
今天,美团 LongCat 团队正式发布全新高效推理模型 LongCat-Flash-Thinking。在保持了 LongCat-Flash-Chat 极致速度的同时,全新发布的 LongCat-Flash-Thinking 更强大、更专业。综合评估显示,LongCat-Flash-Thinking 在逻辑、数学、代码、智能体等多个领域的推理任务中,达到了全球开源模型的最先进水平(SOTA)。
同时,LongCat-Flash-Thinking 不仅增强了智能体自主调用工具的能力,还扩展了形式化定理证明能力,成为国内首个同时具备「深度思考+工具调用」与「非形式化+形式化」推理能力相结合的大语言模型。我们发现,尤其在超高复杂度的任务(如数学、代码、智能体任务)处理上, LongCat-Flash-Thinking 具备更显著的优势。
再贴一遍龙猫大模型的链接:
目前, 该模型已在HuggingFace、Github全面开源:
- Hugging Face:https://huggingface.co/meituan-longcat/LongCat-Flash-Thinking
- Github:https://github.com/meituan-longcat/LongCat-Flash-Thinking
领域并行强化学习训练方法
(Domain-Parallel RL Training)
为了解决强化学习领域混合训练的稳定性问题,我们设计了一种领域并行方案,将STEM、代码和智能体任务的优化过程解耦。这一方法采用了多领域并行训练再融合的先进策略,实现模型能力的均衡提升,综合性能达到帕累托最优(Pareto-Optimal)。
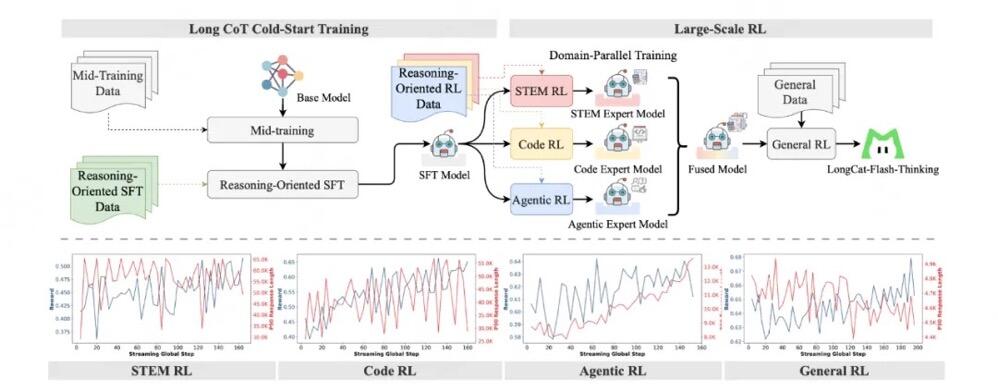
图1:LongCat-Flash-Thinking 的训练流程
异步弹性共卡系统(Dynamic ORchestration for Asynchronous rollout — DORA)
我们的异步弹性共卡系统(DORA)是整个训练的基石。该系统通过弹性共卡调度(Elastic Colocation)与多版本异步流水线(Multi-Version Asynchronous Pipeline)设计,在实现相较于同步RL训练框架三倍提速的同时,确保了每条样本的策略一致性。同时,系统进一步实现了高效的 KV 缓存复用,能够支撑万卡规模集群的稳定运行。
智能体推理框架(Agentic Reasoning Framework)
为进一步提升模型的智能体推理能力,我们提出了创新性的“双路径推理框架”。该框架能够自主筛选最优查询样本,并通过自动化流程将智能体推理与工具使用相结合,使模型能够智能识别并调用外部工具(如代码执行器、API等),从而高效解决复杂任务。基于AIME25实测数据,LongCat-Flash-Thinking在该框架下展现出更高效的智能体工具调用(Agentic Tool Use)能力,在确保90%准确率的前提下,相较于不使用工具调用节省了64.5%的Tokens(从19653到6965),显著优化了推理过程的资源利用率。,时长00:08
形式化推理框架(Formal Reasoning Framework)
为了克服当前开源通用大型语言模型在形式化证明任务中的不足,我们针对形式化推理设计了一套全新的基于专家迭代框架的数据合成方法,该流程利用集成了 Lean4 服务器的专家迭代框架,生成经过严格验证的证明过程,从而系统性提升模型的形式化推理能力。这一创新方法系统性地增强了模型的形式化推理能力,提高了其在学术和工程应用中的可靠性。
LongCat-Flash-Thinking在多项权威评测中刷新纪录,在各类推理任务中均展现出持续领先的性能:
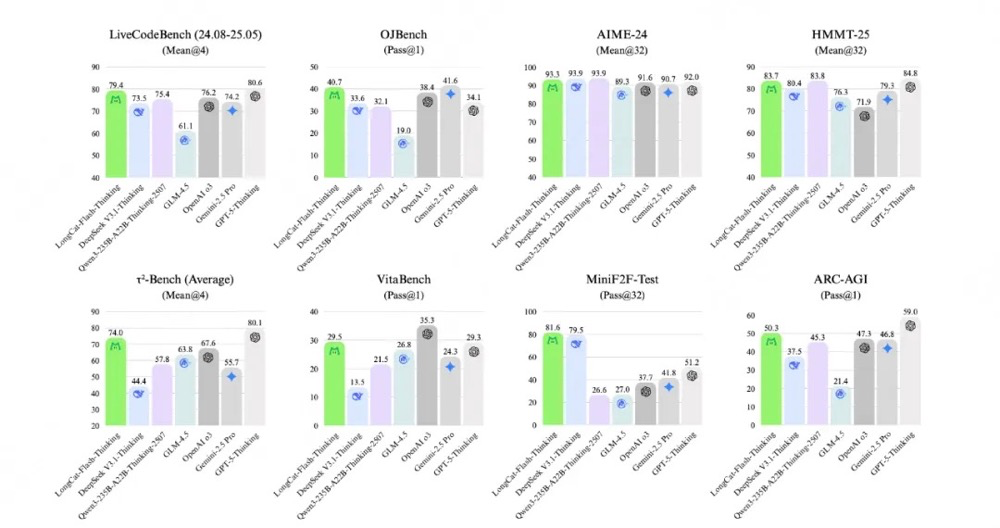
- 通用推理能力:LongCat-Flash-Thinking 具备卓越的通用推理能力,尤其在需要结构化逻辑的任务中表现突出。其在 ARC-AGI 基准测试中以 50.3 分超越 OpenAI o3、Gemini2.5 Pro 等顶尖闭源模型。
- 数学能力:LongCat-Flash-Thinking 在数学推理方面展现出强大实力,跻身当前顶尖模型行列。在更具挑战性的基准测试中优势更加明显——在 HMMT 和 AIME 相关基准上取得突破性成绩,超越 OpenAI o3,和 Qwen3-235B-A22B-Thinking 等领先模型水平相当。这些结果印证了其解决复杂、多步骤问题的领先能力。
- 代码能力:在编程领域,LongCat-Flash-Thinking 展现出开源模型最先进的性能(SOTA)与综合实力。在 LiveCodeBench 上以 79.4 分显著超越参与评估的开源模型,并与顶级闭源模型 GPT-5 表现相当,证明其解决高难度编程竞赛问题的卓越能力。在 OJBench 基准测试中也以 40.7 的得分保持极强竞争力,并接近领先模型Gemini2.5-Pro的水平。
- 智能体能力:LongCat-Flash-Thinking 在复杂的、工具增强型推理(Tool-augmented Reasoning)方面表现突出,在智能体工具调用(Agentic Tool Use)上展现出强劲能力。其在 τ2-Bench 上以 74.0分 刷新开源SOTA成绩,并在包括 SWE-Bench、BFCL V3 和 VitaBench 等基准测试中展现出超强竞争力。
- ATP 形式推理能力:LongCat-Flash-Thinking 在 MiniF2F-test 基准中的 pass@1 获得67.6的分数,大幅领先所有其他参与评估的模型,在 pass@8 和 pass@32 中同样保持了领先优势,凸显其在生成结构化证明和形式化数学推理方面的绝对优势。






