如今,越来越多的现代化企业都越来越关心数据。
因为,依靠从数据中获得的洞察,可以提高决策效率和准确性,优化资源分配和成本控制,促进创新和业务增长,帮助企业获得更长远的发展。然而,随着数据量的快速增长和业务复杂性的提升,企业在数智化运营面临的挑战越来越多。
为了帮助企业应对这些挑战,曾参与并推动了阿里巴巴及蚂蚁集团数据技术的演进和发展的专家,与合作伙伴共同成立了一家叫Aloudata的公司,他就是Aloudata CEO周卫林。
在蚂蚁集团就职期间,周卫林担任了数据平台总经理和企业信用事业部总经理,是蚂蚁集团数据技术的主要奠基人之一,他从零开始建立了蚂蚁的数据平台体系。
周卫林的这些经历,使得他成了国内少数非常懂得如何将数据用于业务发展的专家。
数智化运营面临的“用数”挑战
周卫林将企业内部数据需求总结为“数字化管理”和“数智化运营”两部分,数字化管理属于“看数需求”,而数智化运营属于“用数需求”。

比如,当管理层设定一个年累计销售目标,会不停的看各种数据,这就叫“数字化管理”,涉及的各种指标可以叫做管理指标。管理指标需要在执行层面拆分,执行层面会用数据做很多分析工作,制定与执行运营动作,发现运营中的问题后会随时做出调整,这叫“数智化运营”。
相比之下,数字化管理关注于企业高层的战略性决策,需求相对固定,并且“看数”周期比较长又相对固定。而数智化运营关注于具体的业务操作和日常决策,需要很多团队和员工从事相关的动作,不仅需求多变,而且对实时性要求比较高。
从背后的技术实现来看,管理层“看数”用的报表就是从数据中提取信息并制作汇总表,这个过程相对简单。而数智化运营在“用数”时则非常复杂,随着业务灵活性、复杂性的提高,需要数据技术层面做的工作越来越多,会带来非常多的挑战,这些挑战集中体现在ETL工程方面。
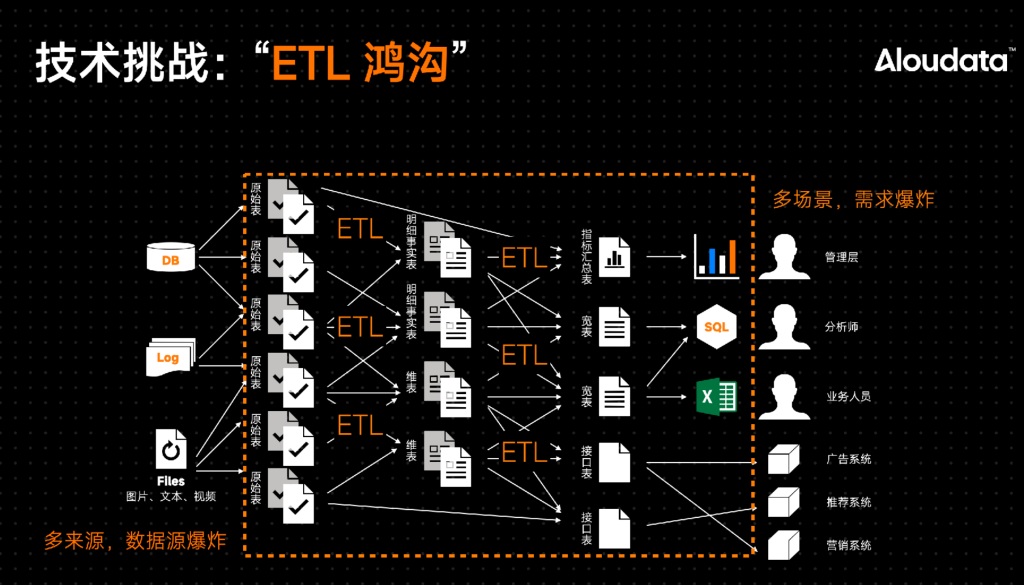
比如,它会产生很多新的数据链路,会需要引入很多新的数据源,需要大量的ETL操作,需要进行大量的数据搬运和处理。还需要存储和计算大量数据,这会带来更高的成本。
同时,每一条链路就是一次作业,每一次作业都必须经历排期、研发、测试、上线发布等繁琐的步骤,想要用数据就经常需要漫长的等待时间,导致很多数据无法被及时利用,对于业务端很不友好。
数据链路的末端对应着一项项需求,每一项需求都要有一个高性能数据集,才能满足不同的查询性能需求。然而,每创建一个高性能数据集,都需要额外的成本。为此,企业不得不预先计算并提供大量可能会被使用的数据,这又会增加成本,降低了边际收益。
同时,多变的需求还让人工维护数据目录的方式变得无以为继,因为ETL工程师数量和能力的提升速度远远赶不上数据需求量和需求复杂度的增速。此时,不得不面对失真的数据目录和失效的数据管理。
如何应对“用数”带来的ETL挑战
为应对这些挑战,Aloudata提出了创新的“NoETL”模式。这种模式是要寻找一种不再依赖于传统ETL工程师人力驱动的方法,通过技术手段降低传统ETL的复杂性和成本。
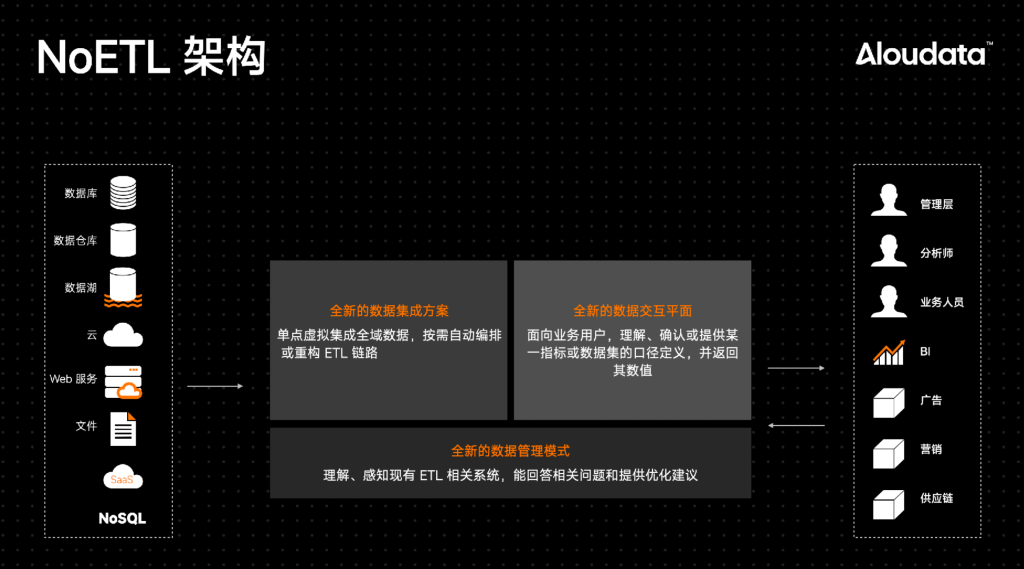
Aloudata提出的NoETL架构包含三部分,分别是全新的数据集成方案,全新的数据管理模式,以及全新的数据交互平面。
其中,全新的数据集成方案会构建数据虚拟化引擎,区别于传统的数据集成方式,它是用逻辑方式进行数据集成和ETL链路的自动重构。这就好比电商平台先下单,商家再发货的模式,而非“先补货再销售”的模式,在这种模式下才能提高数据集成与编排的效率。
全新的数据交互平面是为了方便“用数”的人,它指的是,构建一个数据语义引擎,帮助用户清楚地知道所需要的指标是什么,知道指标的口径和指标的值,不用关心表格的具体存放位置就能拿到需要的数据。同时,指标由用户通过语义模型进行定义,定义后由系统进行自动生产,改变了过去“业务提需求、IT开发宽表与汇总表”的生产模式,大幅提升指标的生产效率,降低IT的工作压力。
全新的数据管理模式指的是构建一套能够感知当前系统状态的元数据系统,进行由主动元数据驱动的管理。主动元数据不同于被动元数据,它类似于实时导航系统,不仅提供精确定位,还能辅助驾驶。
这套架构的具体实现可以分为这几个关键步骤:

第一步,在逻辑上与数据源建立联系,它可以减少甚至避免数据搬运的操作。即使不知道数据在哪儿,即使不知道数据的格式,一旦发现数据,就能立即将数据进行集成。
第二步,系统会自动构建全局数据的逻辑视图。这一步使用了AI增强的自适应加速技术,以替代传统的人工方式建立ETL(抽取、转换、加载)链路,提高数据处理的效率和速度,减轻了认为运维操作的负担。
第三步,进行语义建模。在这一步骤中,IT部门首先定义原子指标,然后业务人员利用数据语义来定义所需的各种指标。这个过程本质上是一个开发过程,省去了向IT部门提交需求的步骤,使得业务部门能够更快速、直接地获取他们需要的数据。
第四步,通过开放服务来满足各种系统和消费场景的需求,包括与BI(商业智能)和AI(人工智能)工具的对接,增加系统的灵活性和适用性,实现数据的普惠化。
最后一步,实现一个能够实时感知全局信息的主动元数据系统。这个系统使得可以进行ETL Copilot和其他优化辅助工作,提高数据治理的效率和质量。
Aloudata的对应的方案

为了帮助企业落地NoETL,Aloudata推出了三个核心产品,分别是:逻辑数据平台Aloudata AIR,自动化指标平台Aloudata CAN,还有主动元数据平台Aloudata BIG,对应上文提到的NoETL架构的三大组成部分。
从周卫林的介绍中了解到,Aloudata AIR是国内首个基于Data Fabric架构的逻辑数据平台。它解决了数据需要搬运的问题,它实现了多源异构数据的虚拟化集成,它可以自动优化链路,支持自适应的查询加速,能提高处理效率。

首创证券在采用Aloudata AIR后,实现了数据的逻辑集成、自动化ETL流程和统一的数据服务,大大降低了投入到ETL方面的数据工程人力和成本投入。对于首创证券提高效率、节约成本,有很大帮助。
Aloudata BIG是一个拥有算子级血缘解析能力的主动元数据平台。所谓“算子级血缘解析能力”是指在数据管理和分析中,能够非常精确地理解数据从源头到最终形态的每一步变化的能力,包括理解数据是如何被筛选、合并、转换和汇总的。
这种能力能实现很多自动化的操作,包括自动维护数据血缘地图来构建完整的数据图谱。也包括将代码自动翻译成业务语言,将SQL语句转化成容易理解的自然语言,过程都无需人工干预。
Aloudata CAN是一个用于指标管理和开发的自动化平台。与传统的指标平台不同,它允许用户直接在平台上定义所需的业务指标。一旦用户定义了指标,系统会自动进行后续的指标开发和加速,无需人工干预。
Aloudata CAN的实现采用了定义即生产、定义即服务的模式,极大地简化了ETL工作量。通过技术自动化,它改变了传统的指标生产模式,降低了IT部门的参与度,使IT团队能够专注于更有价值的任务。
Aloudata NoETL模式的落地与应用
从周卫林的介绍中了解到,Aloudata的NoETL模式可以充分利用企业现有的数据湖、数据仓库和其他数据源,盘活全部数据资产,实现平滑升级,而不是完全重构。这种做法更容易让企业接受。

招商银行作为国内大型商业银行,使用了Aloudata的AIR, BIG 和 CAN三个产品。周卫林表示,与招商银行的合作由来已久,双方为了解决招商银行所经历的特定问题做了很多,而这些问题恰好是此前在蚂蚁集团所经历过的,两者需要在巨大的数据规模上运营和管理数据。
目前,Aloudata所提供的解决方案得到了许多大型头部企业的强烈响应,特别是在金融行业、股份制银行、头部城商行和大型国央企中。而且,一些客户案例和解决方案逐渐形成了一种范式效应,在周卫林看来,这都能证明NoETL模式的方法是最有效的。
简而言之,NoETL模式要做的就是提高企业利用数据的能力,比如,帮助一些大企业更快利用自己的数据,提高利用每天新产生数据的比例,提高每月新产生数据的使用比例。最终,真正让数据为企业所用,为企业创造价值。