流计算作为炙手可热的技术被电商平台广为采用,来自苏宁易购IT总部的大数据平台高级技术经理陈丰,就在2018中国存储与数据峰会上发表了《流计算在苏宁的前世今生》的主题报告,有对业务场景和痛点的讲述,也有攻克技术难点的实际感受,令人记忆深刻。
 苏宁易购IT总部 大数据平台高级技术经理 陈丰
苏宁易购IT总部 大数据平台高级技术经理 陈丰
笔者将整份报告按四大模块梳理为:
第一部分,流计算平台的发展历程——从2014年到现在,4年多的发展历程中,苏宁经历storm->spark streaming->flink的转变,目前还在转变中。形成storm(4000~虚机节点),flink&spark streaming(200+物理节点,on yarn模式)的规模,同时介绍了各引擎发展过程中的问题以及解决路径;
第二部分,storm及spark streaming的缺点,从兼顾吞吐量和延时、高效的状态管理、Exactly-Once的保证及Event-Time等要点阐述了苏宁选择flink的理由;
第三部分,苏宁基于flink框架所做的具体工作。(1)平台层功能丰富:sql语法丰富(distinct,流表join),算子自动扩缩容,connector(mysql, hbase,kafka1.0)以及sink降速(2)工具层:统一日志收集及展示、平台层和业务层的统一监控管理平台(3)服务层:Dlink 一站式开发平台;
第四部分是在数据集成、机器学习和CEP等方面,谈谈苏宁对未来的展望。
目前,陈丰主要负责苏宁易购集团大数据流计算平台建设,包括Storm、SparkStreaming、Flink等组件,经历了流计算从组件化到平台服务化到智能化的发展过程。对于大数据开源框架有较为丰富的经验,在分布式计算架构设计和系统优化方面有自己的思考和领悟:
既然说到前世今生,首先介绍一下流计算平台在苏宁的整个发展历程,怎么从Storm到目前很火的Flink,以及它的现状,谈谈整体的架构以及它的整体集群规模。2018年上半年,苏宁把主要精力都投向了Flink。
首先看一下平台的发展历程。

最早2014年苏宁上线了第一个Storm的大屏展示任务,同年Storm整体的孵化平台上线。到了2015年因为对于SQL开发的需求苏宁还是比较多的,苏宁自研了一套基于安踏做SQL的平台。2016年基于吞吐量的上线,有了spark streaming,同年考虑到性能和流计算的痛点,把目光投向了Flink。到了2018年,Flink是苏宁流计算基础平台重要的目标项目,将业务推到Flink上做,比如说Flink的开发平台、管理平台等等一系列配套的业务上线。
再看流计算在苏宁的配套。Storm2014年就用了,整体规模和占比比较多50%,物理机1000多,虚拟机4000+,任务数1500+。苏宁做Flink起步较晚,但调研时间比较长,目前占比占到15%,计划未来1-2年都会把流计算底层平台所有的都投入到Flink上。
为什么选择Flink?从苏宁业务层面来看,首先Storm和2.0的spark streaming都使用的是processing time,它处理的时间远晚于数据产生的时间,产生大量的数据再1或2小时堆积后,数据是错误的,没办法接受的。第二个就是容错能力,Storm只能做到 Exacly once。第三个就是中间状态的维护,Storm维护不提供state的东西,做中间状态的维护只能依靠第三方来做,那么业务开发的时候成本相对高一些,会写很多的代码,效果也不是很好,因为它用第三方组件的时候,有可能出现一致性问题,或重启后计算结果不准确等等。从苏宁的平台来看,两者都没有办法兼顾高吞吐、低延时,两个性能互补,但不能兼顾。
调研阶段,对Flink的各个优势做过简单的列表,Flink是一个设计的比较优雅的流计算框架,它能兼顾到低延时和高吞吐,同时支持Exacly once。
谈谈在功能扩展、服务平台开发以及运行时管理系统方面的经验分享。
首先说一下功能扩展。Flink sql从它出来就比较火,为什么,因为很简单,SQL对于程序员来说非常熟悉,开发成本非常低,同时由于SQL是一个统一的标准,它的迁移成本非常低的,如果今天用了subeg SQL,明天出的新的组件,可以非常轻松的迁移到其它的组件上,它是通用的语法。所以苏宁FlinkSQL上做了一系列的语法扩展。另外Connectors,可以打通不同组件的联系。
最后结合业务痛点,聊一下在运行时的它的算子动态扩容缩容,以及Checkpoint动态调整,我们怎么实现怎么把它做出来的。
(1)首先看一下语法扩展。因为我们从StormSQL开始就做了纯SQL的开发,纯SQL开发起码要支持DDL和DML,但是Flink社区明确的讲述它不会做DDL的事情,这件事由我们自己做出来。然后是DML语言,对于电商领域来说很典型的事情就是统计UV,对于这种聚合也做了大量支持,支持on group by,over window,group by window。同时Flink版本有它的局限性,它的流数据和静态数据是没有办法去做互相操作的,然后最后说一个batch window,后面会具体的说说。
count distinct,这个当时基于0.003做的,当时社区没有提供,我个人认为是由于整体代码的抽象上的问题,它没有去做指导,只能1.7去实现了,方式和现代社区几乎是基本上一致的。
 多介绍一下Approx count distinct,它的目的其实和count distinct语法是一样,也是去重复的结构,但是它的目的是用较小的计算精度的误差换取巨大的计算资源的节省,比如说内存。同时这个语法符合Calcite标准的,也就是说是通用的语法,我们可以迁移到其它的引擎上。
多介绍一下Approx count distinct,它的目的其实和count distinct语法是一样,也是去重复的结构,但是它的目的是用较小的计算精度的误差换取巨大的计算资源的节省,比如说内存。同时这个语法符合Calcite标准的,也就是说是通用的语法,我们可以迁移到其它的引擎上。
这边只能粗略的讲,看它怎么工作的。首先一条SQL进来进入Calcite做语法解析、变换。然后转到Data program的时候,我们做定制化的基数和函数,基数和函数不扩展讲了,因为其实涉及的算法不少,我们实现了一系列的基数的函数,让用户选择相对应的精度,然后对应它的资源消耗,让用户自己去做选择。然后回到我们Data program这一层,进而转化成用户选择的基础方程。到了下一层,每条数据进来的时候将进行累加,输出时可以把数据向下一层的sink进行触发计算,可以提供相对完美的容错能力。
(2)另外一个SQL Batch window,这个是苏宁特色的一个名词,我们看一下它业务需求的case,它需要统计每日PV、UV,我们在线计算要求延时尽可能低,不可能等到每天结束的时候零点再看到结果,这个不能接受的。业务的需求是每秒都能实时的检测到PV、UV的变化,这个从开始到第一秒第二秒第三秒都能看到结果,这个是业务能够接受的case,这个是输出的频率,这个频率是可以定制化的。直到这个窗口的结束,我们的结果会被reset,重新开始被计算,这个是苏宁常用的Batch window。
怎么用SQL实现Batch window?这点不难,但怎么体现到SQL语法,又不能破坏标准的SQL语法呢?滑动窗口它是可以做到很短的输出,但是不能固定窗口,窗口滑动到下一秒。第三条就是定制trigger。第四条就是Cascading window,它的窗口是固定的,10点到11点,数据没有超出的时候是不会被滑动的,同时做到及早的输出,但是它的问题是每条数据都输出,不能控制输出频率的。第二点如果TPS非常高,一秒一万,一秒十万DB吃不下,会造成瓶颈。
所以我们怎么实现苏宁的Batch window?我们用最后讲的这个,加上DDL,定义输出的间隔,然后再使用我们自己实现的Periodical sink,它主要的目的是把每一条进来的数据都进行缓存,并且能够根据输出的频率和数量的阀值进行定量的输出,整个链路进行的数据都会触发计算,每个数据出来之后进行缓存,旧值被新值覆盖,直到task输出的时候,首先满足定性定量的输出,第二个不会对于下层造成太多的压力,因为定点定时输出,TBS只有2000左右。这个时间我觉得还是有进一步扩展或者是优化的空间,比如说其实这个的话只在sink层面解决了需求,如果我们在Batch window里面不把数据进行一条条处理,而是进行批处理,我觉得计算的效果效率会真正提升,这个可能我们后面会去做这件事情。
刚才非常简单的举了几个例子,说了一下SQL的扩展。说一下Connectors。这个我不会多说,因为内容不多,我会举例子来说一说。
HBase Sink实现两种模式,主要是考虑它的容错性,现在不会只满足于端到端正的容错,我们还希望它能做到Flink和组件之间的容错。于是我们针对不同的业务场景做了幂的插入模式,一种是mini wbatch,容错,有可能会Failover,要求Failover后业务重发的数据与Fail前完全一致,同时我要求table是单版本的,这么一个sink。同时考虑到效率和实时性,我们也做了两种写入模式,一个是one by one的同步写入,效率比较高。还有mini batch,异步写入的,它的演时比较高,但是可以做到定时和定量。
刚才讲的是幂的插入模式,现在讲非幂等插入模式。Failover后写HBase结果与fail之前不同使用的WAL机制。我们用Checkpoint时,将mini batch写入外部文件系统。Checkpoint完成,将mini batch写HBase。
下面来说一说业务上也经常面对的这么一个问题,就是扩容缩容的问题。我们看一下流程的分析,首先业务开发两种模式,一种是写SQL,还有一种是写Flink SQL,还有一种是用Datastream API而进行开发。上线之后发现并行不够,需要扩容,扩容的话对于SQL来说,我能做到的是什么,我可以用原生的Flink提供的去进行工作,把链路上的节点都进行扩容或者缩容,同时对于重新打包发布,然后再去重新上线的那些,这两种开发模式都有问题,SQL的开发面对双十一零点的大促,我们需要改代码,并且还需要有高的延迟,业务才能上线,这个我们不能接受。总体对于SQL开发它的扩容是任务级别的,而对于Datastream成本太高了。
我们做了Operator,我们一开始考虑是从wrong time考虑这个事情的。如果说我们要从这一层做的话,首先对元码改动比较多,第二个任务相对比较复杂,我们需要重新生成不同的job,同时还要有我们自己运行时的管理服务系统,我们会把某个需要去RESCALE的 job拿过来进行修改,再把提交新的JOB graph,做真正扩缩容的事情。这边着重说一下这个DO RESCALE会再领任务,资源不会释放的,资源部释放意味着响应的时间非常快,我们也做过实验,基本上到达秒级别甚至百毫秒级别做到扩容缩容,这个就是我们的解决方案。

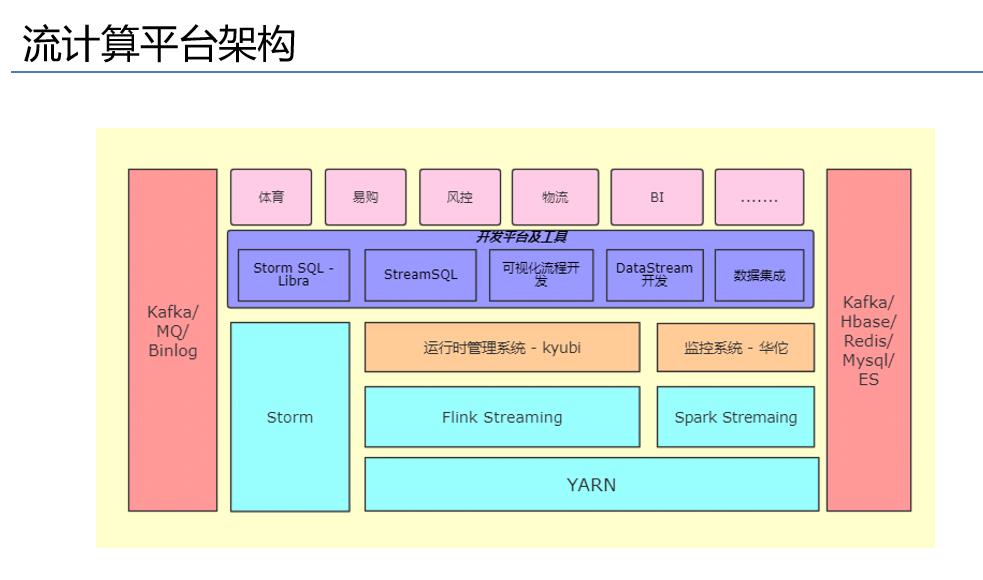
刚才介绍了基础的组建的扩展或者优化,现在来聊聊平台服务化。首先看一下流计算平台的架构,从左往右看,这边是数据元,底层进来之后有Storm,然后是Flink streaming和spark streaming,上面有我们运行时管理系统,主要的作用是对业务进行监控、运维、报警一系列的事情。再往上一层是自己开发的一个开发者平台或者工具层,对于Storm来说有Storm SQL LIBRO,还有Stream SQL 还有,可视化流程开发,Datastream。再网上就是支持我们的业务,体育、易购、风控、物流、BI等业务层。
我是做平台的,主要介绍一下平台层,也是工具层,下面运维的这么一个系统。
平台服务首先是Stream SQL开发平台,还有就是这个可视化流程开发平台。

我们的Stream SQL是元数据处理,通过拖拉拽动态的生成我们的语句,可以支持整个的流程开发,从编写到测试到业务上线,都可以这个平台去做,业务完全不用写代码,直接写SQL,在上面做就行了。
第二个可视化流程开发,把功能拽上来,建立它们之间的关系就可以了,同样可以做到流程生命周期的事情,都能涵盖。
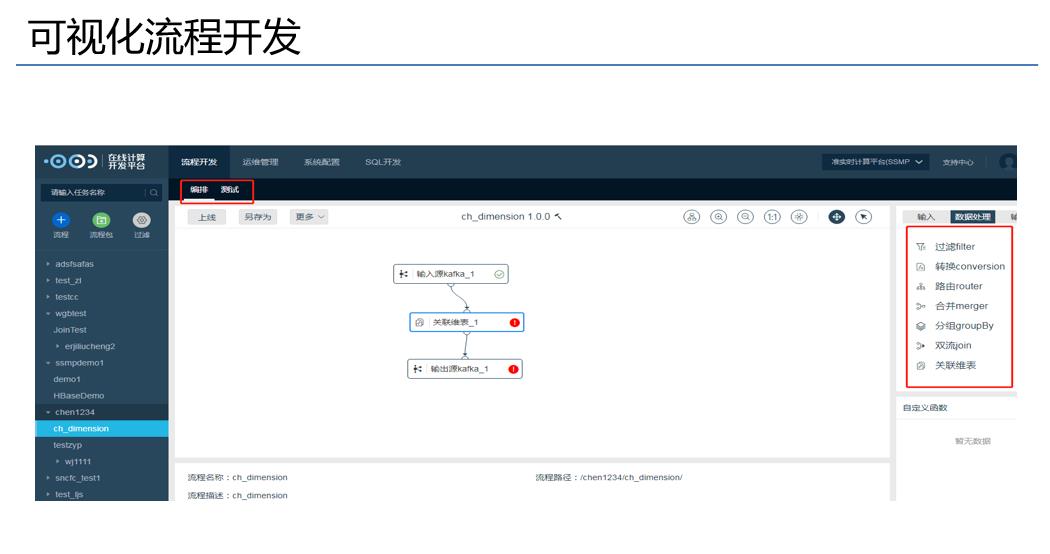
最后任务提交,我们对于这个Flink底层的元码也做了修改,也是觉得它很多的关于Checkpoint很多的行为要通过代码体现的,我们觉得这个非常不灵活,所以我们对于底层做了相应的修改,只需要在提交的时候对于进行配置,就能做到动态的去设置和修改它的相对应的行为,只要一键提交就可以了。
下面看一下运行时管理。运行时管理主要解决了一下这些事情。解决了Flink运行时以及历史日志的问题,我们做平台的时候,Flink的运行时日志可以通过原生的UI看的,但是在使用过程中去做历史日志就相当有问题了,它往往要通过YARN日志查看,所以业务用的时候非常头痛。针对这一点我们提供了统一的日志解决方案,同时还有一些子代的Metric的查询,我们也弄出来做了统计和展示。同时我们也把一些比较重要的事件也从我们的APP里截出来,比如说交互启停的动作做了展示和通集。其次就是刚才描述的运行时的运行调整,比如说调整Operator并行度,还有在线调整。最后还有告警。
日志查看,通过任务名查,也可以通过关键字搜索。Metrics监控也是类似的,可以卡时间范围,也可以不同维度查询,并且做了一系列的聚合,为用户提供相对有效的信息,提供给用户比较有用的信息。
对于事件的接触我们也做了相对的统计,左边可以看到备压等等一系列事件的统计,我们可以统计Checkpoint成功率,以及Checkpoint它的打下分布等等一些事情。动态修改Checkpoint并行度。
最后简单的展望一下未来,2019工作计划。首先我们可能会考虑一下做机器学习,据官方所称,对于迭代计算, Flink应该是比spark还要快的,看有没有办法实现流处理的机器学习的算法模型。第二点就是去做通用的数据集成,因为Flink首先实时计算,同时它也提供了很多sink或souser,把组件连接起来。第三个就是智能动态扩容,现在的扩容都是手动的,如果有可能的话可以用STM做一些算法。最后一个是CEP的事情。