传统的HPC(高性能计算机)、超级计算机一般采用CPU构架,很少会使用到GPU。而随着通用 GPU(GPGPU)的出现,让这种传统架构正在被打破,通用GPU正成为并行计算系统的新的异构解决方案。
最早提出通用GPU概念的是AMD,GPGPU(General Purpose GPU,通用计算图形处理单元)可以处理原本由CPU完成的处理任务,并且在某些方面可以做得更高效。这让HPC可更好的在几何造型、数值计算、流体模拟、三维重建、场景绘制、数据库操作等领域发挥作用。
2006年11月16日,AMD在Supercomputing展览会上推出了世界第一款专门针对企业高性能运算的汇流处理器Stream Processor,主要针对高性能运算系统设计,采用AMD CTM技术,可令运算效率大幅提高,可在财务分析、地震偏移分析、生命科学研究以及其它领域大展拳脚。AMD称,Stream Computing(汇流运算)可普遍应用在每秒数百次的3D绘图运算等大量并行运算处理上,能广泛应用在科学、企业及消费端运用面上大量的处理效能上,并相比使用传统处理器有更佳的效果,大幅节省企业花在计算这些复杂信息的运算时间。这是业界第一款通用GPU,也是首款针对企业空间提出汇流运算解决方案的硬件。
当然,要想通用GPU在超级计算领域走向普及,软件的支持必不可少。随着NVIDIA CUDA(Compute Unified Device Architecture)平台的推出,让通用GPU概念得以实用化。CUDA是用于GPU计算的开发环境,它是一个全新的软硬件架构,可以将GPU视为一个并行数据计算的设备,对所进行的计算进行分配和管理。其可更充分的发挥GPU的特点,在处理密集型数据和并行数据计算方面大显身手,这让CUDA非常适合需要大规模并行计算的HPC领域。
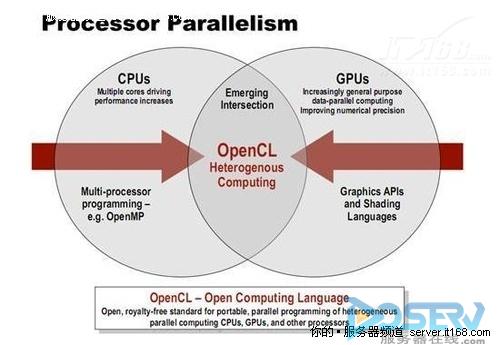
图1 在OpenCL、CUDA等通用开发平台的支持下,异构系统的障碍在被扫清
而随着OpenCL、Direct Compute的现身,则逐步将这类平台推向了高潮。OpenCL全称Open Computing Language,是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、通用处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。OpenCL是首个开放的免费通用并行计算标准,可统一管理一台主机的所有计算资源 (含CPU、GPGPU),OpenCL可将这些资源统一看作计算单元,共同发挥运算能力完成各类计算任务。OpenCL统一编程环境,让开发者也能轻松利用异构平台写出高效的程序来。
微软在DX11中引入了通用计算接口标准Direct Compute亦值得关注,其在渲染架构中新增的Compute Shader,可更大限度发挥通用GPU的并行计算优势,将其应用范围从单纯的图形渲染拓展到更多计算领域,因此通用计算性能的高低将在今后成为衡量显卡整体性能的一部分。通过降低系统资源开销与提高效能,新的Direct Compute可让新一代显卡具有更强的通用计算效能。
这些开发平台的出现为GPGPU的规模化应用扫清了障碍,一些划时代的产品正在研制中或被推出。Intel、 AMD皆为此孜孜不倦,而NVIDIA抢先推出的最新GPU"费米(Fermi)"则是这方面最具代表意义划时代的通用GPU产品,其双精度浮点计算性能的大幅度提升可更好满足当前工程领域高性能计算的需求。
异构HPC纷现
通用GPU正一步步向用户走来。虽然通用GPU目前要想完全取代CPU尚不现实,但通用GPU可以和CPU配合组成异构系统来实现更强劲的计算性能,特别是图形计算性能。这是因为通用GPU是专门为图形运算而设计的,考虑到了图形运算的特殊性。这让其更适合用于海量数据重复运行场合,更适合处理SIMD运算、科学计算、数据库分析等高性能计算需求。这让通用GPU正逐步成为前沿用户关注的焦点,而通用GPU的市场化之路也正被打开。
通用GPU要想在市场上获得突破,显然HPC领域将成其最大的最具代表意义的阵地。最有名的异构系统是著名的超级计算机"Roadrunner(走鹃)"。其每个节点由一台Opteron刀片服务器加上两台PowerX Cell刀片服务器组成。其中,6912颗(早期的配置)双核Opteron主频仅为1.8G,只能提供49.8TF的峰值浮点,因此,Roadrunner的运算能力几乎全部由PowerX Cell提供,而且效率超过了75%。虽然由于采用通用化不足的Cell让走鹃很难用,但这让很多用户看到了异构系统强大的一面,让异构计算成为近年 HPC领域的新趋势,并在国际高性能计算领域掀起一阵热潮,被公认为提高HPC性能的有效手段。
此后,国内的"天河一号"超算在这方面也进行了实验。天河一号也是款异构系统,其采用6144个Intel通用处理器(3072×2 Intel Quad Core Xeon E5540 2.53GHz/E5540 3.0GHz),和5120个AMD GPU加速处理器(2560 ATI Radeon 4870×2 575MHz),内存总容量98TB,点对点通信带宽40Gbps,共享磁盘总容量则达到1PB。在该系统的帮助下,其以每秒钟1206万亿次的峰值速度和每秒563.1万亿次的Linpack实测性能,勇入TOP500榜十强。

图2 新一代通用GPU正成为异构HPC的最佳解决方案
而"星云"则是近期异构系统最耀眼的新星。伴随最新TOP500超算排行榜的公布,中国超级计算机"星云"让全世界为之一震,其峰值理论运算能力达2.98PFlop/s,而Linpack性能为1.27PFlop/s,位于第35届超算排行榜第二位,这也是中国超级计算机在TOP500榜单历史上的最高名次。星云超级计算机采用自主设计的HPP体系结构,处理器是32nm工艺的六核至强X5650,并且采用了 NVIDIA Tesla C2050 GPU做协处理,由4640个计算单元组成。在这种高效异构协同计算体系的支持下,让其性能倍增,并能更好的应用于云计算等领域。而其中的亮点Tesla 20系列通用GPU基于代号为"Fermi"的下一代CUDA架构,支持技术与企业计算所"必备"的诸多特性,其中包括C++支持、可实现极高精度与可扩展性的ECC存储器以及7倍于Tesla 10系列GPU的双精度性能。Tesla C2050与C2070 GPU旨在重新定义高性能计算并实现超级计算的平民化,与最新的四核CPU相比,Tesla C2050与C2070计算处理器可以十分之一的成本和二十分之一的功耗就可实现同等超级计算性能。
在最新的TOP500超算榜上我们还注意到位于19位的Mellanox Mole-8.5超级计算机也采用了异构系统,该机位于中国科学院过程工程研究所。Mole-8.5系统共计有372个计算和数据处理节点(Node) –4U的双路GPU服务器TYAN FT72-B7015,其可嵌入2颗Intel Xeon 5520系列处理器和6个NVIDIA Tesla C2050系列通用处理器,几乎可以达到4Tflops双精密度最高效能的理论值。这让Mole-8.5系统可提供高达207.3TFlops的最高运算效能理论值。数据中心不仅能够提供给客户最大的运算能力,还可以提供先进的流动点的数据处理能力,满足研究和设计的不同需要。使用户能够缩短运行科学发现过程中至关重要的应用程序所需的时间,过程工程研究所亦正使用Mole-8.5在化学工程、材料科学、生物化学、数据与图像处理、石油开采与采收率以及冶金等领域开展科学模拟。
后记

图3 在个人HPC和普通服务器领域,异构系统的力量也在展现
通用GPU不仅在TOP500排行榜上、在超级计算机领域开始展露头角,在普通HPC和个人HPC、服务器方面也在批量展示实力。Appro的1U Tera GPU服务器,采用两颗AMD Opteron 6100八/十二核心处理器或两颗Intel Xeon 5500/5600四/六核心处理器,配备了四块Fermi Tesla M2050,拥有1792个流处理器,可满足HPC客户对低价位、高密度和超级计算性能的需求。Supermicro提供GPU计算系统FC405,在 4U塔式机箱SC747TQ-R1400之内并排安放四块Fermi Tesla C2050,搭配Xeon 5500/5600系列处理器,还支持八个热插拔3.5寸SAS/SATA硬盘位,适合集群配置和个人HPC。浪潮倚天Tesla HPC集群以更低的功耗,更低的成本给客户提供超级计算性能,相比标准的只有CPU架构的集群,Tesla预配置集群使用更少的系统,氧气泵采用 NVIDIA Tesla S1070计算系统搭建,S1070系统每个GPU计算单元有4 GB的专用存储器,支持IEEE 754单精度和双精度浮点数;提供1个快速102GB/sec的GDDR3内存接口,可以加速到节能并行计算的转变,而且可以通过规模化来更快、更准确地解决世界上最重要的计算挑战。总之,在通用GPU的推动下,服务器和HPC的异构时代正悄然到来,这种趋势已变得势不可挡。