
导读
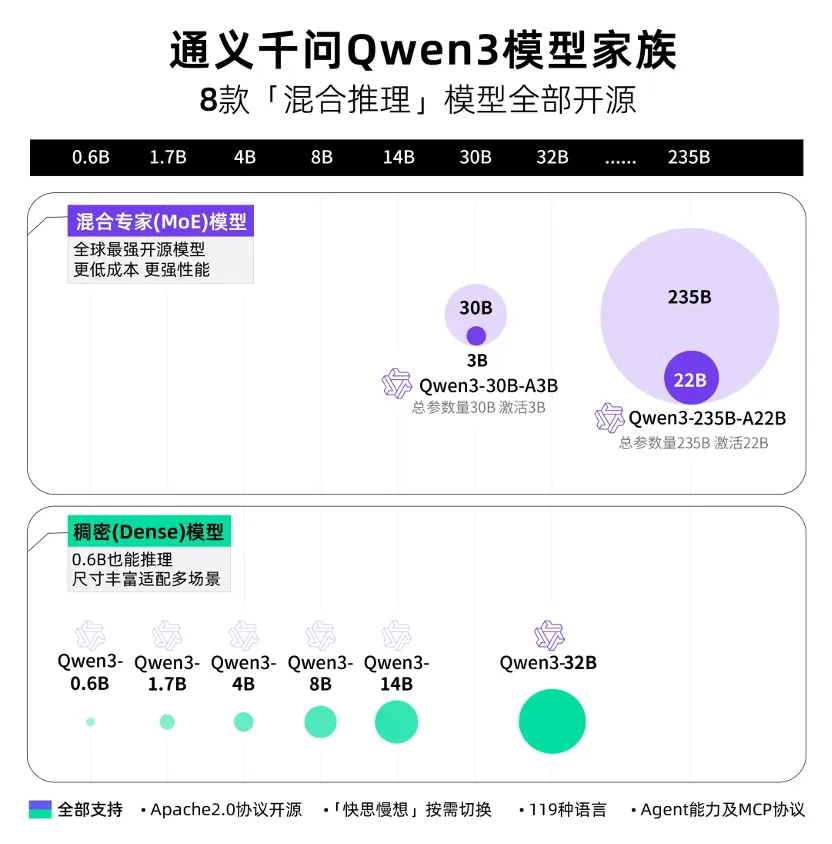
2025年4月29日,阿里云正式发布并开源通义千问Qwen3系列大型语言模型,这一举措在人工智能领域引发广泛关注。Qwen3作为Qwen系列的最新一代模型,提供了一系列密集型和混合专家(MoE)模型,涵盖8款“混合推理模型”,包括两款MoE模型(Qwen3-235B-A22B、Qwen3-30B-A3B)以及六个Dense模型(Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B、Qwen3-0.6B),参数规模从0.6B至235B不等,能满足多样化的应用需求。
文字编辑|李祥敬
1
Qwen3:性能卓越,功能多元
Qwen3在性能上表现卓越。其旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中,与DeepSeek-R1、o1、o3-mini、Grok-3和Gemini 2.5-Pro等顶级模型相比,展现出强大的竞争力。小型MoE模型Qwen3-30B-A3B激活参数数量仅为QwQ-32B的10%,却有着更优的表现;Qwen3-4B小模型也能达到与Qwen2.5-72B-Instruct相当的性能。该模型支持思考模式和非思考模式。思考模式下,模型运用逐步推理的方式,针对复杂问题,通过多层级的逻辑推导与知识调用,深入分析问题本质,从而给出精准答案。这种推理过程涉及对大量知识的检索、整合以及复杂的算法运算,以确保推理的准确性和深度。非思考模式则基于优化的快速响应算法,当接收到简单问题时,能够迅速定位相关知识并给出答案,满足对速度要求较高的场景。这种双模式设计,让用户可根据任务需求灵活控制模型推理方式,有效平衡计算资源与推理质量。Qwen3的多语言能力也十分突出,支持119种语言和方言。模型在语言处理过程中,采用了多语言融合的词向量表示方法,能够将不同语言的词汇映射到统一的语义空间中,使得模型可以理解和处理多种语言信息。同时,在训练数据的构建上,涵盖了丰富的多语言文本,包括新闻、学术文献、社交媒体内容等,通过大规模的多语言语料训练,提升了模型对不同语言的理解和生成能力,为其在全球范围内的应用拓展提供了有力支撑,有助于打破语言障碍,推动跨语言的人工智能应用发展。在训练方面,Qwen3的数据集相比Qwen2.5显著扩展,从18万亿个token提升到约36万亿个token,涵盖119种语言和方言。其预训练过程分三个阶段,第一阶段(S1),模型在超过30万亿个token上进行预训练,上下文长度设定为4K token,通过对大量通用文本的学习,模型构建起基础的语言理解和生成能力,掌握了常见的语言结构和语义表达。第二阶段(S2),增加知识密集型数据,如科学、技术、工程、数学(STEM)领域的文本、编程代码以及逻辑推理问题等,然后模型在额外的5万亿个token上进行训练,强化了模型在专业领域的知识储备和推理能力。最后阶段,使用高质量的长上下文数据将上下文长度扩展到32K token,这一过程通过改进的注意力机制,让模型能够有效处理更长的输入,捕捉文本中更长期的依赖关系,提升对复杂文本的理解和生成能力。后训练则采用四阶段训练流程,包括长思维链冷启动、长思维链强化学习、思维模式融合以及通用强化学习,以开发具备思考推理和快速响应能力的混合模型。
2
华为昇腾和昇思:实现0Day适配,构建完整生态
华为昇腾和昇思在Qwen3发布后迅速响应,实现0Day适配。昇腾MindSpeed训练和MindIE推理全面支持Qwen3系列模型,开发者可借助其提供的低代码解决方案,实现模型的快速迁移和应用。在MindSpeed训练方面,华为提供了详细的环境配置指导,涵盖硬件要求、仓库部署、权重转换、数据预处理和训练脚本等环节。以Atlas 800 A2系列单机8卡训练和推理为例,硬件层面,该系列具备强大的计算能力和高速的数据传输能力,为大规模模型训练提供了坚实基础。软件层面,从仓库拉取开始,开发者需依次完成MindSpeed-LLM和Megatron-LM仓库的克隆,并进行相应版本的切换和文件复制。环境搭建过程中,涉及Python虚拟环境的创建、torch和torch_npu等依赖库的安装,且需根据硬件架构和Python版本选择合适的安装包。例如,在安装torch和torch_npu时,针对不同的硬件平台(如x86或arm)和Python版本(如Python3.10),要选择对应的whl文件进行安装。此外,还需从原仓编译安装apex for Ascend,并安装MindSpeed加速库,以提升训练效率。权重转换环节,MindSpeed-LLM提供脚本将huggingface开源权重转换为mcore权重,这一过程涉及对权重数据的格式转换和优化,以适应昇腾硬件的计算特性。数据预处理阶段,提供脚本对数据集进行处理,开发者可根据实际需求修改参数,实现对训练数据的清洗、标注和格式化,确保数据质量和格式符合训练要求。训练脚本则基于分布式并行接口,支持多卡训练,通过优化的通信算法和任务调度策略,充分利用多卡的计算资源,加速模型训练过程。MindIE推理同样提供了完善的支持。针对纯模型推理和服务化推理场景,分别制定了相应的测试和部署方案。开发者通过修改模型文件夹权限、加载镜像、启动容器等操作,即可完成推理部署。昇思MindSpore原生支持Qwen系列大模型,通过JIT(Just-In-Time)加速提升推理系统吞吐率。JIT编译会自动将模型的Python类或者函数,编译成一张完整的计算图,在编译过程中,通过自动模式匹配,在整图范围内将多种小算子组合,融合成单个大颗粒的算子,减少算子调度开销。同时,构建了Shape推导、Tiling数据计算、下发执行的三级流水线,实现Host计算和Device计算的掩盖,有效提升了计算图动态Shape执行效率。此外,昇思MindSpore开发vLLM-MindSpore插件无缝接入vLLM生态,该插件采用MSAdapter将vLLM服务组件依赖的PyTorch接口映射至MindSpore能力,无缝继承了Continuous Batching等核心特性,进一步优化推理性能。
3
英特尔:深度优化,拓展应用场景
英特尔与阿里紧密合作,针对Qwen3系列大模型开展深度优化工作。针对MoE模型部署难题,英特尔采用多种软件优化策略,借助OpenVINO工具套件,成功将Qwen模型高效部署于英特尔硬件平台。例如,在ARL-H 64G内存系统上部署30B参数规模MoE模型,实现了33.97 token/s的吞吐量,相比同等参数规模的稠密模型性能显著提升。在优化过程中,英特尔针对稀疏混合专家模型架构(Sparse MoE)进行算子融合,将多个相关的算子合并为一个计算单元,减少数据在不同算子之间的传输开销,提高计算效率。针对3B激活MOE模型定制化调度和访存优化,通过优化任务调度算法,合理分配计算资源,减少计算资源的空闲时间;同时,优化访存策略,提高数据访问速度,降低内存访问延迟。此外,还针对不同专家之间的负载均衡进行优化,确保各个专家计算资源的合理利用,避免出现某些专家负载过高,而其他专家资源闲置的情况。英特尔首次在NPU上对模型发布提供Day 0支持,针对不同模型参数量和应用场景,提供多样化、针对性的平台支持。在酷睿Ultra的iGPU平台、英特尔锐炫A系列和B系列显卡上,Qwen3模型均能取得良好的性能表现,开发者可根据实际需求选择合适的硬件平台进行模型部署。英特尔还通过端侧微调提升模型智能,基于Unsloth和Hugging Face参数高效微调框架构建端侧解决方案,优化用户体验。端侧微调过程中,利用特定的数据集对小型LLM(如0.6B参数量模型)进行优化,通过反向传播算法调整模型的部分参数,使得模型在特定任务上的表现更加出色。此外,英特尔拥抱开源生态,优化版Ollama第一时间支持Qwen3系列模型,方便开发者在英特尔客户端平台搭建智能应用。
4
海光:无缝适配,展现技术优势
在“深算智能”战略引领下,海光DCU快速完成对Qwen3全部8款模型的无缝适配与调优,覆盖从235B到0.6B的不同参数规模模型,实现零报错、零兼容性问题的秒级部署。基于GPGPU架构的生态优势和编程开发软件栈DTK的领先特性,Qwen3在海光DCU上展现出卓越的推理性能与稳定性。这不仅验证了海光DCU的高通用性和高生态兼容度,也凸显了其自主可控的技术优势,为AI大模型的训练与推理提供了坚实可靠的基础设施支持。DCU在Qwen3适配中展现了卓越的技术能力。其采用通用图形处理单元(GPGPU)架构,支持高并行计算,适合AI模型训练与推理,类CUDA并行计算框架兼容主流AI软件生态,确保与Qwen3等模型的无缝整合。海光的深算工具包(DTK)是一套完整的软件开发套件,包括开发工具、库和优化框架,支持模型迁移、性能优化与快速部署,助力DCU实现Qwen3全系列模型的秒级部署,无任何错误或兼容性问题。DCU支持从0.6亿到2350亿参数的Qwen3模型,展现了其适应多样化计算需求的灵活性,覆盖边缘计算到数据中心的高性能场景。其兼容全球AI框架及国产大模型,降低开发者迁移成本,同时内置安全硬件,支持国密算法(如SM2、SM3)与可信计算,满足中国对信息安全与技术自主的高要求。DCU通过支持Qwen3的训练与推理,确立了其作为AI大模型关键基础设施的地位。相较于进口GPU,DCU提供自主可控的算力解决方案,满足金融、政务等行业对安全与效率的需求。
结语
Qwen3的发布与开源为人工智能领域带来新的发展契机,而华为昇腾和昇思、英特尔等芯片厂商的支持,从训练到推理,从性能优化到生态建设,为Qwen3的广泛应用提供了全方位保障。随着技术的持续创新,各方的协同合作有望推动人工智能技术迈向新的高度,在更多领域实现创新应用,为行业发展注入新动力。
本文来源于DOIT传媒,文章内容仅供参考,不构成投资建议。


评论列表