一台大的设施是非常关键的,这个设施我们就把它叫做云脑。
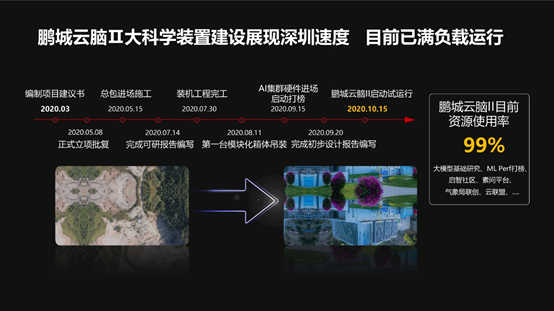
我们在建设鹏城云脑II的期间,真正实现了“深圳速度”的一个神话,为什么呢?了解我们国家科研制度的都知道,你要想做一个大的装置,或者做一台比如说大的机器,从开始到论证、报方案、批复,然后科研,然后再开始建设,这一个周期下来,快的是几年,慢的有的是十几年。而鹏城云脑II从开始递交方案到机器建成一共用了九个月,真正体现了“深圳速度”。编制项目建议书是在去年(2020年)3月份,云脑II机器启动运行是在去年10月15号,大家看左面这个坑是建机房之前,原来是采石场的一个坑,右边这个照片是机房建好以后的样子。现在这台机器非常忙,这个机器的机时的使用率是99%,就是基本上是一点都不闲着,排着队在等机时,因为我们有太多大模型需要在这个机器上去训练。
这个机器我们叫E级AI算力,达到1000P,所谓E级是10的18次方,或者换成我们普通说法叫做百亿亿次,我们知道一亿是10的8次方,亿亿就是10的16次方,后面再加两个零就是百亿亿次,应该说在AI算力上,是现在最强的一个,当然可能其他一些地方也有比这个算力规模稍微小一点的机器,现在用华为的系统已经建了大概六七个、七八个,或者是100P、300P的机器,大概是这台机器的1/10,或者是1/3这样的一个算力。这个算力要把它转起来还是要花点气力的,因为我们这台机器是基于华为的Atlas 900 AI集群实现的,一组Atlas 900 AI集群有128个计算节点,每个节点内包含8颗昇腾910处理器,我们把四组Atlas 900 AI集群连到一起,整个是统一接口、统一形象,完全是一张网、一个机器。为了做这个机器,我们把四组集群上面架了一个全交换的非常快的网络,为了让它对数据的读取速度更快,对每一个机器里面的存储做了加强,对它内部的一些运算底层的软件做了优化,这样就使得这个机器的速度非常快。快到什么程度呢?基本上这台机器现在在全世界的IO速度是最快的。快到什么程度呢?在去年的11月份,这台机器去打榜的时候,比排第二的英特尔的一台机器快了四倍。如果想做人工智能训练,想做大模型训练, IO的速度是决胜的,因为要有大量的数据来回的读进去吐出来,如果IO速度如果不行的话,很多的开销都被IO给吃掉了。这台机器因为它IO方面做了特殊的配置,而且网络方面也做了特殊配置,所以这个速度,就是通信的开销,整个占比是比较低的,所以它在整个模型训练的时候效率就会高。

这台机器现在至少已经训练出两个千亿级的大模型。前几天华为已经发布过一个盘古大模型,今天我要跟大家说的是叫鹏程大模型,这是两个自然语言处理预训练大模型之一。大家知道GPT3基本上是做自然语言处理,大家非常向往的一个模型,微软为了训练一个GPT3在微软的环境下,花了1200万美元训练出一个GPT3的模型来。我们现在云脑II机器做完以后,已经训练出两个这样的模型,一个是鹏城实验室跟MindSpore团队等联合攻关训练出来的,这个模型叫鹏程.盘古,模型参数为两千亿;另一个是华为云联合鹏城实验室一起联合训练出来的大模型,这个模型叫华为.盘古,这个模型参数为一千一百亿。这两个模型整个的复杂度都是千亿参数,而且专门是针对中文的最大的模型。
鹏程模型还有一个特点是开源的,我们内部的人讨论说,就算你把两千亿开源了,它离了我们这台机器还是玩不转,要想跑起来就得来我们这个机器上跑。为了支持应用怎么办呢?我们先开出一个百亿级的大模型来,那么千亿级的,如果有需要,只要是讲清楚你要怎么用,在哪里算,我们也可以开。所以原则上支持开源的。
那么有了这个开源,你就可以做很多自然语言处理方面的事。你要想做一个中文的问题回答系统,就是问答系统,你要想做自然语言的理解,想做一些理解器,或者你想做机器翻译等等,这个系统都可以做。这个模型可以做云搜索、智能客服、医疗的一些向导、互动的教育、文学创造、自动摘要的生成,甚至做代码的生成。现在我们有一个团队在做一个知识产权交易联邦推荐系统,没有这个模型之前,是用软件和很多专家的知识,做了一个系统,用上鹏程大模型以后,这个系统性能一下子提高了12.2%,所以鹏程大模型的好处是显而易见的。而且我们希望用这个模型来突破“语言壁垒”,支撑“一带一路”的国家战略,也就是说用这个模型我们很容易做机器翻译,做商业的这种报关等等这些文件的交换。以前是商量好用英语或者商量好用什么语言,现在随便,你这边用中文,那边用阿拉伯语,通过这个东西马上给你互译过来。大家现在用手机就可以登录进去,试试这个模型好不好用,你问一些问题,看看它能不能回答出来。

鹏程大模型到底是怎么“炼”出来的呢?它是有四个方面基本的要素:
第一个要素是AI的算力,就是鹏城云脑II;第二个要素是要有高质量的中文语料库,我们有一个专门整理中文语料数据集的团队,把能拿到、能买到的数据全都拿来进行清洗,然后把数据整理得非常好,送进机器就可以进行训练;然后要有一个非常好的全自动并行的这样一个算法,这个算法是由昇腾、MindSpore团队和鹏城实验室的工程师无缝合作,把这些全并行的技术实现了;最后就是通过“产学研”三方合作新型研发合作机制,结合华为的产业优势,北京大学的学术优势,以及鹏城实验室的研究优势,形成互补、协同。

整个鹏城云脑可以作为核心节点连接全国算力的基础设施,我们刚才说的是1000P的这样一台机器,现在全国各地有不少基于昇腾软硬件在做的100P的或者300P的机器,这些可以联动起来一起做,有大的问题、难的问题可以到1000P的机器上跑,小一点的模型或者私有化的一些应用,可以到100P、300P的机器上跑,这样大家有些分工,就可以在全国把人工智能分享起来。






