
存储特征
存储子系统可通过许多方式来改善性能,那些方式通常与高速缓存和数据精简有关,但它们最终的性能与存储媒体有很大关系。 我们将在本文中重点讨论几个具有不同特征的驱动器的例子,不同的特征对应着不同的存储级背后的不同目的。
表1通过简单地方式解释了这些差异,表1重点列出了现有各类存储媒体中的主流媒体技术(固态硬盘、光纤通道、SAS和SATA)。 例如,如果重点是廉价的容量存储设备,那么就适合使用SATA。 另一方面,如果速度是企业关注的重点,而且成本不是问题的话,那么固态硬盘则是最佳解决方案。
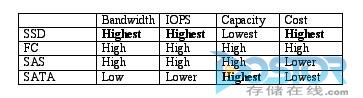
表1:常用驱动器类型的特征
这里想要表达的意思是存储媒体具有不同的特征,可以根据需要储存的数据来决定选用哪种存储媒体。 我们将用存储分级的概念来进一步探讨这个问题。
注:除了传统的磁盘接口之外,还有很多不具备本地磁盘接口的接口。 这方面的例子包括Infiniband、FCoE和iSCSI。 随着这些协议和接口的推广应用,解决方案市场也随之发生改变(注意Infiniband和10GbE为存储系统创建了更多的决策点)。
存储分级
存储分级的概念并不是个新概念,这种概念早就存在了,以前使用的名字是分层存储管理(Hierarchical Storage Management)(HSM)。 HSM被定义为一种存储技术,它可以在高价存储元件(比如存储设备中的光纤通道驱动器)和廉价存储元件(比如光盘)之间移动数据。
IBM率先将这个概念应用到它的主机计算机中,随后又将HSM技术推广到它的AIX操作系统之中。
虽然这个概念并非新概念,但是各种存储技术的发展已经让这个概念变得比以前更加重要。 回头看看表1,现在的驱动器技术和存储协议以及总线将存储划分成了多个领域,这样就形成了多种具有不同成本和速度的存储解决方案。
分别根据性能和成本来决定使用的驱动器类型,结果就得到一个分级存储架构(许多厂商都采用了这种方法,如图1所示)。
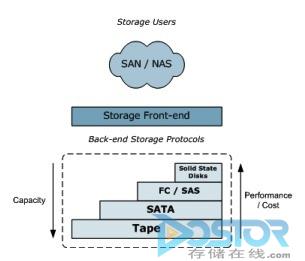
图1:分级存储架构
在最理想的情况下,我们会把所有的数据都储存在速度最快的存储媒体上(斯坦福大学提出的RAMClouds架构就是这方面的最佳例子)。 但是由于成本也是个不容忽视的因素,必须将它考虑进来。 因此,一个容量为1MB的文件储存在固态硬盘中的成本要大大高于它储存在消费者SATA硬盘中的成本。 其次我们还要考虑数据被访问的频率。 如果我们需要频繁使用并要求快速存取某个文件,那么最好还是将那个文件储存在固态硬盘上。 如果某个文件只是我们很少会用到的旧数据,那么将它储存在成本相对较低的SATA硬盘上则是最好的做法。
我们的目的是将频繁使用的数据储存在固态硬盘上,将很少使用的数据储存在廉价的存储设备上,从而优化数据的总成本。 为了实现那个目标,我们首先必须搞清数据的使用情况。
自动化数据迁移
与许多复杂的技术一样,实现自动化数据迁移也有很多不同的方式。 最常用的一种方案是存储虚拟化,这种方案将用户对存储设备和磁盘上的实际存储映射抽象化了。
在一个存储系统内部自动迁移数据的能力与这种映射有很大关系,有了它,数据才能被重建。 数据重建方案包括在元数据中,元数据详细规定数据如何在各种存储子系统中分布。
除了各种实现形式(我们将在后面详细探讨这个问题)之外,数据迁移时的数据粒度问题也有很多需要权衡考虑的地方(见图2)。 每一种数据粒度方案都有各自的利弊。 例如,有些厂商采用LUN级的迁移,从概念上来说这很简单,但是那同时也意味着一个LUN中的所有内容都将按照同样的方式来对待和处理。
也有一些厂商采用了低于LUN级的数据迁移,可以以不同大小的数据块的形式进行。 低于LUN级的数据迁移有一定的优势,比如可以将使用频率高的数据迁移到速度相对较快的存储级,而将LUN中的其他数据迁移到相对廉价的存储级。
低于LUN级的数据迁移也有一定的成本,因为元数据必须控制数量众多的单个数据块(数据块越小,效率就越低)。 另外,如果被迁移的数据块大于一个分区,那么可以通过预读的形式实现性能提升(例如,假如数据块中的各个分区都是逻辑相关的)。
数据迁移解决方案的一个重要特征是效率。 解决方案应该将任何对存储性能的影响都降低到最低水平。 其他需要权衡考虑的因素还包括数据被分类的方法、数据迁移解决方案的执行频率、数据的初始布局等等。
例如,有些数据迁移解决方案是在后台 执行的(夜间进行),而有些数据迁移解决方案是实时执行的。 虽然可能会导致滞后现象,但是实时数据迁移解决方案可以根据用户使用数据的情况动态灵活地作出反应。

图 2:数据迁移的程度
执行类型
数据迁移可以通过多种方式执行,但主要被分为三种基本类型:主机、网络 和目标。 让我们先简单介绍一下这三种类型,然后再谈谈每种类型的具体执行情况和例子。 图3以图形的方式形象地展示了这三种类型。
基于 主机的执行方式将分级和迁移都集成到了主机服务器中。 虽然从单用户存储的角度来说这样做会有一定限制,但是虚拟化技术可以解决这个问题,而且还使这种执行方式能够支持多用户(多虚拟机)结构。
例 如,操作系统可以将这种功能整合到它们的逻辑卷管理程序(比如Linux的LVM)之中,管理程序可以并入存储栈中。 VMware就在Storage vMotion中采用了这种解决方案,Storage vMotion可以让活跃虚拟机磁盘在不同的存储媒体间进行迁移。 它先是利用变化分区跟踪在后台高效迁移虚拟机磁盘,最后再暂时中止虚拟机,将剩余分区移动到目的存储媒体。
基于网络的执行方式在网络中的 存储用户和物理存储之间加入了一个中介物。 这样不但分担了主机的功能,而且还可以支持不同厂商的存储后台。 基于网络的执行方式的例子包括IBM的SAN Volume Controller(SVC)、惠普的SAN Virtualization Storage Platform(SVSP)和FalconStor的Network Storage Server(NSS)。
最后,基于目标的执行方式是将数据迁移的执行放在存储阵列中进行。 与基于网络的执行方式一样,虚拟化数据可以减轻主机的负载,在目标位置建立一个抽象物。 这个抽象物建好之后,就可以实现其他的高级功能了,比如数据精简等。 现实中有很多基于目标的执行方式,比如EMC的FAST、Compellent的Data Progression、3PAR的Dynamic Optimization和其他厂商的其他方案等。
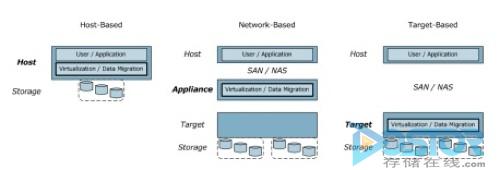
图3:执行类型

