
北京时间2020年12月14日晚间,由于内部技术故障导致大面积宕机,谷歌多项服务均无法提供服务,类似的宕机新闻时有发生,每次的主角都可能都不一样,到底谁的宕机次数和宕机时间更少呢?
市面上有一些公开的监测数据,比如来自downdetector.com和cloudharmony.com的数据,也有厂商比较自豪说自己宕机时间比同行老伙计时间短的,比如在2018年,亚马逊云服务(AWS)表示第二大云计算公司的宕机时间是AWS的7倍。
AWS坐拥全球近一半的云市场份额,理论上规模越大越容易出错才对,AWS为了减少宕机时间都做了什么呢?在亚马逊re:Invent大会,AWS全球基础架构和客户支持高级副总裁Peter DeSantis介绍了基础设施层面上方方面面的创新,包括如何减少宕机,如何做更多创新。
在减少宕机时间,在提升服务连续性方面,AWS有挺多的有意义的做法,AWS大中华区产品部计算与存储总监周舸向中国媒体介绍了其中几点。
AWS数据中心电力冗余设计
从电力供应开始说起,周舸介绍了柴油发电机,介绍了配电室(E-house),UPS备用电源等方面,令人印象深刻的是,为了减少可能发生的故障,AWS在采用现有商用方案的基础上,舍弃了许多原有的东西,自己设计了控制电路的代码。AWS对基础架构的控制能力可见一斑。
在AWS看来,这些控制软件有可能有Bug,如果Bug发生,厂商无法在短时间内完成修复,而如果这些软件本身就是自己写的,那么就可以很快进行修复。这种对于现有服务方案的“不信任”贯穿着AWS架构设计的方方面面。
AWS CTO Werner Vogels曾说过,”Everything fails, all the time”,也就是说,所有东西都可能会坏掉,既然无法避免会坏掉,那就坦然接受,但一定要尽量减少坏掉造成的影响,要能预测什么时候会坏、怎么坏的,提前做出防范和应对。
比如,为了保障电力供应,AWS会在有外部电网供电和内部发电机组的基础上,再加一组发电机,采用冗余的供电方式,冗余设计是贯穿整体架构设计的方方面面,但这会大大提升复杂度,越复杂就越危险。
在2020 re:Invent大会上,Peter DeSantis张贴了这样一张图,横轴表示系统复杂度,纵轴表示故障造成的伤害(爆炸半径),原本的Switch Gear(配电控制系统)和UPS系统处在较为危险的位置。
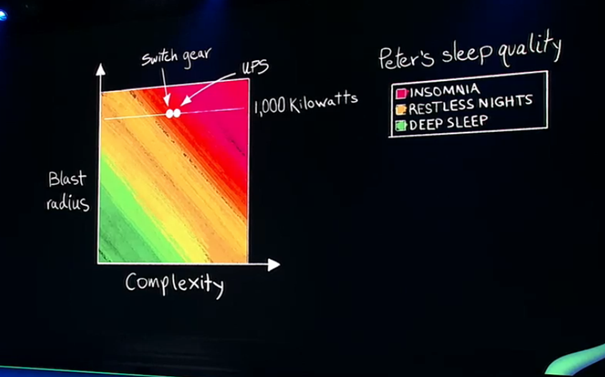
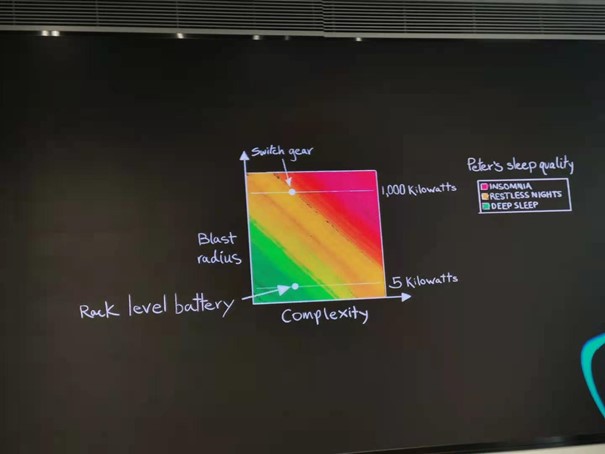
在Switch Gear(配电控制系统)和UPS系统的优化改造中,AWS通过自己写软件控制系统,删除一些没用的、添加部分对AWS有用的功能后,降低了系统复杂度,提升了系统的可靠性。在UPS系统改造中,标准使用小容量的电池,从而降低电池爆炸造成的危害,从而降低爆炸半径。
AWS数据中心级别的冗余设计
2000年左右,那是一个还没有AWS的时代,Amazon在美国西雅图有一个数据中心,随着业务规模的扩大,亚马逊开始意识到海啸和地震的潜在风险,不能把所有东西都放这里,于是就想在没有地震海啸威胁的美国东海岸建一个数据中心。
两个数据中心放的太近,可能遭受同一个自然灾害的侵袭,如果离得太远,延迟会带来数据同步的问题也同样不可接受,美国东西海岸的距离就会造成这一问题。所以,数据中心之间需要保持一定的安全距离,而且要保证一毫秒以内的延迟。
类似的,AWS强调多AZ(Avaibable Zone)与多机房的概念不一样,AWS每个Region有至少三个AZ,AWS认为多个AZ相互间要有一定的距离,以此来降低外部环境同时对多个AZ造成影响,来提升服务的可用性。
从Region的角度看,AWS为了减少Region间可能造成的干扰,设计原则上是将各个Region独立运作,一个Region出的问题不会传递到别的Region,在Region的级别提供冗余。
AWS供应链保障
2020年是黑天鹅满天飞的一年,突如其来的疫情,急剧增长的在线业务量,逼着所有云厂商在加班加点忙着扩容资源,AWS也不例外,就AWS的规模来猜测,扩容规模要远大于大部分云厂商。
为了保障扩容的顺利进行,AWS在供应链采购管理上采取了多元化策略,供应商的数量,供应商覆盖的国家和地区在数量上有了很大提升。如今,AWS的供应链系统覆盖7个国家,86家供应商,以此来暴涨供应链的稳定。
在疫情在全球爆发的2020年,多元化管理策略确实挺有价值,疫情的不确定性给供应链带来很大挑战,许多国家的生产环节和清关效率都出了很大问题,对此,周舸表示深有体会。
写在最后
在可用性方面,公有云作为公开可见的服务,更容易受到公众关注,造成公有云更容易出故障的印象。
抛开客观感受不说,由于公有云作为一种服务,而不是一个个on-premise产品盒子,要考虑的内容更多一些,比如供电,比如网络,比如运营能力等,确实非常考验云厂商的综合实力,需要有数不清的技术创新来打造更高的可用性和业务连续性。
随着一步步迭代和发展,技术只会更成熟,运营经验会更丰富。






