
 先智数据中国区总经理董唯元
先智数据中国区总经理董唯元
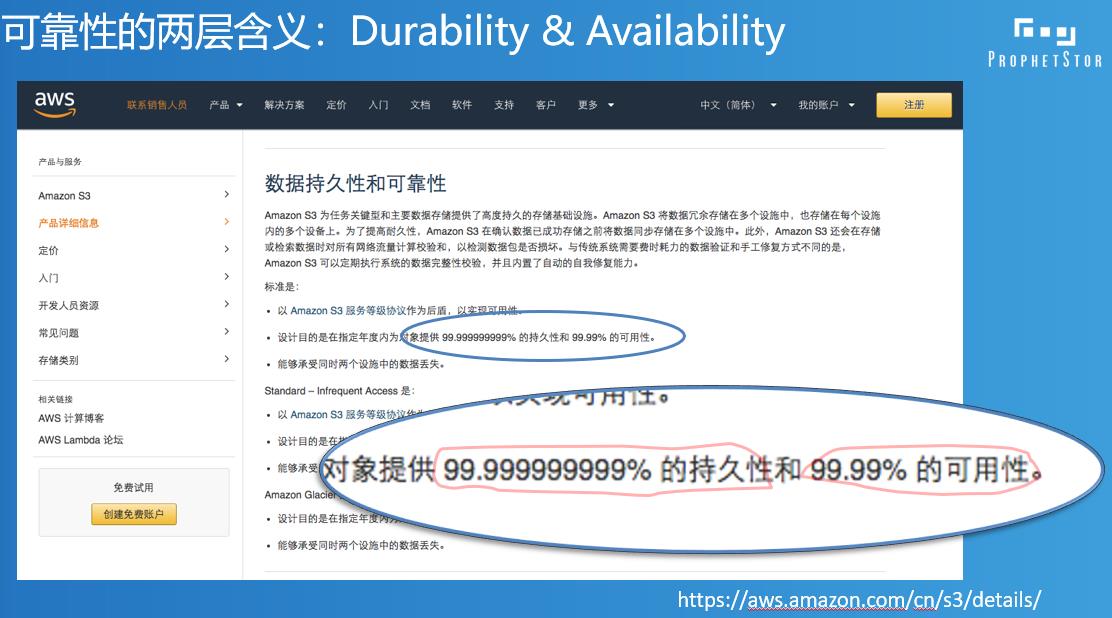 可靠性也是一个非常大的话题,我们从哪儿开始说呢,就从最基本的概念来说。其实可靠性这个词本身就是一个有一点模糊的地方,如果大家不做细的区分的话,就会发现两个人在讨论可靠性,说的半天发现说的不是同一件事,其实我们计算机里面有好多这样的东西好多概念不说细了,你都发现不了这里面的差别。我们就说数据存储,落到设备上面,不管是分布式存储还是传统存储,落到设备上面,它的可靠性到底是什么,到底是数据不丢是算可靠,还是说数据一直都可以访问,这两个就不是同一个概念,当然还有其他的部分。所以你会看到像AWS我们去申请它的云存储的时候,S3提供这样的一个说明页面,你会发现原来存储可靠性有两块,一块是叫持久性,一块叫可用性,还是用的可用性这个词,Availability,业界有不同的用法,AWS用的是这个可用性,至少持续性和可用性我们在AWS网站上看到是不一样的东西。因为指标不一样,这么多的9,11个9,可用性才4个9,持续性11个9,我们知道是不同的东西。
具体是什么,简单来说,系统正常工作是在线,这个系统有一个设备坏了但是数据都还能在线,不耽误用,比如说做了什么副本都是这样的,有东西坏了不耽误用,只是容灾率低,如果你有这个能力你的可用性是OK的。比如说超过这个,比如说这里面盘坏了,或者没有做副本数据不可访问了离线了,这个可用性就不在了。但是如果你有备份,你可以通过备份离线把数据找回来,至少可用性是在的,只要数据还有办法找回来,虽然不保证持续在线,但只要保证数据在线,这个持久性还在。我们做运维经常说,死了,数据丢了找不回来。像我做存储做了近20年,见过各种各样的“死人”的场景,我说最小的就是一个,大概早先年前磁盘战略,投影设备很小,里面8G的磁盘坏了,数据也不大,但是那堆数据刚好是工作小组大概70人用了将近一年的时间做的各种各样辛苦工作的结果,70个人满满一屋子做各种各样的分析、统计、计算,所有的结论、过程、结果都在这个小阵列上面,到年头的时候设备坏了数据读不出来了。在我们做存储的人看来这么一个小设备一两块盘坏了不是什么大事,当时没什么钱买,对做数据的人来说真是坏了,辛辛苦苦干了一年的活没了,再做一遍再用一年,这个成本打了。所以发生这种事的时候用户都是一脑袋汗。
还有更接近要命的,更接近物理的“要命”,就是股票,其实这些数据也不大,股票交易厅,交易系统还没有做双机,在1997、1998年的时候,很多没做双机系统一宕机,很快,能砸屏的都砸碎了。我那会儿其实还在大学念书,兼职给人装个双机干点私活,挣点外快,直接出来就是缠着绷带胳膊吊着这么出来,就是股民打的,交易系统交易不了你就想吧。丢数据对用户来讲是很要命的事。
最早只要数据不丢,能找得回来,稍微停一会儿还可以理解,但是有一些业务,渐渐像股票这种业务停都不准停,停就坏事了,你让我稍微卡顿一点都会是事故,有问题,其实对双机系统要求越来越高了。
我们今天至少在讨论可靠性这个概念的时候,大家说的更多的还是更基本,不丢,在线性,不掉线,这两个层面的东西是相对基本的。其实从可靠性来讲还有更高的,比如说变慢算不算是一种可靠性的损伤,业务角度来讲一定是,甚至业务系统变慢比彻底断了还可怕,因为变慢你不知道是哪儿的问题,一个东西坏了其实到你这儿到发现找到问题在哪儿,用的时间还短一点,因为容易找,找到哪儿坏了,该通的通了。如果一个比较复杂的业务系统某一个地方变慢了,找出问题到底在哪儿,真的有的时候花一两个月找不出来,因为这个系统太复杂了,但是变慢也是一个系统可靠性的影响。
今天我们所说的可靠性涵盖的更多还是持久性和可用性这两个更顶级的层面,AWS里面讨论的,我们看到很多业界的说法里面没有放到可靠性这个范围里面来,我相信未来可能会有比较可量化的整体的系统可靠性的评估方式、评估方法论,会把SLO,甚至更高层系统配备变更能力,其实这些东西都是对基础架构可靠性的要求。我刚才说起来就有四个层面,可能会有若干层面的这种对可靠性更细的拆解在基础架构的要求里面。这更多是方法论层面的事,今天不讲太多方法论层面的事,稍微介绍一点具体的东西。具体的东西大家看得见摸得着。
数据中心里面什么最容易出现故障,如果各位有做过运维或者在机房里面做过IT的管理者,就会有一个感觉,你的数据中心三样东西常年坏,硬盘、风扇、电源,CPU、内存、主板、机箱盖都不坏,就是这三样东西特别容易坏。而这三样东西里面风扇、电源坏了相对来说没有那么可怕,硬盘是最可怕的,因为数据直接在上面,数据整个系统的可靠性、可用性等等,最直接的就是跟硬盘有关系,所以别的不看,就是硬盘的故障是整个系统可靠性最可行的地方。硬盘我们都知道又不是一个平行的分布,也就是这个系统里面硬盘不是随时都有的概率的磁盘故障存在,如果实施过IT系统的会由直观的感觉,一个新东西上来头三个月是最麻烦的,新布一个系统一会儿这儿怀了,那儿有故障了,如果把故障全都解决了3个月没有什么事,6个月没有什么事基本上可以放心使用,一年两年没有问题,中间故障率是越低,等到到快到寿命的时候,四年、五年看你附载的轻重,如果轻就是长寿一点,重就短寿一点。今天有点问题,你就会知道在接下来两年陆陆续续都会有问题,就是这个设备的寿命差不多到了。
可靠性也是一个非常大的话题,我们从哪儿开始说呢,就从最基本的概念来说。其实可靠性这个词本身就是一个有一点模糊的地方,如果大家不做细的区分的话,就会发现两个人在讨论可靠性,说的半天发现说的不是同一件事,其实我们计算机里面有好多这样的东西好多概念不说细了,你都发现不了这里面的差别。我们就说数据存储,落到设备上面,不管是分布式存储还是传统存储,落到设备上面,它的可靠性到底是什么,到底是数据不丢是算可靠,还是说数据一直都可以访问,这两个就不是同一个概念,当然还有其他的部分。所以你会看到像AWS我们去申请它的云存储的时候,S3提供这样的一个说明页面,你会发现原来存储可靠性有两块,一块是叫持久性,一块叫可用性,还是用的可用性这个词,Availability,业界有不同的用法,AWS用的是这个可用性,至少持续性和可用性我们在AWS网站上看到是不一样的东西。因为指标不一样,这么多的9,11个9,可用性才4个9,持续性11个9,我们知道是不同的东西。
具体是什么,简单来说,系统正常工作是在线,这个系统有一个设备坏了但是数据都还能在线,不耽误用,比如说做了什么副本都是这样的,有东西坏了不耽误用,只是容灾率低,如果你有这个能力你的可用性是OK的。比如说超过这个,比如说这里面盘坏了,或者没有做副本数据不可访问了离线了,这个可用性就不在了。但是如果你有备份,你可以通过备份离线把数据找回来,至少可用性是在的,只要数据还有办法找回来,虽然不保证持续在线,但只要保证数据在线,这个持久性还在。我们做运维经常说,死了,数据丢了找不回来。像我做存储做了近20年,见过各种各样的“死人”的场景,我说最小的就是一个,大概早先年前磁盘战略,投影设备很小,里面8G的磁盘坏了,数据也不大,但是那堆数据刚好是工作小组大概70人用了将近一年的时间做的各种各样辛苦工作的结果,70个人满满一屋子做各种各样的分析、统计、计算,所有的结论、过程、结果都在这个小阵列上面,到年头的时候设备坏了数据读不出来了。在我们做存储的人看来这么一个小设备一两块盘坏了不是什么大事,当时没什么钱买,对做数据的人来说真是坏了,辛辛苦苦干了一年的活没了,再做一遍再用一年,这个成本打了。所以发生这种事的时候用户都是一脑袋汗。
还有更接近要命的,更接近物理的“要命”,就是股票,其实这些数据也不大,股票交易厅,交易系统还没有做双机,在1997、1998年的时候,很多没做双机系统一宕机,很快,能砸屏的都砸碎了。我那会儿其实还在大学念书,兼职给人装个双机干点私活,挣点外快,直接出来就是缠着绷带胳膊吊着这么出来,就是股民打的,交易系统交易不了你就想吧。丢数据对用户来讲是很要命的事。
最早只要数据不丢,能找得回来,稍微停一会儿还可以理解,但是有一些业务,渐渐像股票这种业务停都不准停,停就坏事了,你让我稍微卡顿一点都会是事故,有问题,其实对双机系统要求越来越高了。
我们今天至少在讨论可靠性这个概念的时候,大家说的更多的还是更基本,不丢,在线性,不掉线,这两个层面的东西是相对基本的。其实从可靠性来讲还有更高的,比如说变慢算不算是一种可靠性的损伤,业务角度来讲一定是,甚至业务系统变慢比彻底断了还可怕,因为变慢你不知道是哪儿的问题,一个东西坏了其实到你这儿到发现找到问题在哪儿,用的时间还短一点,因为容易找,找到哪儿坏了,该通的通了。如果一个比较复杂的业务系统某一个地方变慢了,找出问题到底在哪儿,真的有的时候花一两个月找不出来,因为这个系统太复杂了,但是变慢也是一个系统可靠性的影响。
今天我们所说的可靠性涵盖的更多还是持久性和可用性这两个更顶级的层面,AWS里面讨论的,我们看到很多业界的说法里面没有放到可靠性这个范围里面来,我相信未来可能会有比较可量化的整体的系统可靠性的评估方式、评估方法论,会把SLO,甚至更高层系统配备变更能力,其实这些东西都是对基础架构可靠性的要求。我刚才说起来就有四个层面,可能会有若干层面的这种对可靠性更细的拆解在基础架构的要求里面。这更多是方法论层面的事,今天不讲太多方法论层面的事,稍微介绍一点具体的东西。具体的东西大家看得见摸得着。
数据中心里面什么最容易出现故障,如果各位有做过运维或者在机房里面做过IT的管理者,就会有一个感觉,你的数据中心三样东西常年坏,硬盘、风扇、电源,CPU、内存、主板、机箱盖都不坏,就是这三样东西特别容易坏。而这三样东西里面风扇、电源坏了相对来说没有那么可怕,硬盘是最可怕的,因为数据直接在上面,数据整个系统的可靠性、可用性等等,最直接的就是跟硬盘有关系,所以别的不看,就是硬盘的故障是整个系统可靠性最可行的地方。硬盘我们都知道又不是一个平行的分布,也就是这个系统里面硬盘不是随时都有的概率的磁盘故障存在,如果实施过IT系统的会由直观的感觉,一个新东西上来头三个月是最麻烦的,新布一个系统一会儿这儿怀了,那儿有故障了,如果把故障全都解决了3个月没有什么事,6个月没有什么事基本上可以放心使用,一年两年没有问题,中间故障率是越低,等到到快到寿命的时候,四年、五年看你附载的轻重,如果轻就是长寿一点,重就短寿一点。今天有点问题,你就会知道在接下来两年陆陆续续都会有问题,就是这个设备的寿命差不多到了。
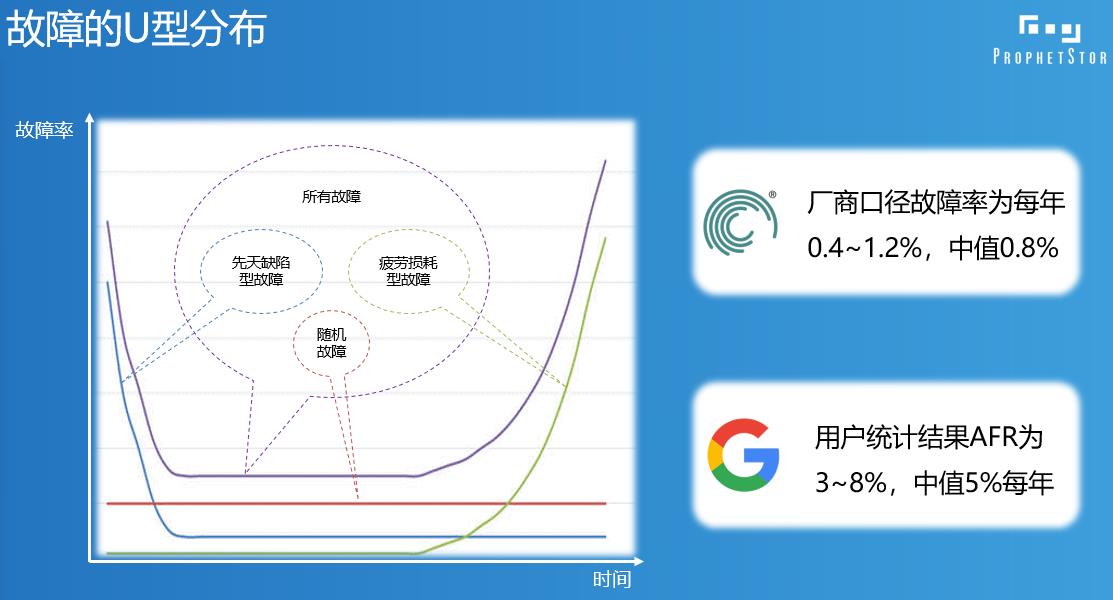 整个故障分布是一个U型分布,如果再拆开由三部分组成,一个是先天不足造成的,一上线就出问题的就是先天缺陷,硬盘在生产线上该封闭的没有封闭严,该搞平整的没搞平整,先天不合格,一到系统上就暴露问题。很快这部分筛掉就是正常的,正常使用中又在寿命之内就是环境随机故障,就看机房温度等等。到一定寿命的时候其实就是各种各样元器件的老化造成的后面的那部分。这三部分,主要是三种不同的因素造成的。这里面最好玩的就是厂商跟你讲的它的故障率跟用户自己体验到的故障率永远不一样,而且差别巨大,都知道硬盘的不可靠性有一个上下指标叫MTBS,就是平均无故障时间,这个概念以前还经常被拿出来说,但是现在已经没有人说这个东西了,因为太不靠谱了,厂商居然说我的自己的MTBS 200多万小时,你年化以后算算什么概念,我这个硬盘差不多可以从恐龙灭绝之前用到现在,这简直是太不靠谱了。所以现在更多是看一些,厂商会有自己的返修率统计报告,那个MTBS已经不是计算你硬盘故障率的一个指标了,那个完全忽略,那个东西你就当不存在。真正厂商嘴里说的认的自己的磁盘故障率是他每年告诉你的那个报告,他每年卖出去多少盘,有多少的返修,这个百分比是多少,即便按照那个比例是0.4%-1.2%这样的一个比例。当然厂商有时候不愿意承认都是故障。什么叫故障,什么叫非故障,中间是有灰色地带的。不管怎么说,这些设备我们姑且把它算作故障比例,0.4%-1.2%这是厂商基本上认可的磁盘的年故障率,但这个比例在用户感受来讲还是偏低。
谷歌曾经在2006年/2007年的时候,发过一篇论文,论文统计了谷歌自己用过所有的硬盘,把硬盘的年故障率拿出来统计出来,谷歌报告里面大概是5-8%,故障率非常高。当然我们可以有理由认为谷歌用磁盘用的太狠了,有的没有那么长,总的来说是3-8%这样一个范围,还是远大于厂商统计的故障率。
我们知道几件事,第一件事,好象不是所有的故障盘都返到厂商去了;第二件事可能统计的口径不一样,统计的视角不一样,数据不一样。真正问我磁盘的故障率到底有多少,我还真是没法用一个数据告诉你,只能说不同的角度不同的视角数据不一样,但是这不访问我们做一些基本的推算。
整个故障分布是一个U型分布,如果再拆开由三部分组成,一个是先天不足造成的,一上线就出问题的就是先天缺陷,硬盘在生产线上该封闭的没有封闭严,该搞平整的没搞平整,先天不合格,一到系统上就暴露问题。很快这部分筛掉就是正常的,正常使用中又在寿命之内就是环境随机故障,就看机房温度等等。到一定寿命的时候其实就是各种各样元器件的老化造成的后面的那部分。这三部分,主要是三种不同的因素造成的。这里面最好玩的就是厂商跟你讲的它的故障率跟用户自己体验到的故障率永远不一样,而且差别巨大,都知道硬盘的不可靠性有一个上下指标叫MTBS,就是平均无故障时间,这个概念以前还经常被拿出来说,但是现在已经没有人说这个东西了,因为太不靠谱了,厂商居然说我的自己的MTBS 200多万小时,你年化以后算算什么概念,我这个硬盘差不多可以从恐龙灭绝之前用到现在,这简直是太不靠谱了。所以现在更多是看一些,厂商会有自己的返修率统计报告,那个MTBS已经不是计算你硬盘故障率的一个指标了,那个完全忽略,那个东西你就当不存在。真正厂商嘴里说的认的自己的磁盘故障率是他每年告诉你的那个报告,他每年卖出去多少盘,有多少的返修,这个百分比是多少,即便按照那个比例是0.4%-1.2%这样的一个比例。当然厂商有时候不愿意承认都是故障。什么叫故障,什么叫非故障,中间是有灰色地带的。不管怎么说,这些设备我们姑且把它算作故障比例,0.4%-1.2%这是厂商基本上认可的磁盘的年故障率,但这个比例在用户感受来讲还是偏低。
谷歌曾经在2006年/2007年的时候,发过一篇论文,论文统计了谷歌自己用过所有的硬盘,把硬盘的年故障率拿出来统计出来,谷歌报告里面大概是5-8%,故障率非常高。当然我们可以有理由认为谷歌用磁盘用的太狠了,有的没有那么长,总的来说是3-8%这样一个范围,还是远大于厂商统计的故障率。
我们知道几件事,第一件事,好象不是所有的故障盘都返到厂商去了;第二件事可能统计的口径不一样,统计的视角不一样,数据不一样。真正问我磁盘的故障率到底有多少,我还真是没法用一个数据告诉你,只能说不同的角度不同的视角数据不一样,但是这不访问我们做一些基本的推算。
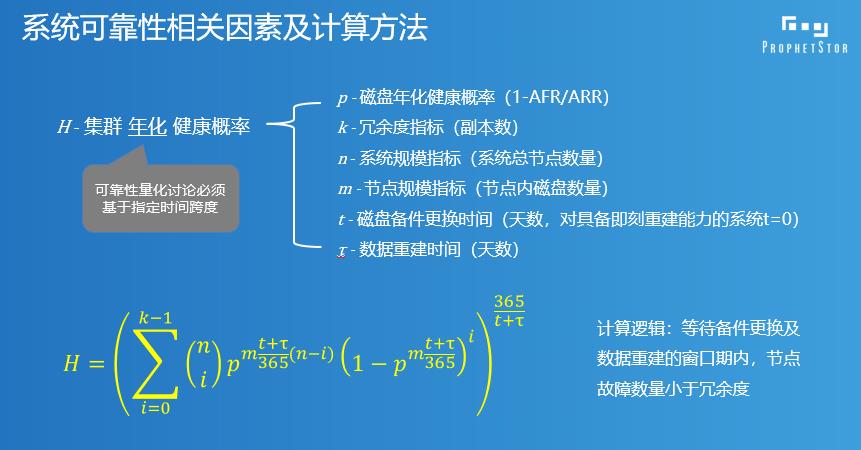 这里跟大家分享一下可靠性计算的模型,我相信这么一大早起来如果给大家一步一步推公式的话,推到第三页大家开始下面打呼噜了。简单介绍一下,这是一个简单的软件式存储也好分布式存储也好,它里面有故障,有跨节点这不叫故障。这种情况叫故障,刚才这种情况是两个副本,这就叫故障了,对三个副本来说就是故障了,而且这个故障我们经常说两个节点同时故障叫丢数据,其实什么叫“同时”,没有那么严格精确的同时,其实是一个东西坏了之后有一个修复时间,在这个修复时间之内不能有第二个东西坏,或者不能有太多的东西坏了,太多的东西坏了这个数据会丢。我们所谓的“同时”,故障的间隔小于我们说的设备更换和修复窗口,当相邻故障小于这个窗口的时候这就是我们一般意义所讲的“同时故障”。简单来说这个公式就是这样的一个公式,为什么要自己推这个公式,我发现网上有一些是错的,我去网上找现成的,谁也不会没事自己虐自己自己推这个公式的,都是自己去找一个现成算了,但是我发现网上都是错的,自己推了一个东西。单磁盘的故障概率放到刚才说的分布式的系统里面,它的可靠性是怎样计算来的。看着很复杂乱七八糟一大堆,其实挺容易的。我把大的推演过程放到PPT里面,会后资料会分享给各位。
简单来说就是概率要先做年化,把一年里面比如说一个硬盘在一年里的故障概率,转化成t+π数据修复这样的一个时间窗口,你需要做指数化的转换,你根据一个硬盘的故障率,这些推导过程不细讲了,估计再细讲各位都要睡着了,大概了解一下。从硬盘的故障概率推导到节点的故障概率,从节点的故障概率再转化回年化的可靠性。我说的错都是在这儿,网上很多的东西忘了年化,得出来的结论不能做量化计算,你量化计算会有问题。整个系统的可靠性随着指标变化的趋势,这个n是集群里的节点数,m是每个节点硬盘的数量,这个是中间的窗口,随着窗口期系统的可靠性的变化。
这里跟大家分享一下可靠性计算的模型,我相信这么一大早起来如果给大家一步一步推公式的话,推到第三页大家开始下面打呼噜了。简单介绍一下,这是一个简单的软件式存储也好分布式存储也好,它里面有故障,有跨节点这不叫故障。这种情况叫故障,刚才这种情况是两个副本,这就叫故障了,对三个副本来说就是故障了,而且这个故障我们经常说两个节点同时故障叫丢数据,其实什么叫“同时”,没有那么严格精确的同时,其实是一个东西坏了之后有一个修复时间,在这个修复时间之内不能有第二个东西坏,或者不能有太多的东西坏了,太多的东西坏了这个数据会丢。我们所谓的“同时”,故障的间隔小于我们说的设备更换和修复窗口,当相邻故障小于这个窗口的时候这就是我们一般意义所讲的“同时故障”。简单来说这个公式就是这样的一个公式,为什么要自己推这个公式,我发现网上有一些是错的,我去网上找现成的,谁也不会没事自己虐自己自己推这个公式的,都是自己去找一个现成算了,但是我发现网上都是错的,自己推了一个东西。单磁盘的故障概率放到刚才说的分布式的系统里面,它的可靠性是怎样计算来的。看着很复杂乱七八糟一大堆,其实挺容易的。我把大的推演过程放到PPT里面,会后资料会分享给各位。
简单来说就是概率要先做年化,把一年里面比如说一个硬盘在一年里的故障概率,转化成t+π数据修复这样的一个时间窗口,你需要做指数化的转换,你根据一个硬盘的故障率,这些推导过程不细讲了,估计再细讲各位都要睡着了,大概了解一下。从硬盘的故障概率推导到节点的故障概率,从节点的故障概率再转化回年化的可靠性。我说的错都是在这儿,网上很多的东西忘了年化,得出来的结论不能做量化计算,你量化计算会有问题。整个系统的可靠性随着指标变化的趋势,这个n是集群里的节点数,m是每个节点硬盘的数量,这个是中间的窗口,随着窗口期系统的可靠性的变化。
本文来源于DOIT传媒,文章内容仅供参考,不构成投资建议。


评论列表