导读
近些年来,大推理模型(Large Reasoning Models,简称 LRMs)借助强化学习(RL)在逻辑推理、数学运算以及编程任务等多个领域均取得了令人瞩目的进展。不过,目前这些模型的应用主要聚焦于短上下文任务(比如上下文长度为 4K tokens 左右)。但在现实的实际应用场景里,像开展深度研究工作或是进行法律分析时,往往需要处理长上下文信息(例如上下文长度达 120K tokens),这无疑对模型的上下文理解能力以及多步推理能力提出了更为严苛的要求。鉴于此,阿里巴巴 Qwen-Doc 团队重磅推出了 QWENLONG-L1,这可是首个专门为长上下文推理任务量身打造的强化学习框架!
文字编辑|宋雨涵
1
QWENLONG-L1的核心技术亮点
强化学习驱动的长文本推理新范式
阿里QwenLong-L1-32B是全球首个基于强化学习(RL)训练的长文本推理模型,其核心创新点在于融合了GRPO(组相对策略优化)与DAPO(直接对齐策略优化)算法,并结合规则与模型混合奖励函数,显著提升了模型在复杂长文本任务中的准确性和稳定性。通过渐进式上下文扩展策略,模型分阶段增加输入长度(最高支持13万Token),结合难度感知的回顾性采样,实现了从短文本到长文本推理能力的平滑迁移。此外,训练过程中采用了课程引导的强化学习和预训练模型蒸馏技术,确保模型在数学、逻辑推理等多领域的高效优化。
2
性能表现
对标国际顶尖模型
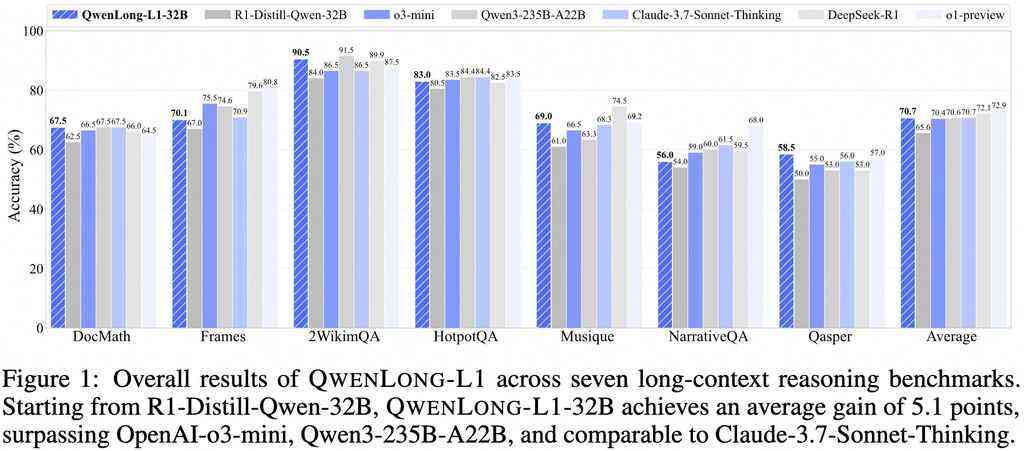
据相关介绍,QwenLong-L1-32B最为突出的优势在于它具备令人惊叹的13万个Token的上下文长度。这一特性赋予了它处理超大规模文本输入的能力,能够游刃有余地应对复杂且多层次的信息整合任务。相较于传统模型,QwenLong-L1-32B 在长上下文处理方面,成功实现了从短上下文到长上下文推理能力的自然、无缝衔接,充分展现了其卓越的泛化能力。
在七项长上下文问答(DocQA)基准测试里,QwenLong-L1-32B展现出了超凡的实力。它的性能不仅大幅超越了OpenAI 的 o3 – mini模型以及阿里巴巴自家的Qwen3 – 235B – A22B模型,甚至在表现上已经十分接近Claude – 3.7 – Sonnet – Thinking模型的水平。这一成绩无疑彰显了阿里巴巴在长上下文推理领域深厚的技术沉淀与强大的研发实力。
QwenLong-L1-32B是专门为处理高复杂度任务而设计的,适用于以下多种场景:
- 多段文档综合分析
它能够高效地对多篇文档的信息进行整合,精准提取关键要点,并展开深入细致的分析。 - 跨文档跳跃推理
可以在多个文档之间进行逻辑推理,迅速捕捉文档之间的关联信息,挖掘隐藏的逻辑关系。 - 金融、法律与科研场景
为合同分析、财务报表解读以及学术研究等需要高精度推理的复杂领域,提供了强有力的支持。
QwenLong-L1-32B基于强化学习(RL)技术进行了优化,通过先进的算法设计,顺利达成了从短上下文到长上下文的推理能力迁移。这种创新性的方法不仅有效提升了模型的性能,还为其在各类多样化场景中的应用筑牢了坚实的基础。
三、完整解决方案与开源生态:
阿里同步发布了覆盖模型开发全链路的工具集,包括:
专用训练数据集DocQA-RL-1.6K:包含1600个涵盖数学、逻辑及多跳推理的问题,支持模型精细化调优。
高效推理框架:通过稀疏注意力机制优化,处理100万Token的响应速度提升4.3倍,成本仅为GPT-4o-mini的1/3。
开源支持:模型代码及权重已在GitHub、Hugging Face和ModelScope平台开放,开发者可快速集成至现有系统。
行业影响与战略意义:
QwenLong-L1-32B的发布标志着中国在长文本AI领域的技术自主性突破,其开源策略进一步巩固了阿里云在“模型+算力+平台”生态中的领导地位。该模型不仅推动金融、法律等行业的数字化转型,更通过低成本高性能优势(如李飞飞团队基于Qwen系列仅用50美元复现顶尖推理模型),加速AI技术普惠化进程。未来,随着长文本推理成为AI系统核心能力标准,阿里有望在全球化AI竞赛中占据更关键席位。