
全面上云是怎么一回事?
现在是互联网时代,云服务改变了我们的生活,也改变了整个IT行业。到底什么是云服务呢?我们简单打一个比方:
村子里有100户人家,每家都要盖自己的房子。如果每一家都亲自去准备木材和砖瓦,亲自打地基、搭梁木、砌墙铺瓦,这就相当于传统的自主研发;如果大家都去请村里专业的木匠、砖瓦匠、油漆匠,指挥工匠完成各种基础工作,这就相当于利用了云服务的资源。
云服务在国内发展十分迅速,近些年来涌现出很多优秀的云服务平台,腾讯云就是其中之一。
尽管腾讯云在国内有大量客户在使用,但是腾讯内部却面临着一些历史遗留问题:腾讯各个业务线在当初开发的时候往往都是自己造轮子,依赖着五花八门的底层框架和接口。时间久了,一是导致技术与主流技术体系脱节,二是也会影响开发效率。
为了解决这个问题,腾讯内部在2018年启动了自研上云战略,直至最近,腾讯宣布内部海量自研业务已实现全量上云,这也是国内最大的云原生实践。
从一个一线码农来说,为什么要上云?上云是公司的“政治任务”还是程序员真正的心之所向?腾讯光子欢乐游戏工作室的技术总监马同星向我们分享了他和团队的“上云”故事。
“原来的架构好好的,为什么要上云?”
作为休闲游戏的国民级代表,“欢乐斗地主”用户体量庞大:2019年日活用户数千万,同时在线玩家数超百万,直到今天仍保有千万级别的日活。
懂业务的人知道,这么一个常青树级别的业务,背后一定有着稳定的技术架构和成熟的运营在支撑。
那么问题来了:之前这套架构运作得好好的,为什么要上云呢?
马同星给的回答很简短,“因为云就在那里。”在他看来,“云”是行业必然,更是大势所趋,云让所有的技术从业者都不能视而不见。
如果用一些关键词来描述马同星,大致可以用这些来概括:技术大佬、健谈、学习能力超强、乐意分享、拥抱开源……作为腾讯光子欢乐游戏的技术总监,欢乐系列游戏上云也正是由他发起并主导推动的项目。
值得一提的是,早在2019年初,马同星便做出了决定:基于开源方案,对欢乐游戏原有的技术架构进行重构,并将整体业务迁移上云。
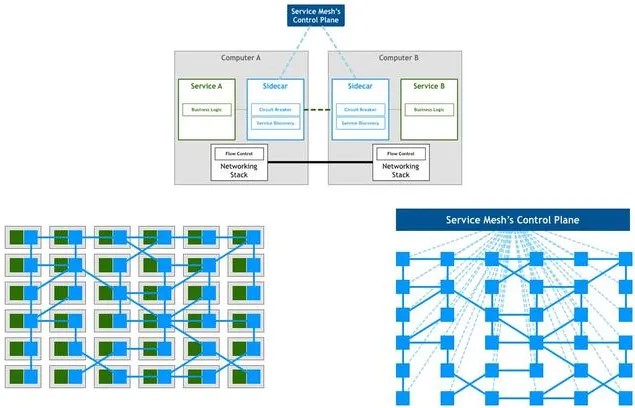
不用公司现成的那些服务去改造,而是自研服务,推动他做出这个决定的,是当时社区日益收到关注开源服务网格(service mesh)——Istio 1.1版本推出。要从成熟的架构一下子切到这种开源没多久、没有经过大规模落地的方案,团队里不少同学都是没底的。“风险太大了”、“掌控不了”、“业务的压力太大”,类似的担忧不绝于耳。
但马同星不这么认为,他觉得一定要做“难而正确的事情”。马同星下面讲述的这个“上云”故事,希望能给大家一些启发:
“如果我们不做,三年后就会差的很远”
事实上,在上云前的两三年我们就在讨论重构这个事儿了。
大概2018年下半年,我们开始做服务发现、流量治理的一些预研,调研社区的各种方案并因此关注到Istio。到19年初,也就是春节前2月份的时候,我们开始做技术验证。当时刚发布的Istio 1.1,是它的第一个Enterprise Ready版本,业界还鲜有大规模应用,腾讯内部也还没有这样的服务。
我们团队一起看一些技术资料,就开始研究这个。一开始我以为,微服务架构和服务网格的治理,是“新瓶装旧酒”——我以为进程多、把每个功能变小就是微服务,后来发现真不是,它这里说的微服务治理是指系统调度治理的能力细致入微。
如何理解这个治理能力呢?我举个例子,你有100个服务在做不同的事,这时A服务要访问其中的30个,B服务又访问其他的20个,C服务访问其他的15个,这15个里面的某个又要访问A服务…你把它想象成100个人的合作就知道——交互是星罗棋布的,牵一发动全身。
而真正的微服务治理能力,不管你的服务划分多细、结构多复杂,这些服务调度、容灾容错扩缩的细节都不需要额外关注了。它的治理难度不会随着你的系统变庞大而变复杂,不需要付出显著的额外成本。
总之,它是把服务和治理能力重构、下沉到基础设施层、避免侵入业务架构去做流量治理和调度的方案。在我看来这个设计思路的先进性超过以往传统分布式架构非常多。
这个开源方案所代表的微服务治理架构,就是我说的要做的“正确的事情”。
我们初期主要目标其实并不是为了省成本,大家上云一开始就是奔着提高流量治理能力的目标去的。
我们从大的技术趋势和机会一点点推演,当时想要实现某些业务模块的自动服务发现,其实也有其他低成本的方式可以做,但如果对照这个服务网格乃至云原生整个社区的技术架构能力,那就差很远了。
比如,大扇出系统出一个故障,以前你得通过分析日志来看哪个环节出了问题,但对于云原生来讲,整个调用链路非常清楚,自动生成调用链路拓扑给你,很快就能看到出问题的根源节点,对整个研运效能都是质的提升。
我个人觉得这一定是大的方向,甚至是对云业务利润率的提升是很重要的。这些能力都是行业大的机会和趋势,如果我们不做,现在也可以运营的很好,但三年以后,你可能就差很远。
“对技术的掌控和认知,是消除恐惧和担忧的有力武器”
在启动这件事情的时候,团队里不少同事是犹豫的。
我们工作室的负责人非常重视并不遗余力的投入技术创新,工作室专门设有公共技术团队负责技术预研类的工作,同时还有各个业务项目组内的技术团队,如果要去做这样一个大的架构调整,除了老板的支持还需要所有核心骨干发自内心愿意去做这件事情,才能走得下去。在项目组的同学,他会更多地去考虑项目迭代以及对版本稳定性的要求,会下意识焦虑:一下子切到我经验之外的一个技术方案,会不会出很多问题,在原有架构下小步快跑是不是也挺好?
当时其实花了很多时间和各个项目组的技术骨干们谈心:为什么要基于开源来做,做这个对团队和个人的发展有什么好处,技术架构调整的风险和挑战如何由组织而不是个人承受。
有一些同事是很热衷技术的,给的响应比较积极。另一些倾向于保障业务优先的同事还是会犹豫,我就接着提议说,我们用小体量项目先来试点,就这样把团队的信心初步聚拢了起来。
第二件事就是统一团队的目标。当时我们团队做了很多轮分享和研究,甚至翻译了一本K8S的书,最终统一了目标:基于开源的一整套开源的技术栈来重构,包括从最底层的协议,到开源远程过程调用系统GRPC,到服务网格以及K8S的服务编排。原因也十分简单:这套东西已经逐渐成为了行业的事实标准,不去跟上它,我们就会慢慢落伍,想自己搞一套打过人家已然是不可能的了。
大概到2019年6月份,试点项目验证的结果评估出来了:方案可行。这个时候团队的气氛与最开始时已经完全不一样了,变得信心满满了,因为我们已经把这个技术吃透了。对技术的掌控和认知,是消除恐惧和担忧的最有力的一个武器。等到了后面大规模上云重构的时候,大家已经驾轻就熟了。
五十万人游乐场的“乾坤大挪移”
技术验证这是第一个节点,到了第二个节点,我们要做的就是把业务平滑地过渡到云原生环境。
但这个上云不是说把我们的服务搬到自研云就叫上云,假设我们只是把IDC的生产环境搬到腾讯云的自研云里面,却还是用原来的架构,在我看来它的意义就大打折扣了。
公司大力推动自研上云营造了一个非常好的技术变革的氛围,而且到了2019年6月左右,TKE团队也开始做mesh了,还跟我们专门成立了联合的保障团队。在这个基础上,我们开始把原有的业务逐个地重构,放到云原生的环境里面去。
重构的技术难度没那么高,但服务平滑迁移是个问题。我们当时一部分业务在云原生架构上,另一部分则在云下。在这种异构架构下,要保证迁移过程平滑、用户无感知,对于业务来说是一件很有挑战的事。
因为游戏和普通互联网服务不一样,比方说你买个东西,失败了大不了重试一次,但游戏是实时交互的,掉线再回来游戏过程已经到新的局面了,其它玩家不会陪你重来错失的游戏过程。这就好比说,你要把几十万人从一个游乐场乾坤大挪移到另一个地方,还不能让他们有感知一样。
其实在上云过程中,业务端也是有疑惑声音的。2021年春节的时候,我们与手机QQ合作了一个运营活动,当时瞬间涌进来大量的用户,于是出现了过载,也就是大量用户排队的情况。
当时运营的同学没有把这个活动提前告知研发团队,我们那时有一部分业务还在云下,还没有动态弹性计算的能力,所以出了这个故障。后面我们跟运营同学一起来总结这个事情的原因,他们不太理解,说我们的系统不是能支持一两百万在线吗,怎么来了五十万人就不行了呢?
我当时就给他们举例子解释说:某办公楼能支持五千人办公,但每天早上电梯排队非常长,咱们的情况和这个同理。一个是容量,一个是登入并发负载,容量可以很大,但不代表咱们短时间的处理能力很强。目前这部分业务没有动态弹性计算的能力,所以会这样。我们现在正在做一个大的技术重构叫云原生重构,它最核心的能力之一就是解决这个问题:如果只有一个人走,这个电梯就会变得很小,节省资源;如果突然来了五万人,它会自动变得很宽,让那五万个人很快地过去。
讲了这个运营同学们就明白了,在后续的协作就方便了很多。所以这个事之后我总结说,技术管理者要去给到团队三个信心:
第一,有充分的基础验证,证明方向靠谱;
第二,重大重构必然充满技术风险,既然选择去做,对团队要有兜底承诺,做为技术管理者就要首先承担风险责任。出了问题不盲目责怪团队,因为啥也不干风险最低;
第三,以非技术人士能够理解的方式,把技术的影响力扩大至协作上下游的其他团队,获取他人的信任与支持,来推进技术建设。
记得2020年11月17日上午11时我们第一次跨集群网格全量在线升级,升级后部分跨集群的路由信息丢失,导致一个重要游戏功能的大量失败。研发同学全力投入故障业务恢复,项目组的策划、运营同学出公告、用户补偿方案,联系客服安抚玩家。大家都在无条件支持,没有人抱怨。研发同学恢复服务并完成玩家数据补偿后,与TKE团队一起彻查了问题根源。终于下午17:44,后台同学在项目组大群周知服务已经恢复并已经重新上架客户端功能入口,不但没有任何责怪和质疑。我们GM反而关心大家,“好多后台同学忙着处理问题,到现在午饭都还没吃上,辛苦了。” 工作室对技术创新的期望、宽容和耐心是大前提,稳健运营的项目是重构演进得以落地的场景,更难能可贵的是不同专业背景欢乐的小伙伴们的通力协作支持,这些都是欢乐云原生重构能顺利落地的重要保障。
早在2020年的6月,欢乐所有的游戏对局服务就已经全部部署到了云原生环境下,复杂且强状态实时交互的游戏对局服务也首次具备了弹性计算能力。据我们了解,这应该是在游戏领域里第一家做到这个水平的团队。
更高的目标:从峰值60% 到全时70%
事实上,我们这三个阶段,包括技术验证,包括去做核心服务的迁移,再到最后做存量服务的迁移,我们都有一个大的原则:不赶时间,不拼核时数,只看一个东西:云原生的弹性计算能力是否有充分发挥,这个评判标准是忙时至少能到60%的负载。
其实任何一个游戏产品都有生命周期,在云下的时候,大家都是猛堆机器,去完成高峰期的承载,但过了高峰期,那些机器的实际利用率是非常低的。我们做过测算,许多项目在没有弹性计算的架构下,高峰期有效负载只有30%不到,低峰期负载率更低。
如果你的业务上了云,利用率和在云下是一样的,我觉得是一个非常差的成绩。我们不能把上云当作公司下派的被动任务一样完成,只完成基础的上云量指标是远远不够的。
所以我们强调,不要去拼上云的速度和核的数量,而是拼上云的质量,我们一定要按照云原生的能力重构业务系统,上去了它就有真正的弹性计算,服务调度、流量治理这样能力。
等老业务也完成重构上云、异构系统裁撤掉后,我相信整体的资源利用率会再上一个大台阶。我的期望是未来能做到全时70%+,不仅仅高峰期70%利用率,而是低峰期也能做到70%,消峰填谷,把空闲计算资源用于离线计算业务,这是一个长期的目标。
如果真正做到的话,我们用到的核时数可能会降到现在的1/3甚至更低,当然,这不是一个容易的事情。
有个事我也特别感动:去年夏天我们项目组组织了一次去江西武功山的团建,花了几个小时徒步爬上去,最后人真的是站在那个云上面,云就在脚下五六十米、一百米的地方,大家非常激动,开始拍照片发朋友圈。
“我们这才是真‘上云’的团队。”许多人发朋友圈这么写,这个时候我知道,我们这件“正确的事情”是真的做对了。

人们常说,船大难掉头,以腾讯公司庞大的体量,自研上云的困难不言而喻。但是,正如上面所讲述的故事,在腾讯公司有许许多多像马同星一样的人,靠着自己的技术经验和想法勇敢尝试,最终完成了一个个不可能完成的任务,使得腾讯内部诸多的老项目在云端焕发青春。
IT人大部分时间从事着琐碎的业务工作,能赶上这样一个转型云原生的浩大工程,既是挑战也是机会。当他们通过不断学习和尝试,通力合作克服各种困难,最终完成上云的那一刻,相信每一个参与者的个人能力都会得到巨大的提升。
这就是腾讯的技术人,这就是腾讯的精神,希望腾讯云能够在这样一群可爱的技术人的支持之下,越走越远,越飞越高。






