
太阳每天照常升起,如果哪天太阳也出了故障,跟往常不一样了,那绝对是世界级大新闻,首先得庆幸这样的事情通常只会出现在科幻电影里。
Github是程序员的世界里类似的存在。2015年的统计数字显示,Github托管了5700万个代码仓库,有2800万个用户活跃在Github上,Github的用户对故障不陌生,每次Github出故障都能引起一番热议。最近一次故障中,Github的中断持续了24小时,用户无法提交代码更新,也没办法从Github下载最新版本的代码,正常的工作节奏完全被打乱了。
“星轨”可能是中国互联网服务商创造的新名词,说是新浪微博衡量服务器抗压能力的新单位,一星轨表示一个一线明星出轨给新浪微博所带来的流量,据说微博的服务器现在能同时抗击8星轨,类似的描述常见于描述楼梯的抗八级地震一样。不久前的“官宣”事件又一次突破了新浪微博服务器的承重,服务部分中断了,广大网友把官宣玩坏了,也顺带把新浪微博的技术人员又吓了一跳。
说了这么多,就只是想说,故障,宕机什么的,离我们普通人真的很近,这些上了新闻的只是其中一少部分,更多故障宕机之类的事件广大网友根本察觉不到,系统就被修复到能对外服务了,这类专门应对故障宕机的系统常见的就有多活系统。
多活系统通常是为了增强系统的可靠性、业务的连续性,使用业务运行不受故障/灾难影响。
Github也搭建了多活系统,结果多活系统出了故障。Github的两个机房的网络出现中断,服务发生切换中由于多活系统考虑不全,导致系统发生脑裂,两个机房的数据不一致。为了保证用户数据的一致性不得不停服,24小时之后数据才得以恢复。青云QingCloud运营副总裁林源向笔者介绍说。
故障之后多活系统就开始发挥作用了,评价多活水平的是RTO和RPO。RTO是指业务恢复时间,就好比玩游戏时卡的时候到恢复的时间段,游戏时最常见的应该是网络故障。RPO表示故障丢失的数据量,刚才完成的操作系统给丢了,比如你买了装备,一转眼故障后装备没了钱也没了,也可能是你击杀了别的玩家,一眨眼回来显示你输了。
玩游戏还好,要是偶尔银行故障的RTO、RPO的水平低了,也来这么一回,那事情可就大了。
双活虽然好,但是贵,建造也麻烦,好在不是谁都需要双活,比如你手里的手机偶尔莫名重启一下,那没啥事儿。
要是双十一的时候,明明零点抢到了特价iPhoneX MAX,一眨眼,钱也付了,订单丢了,店家说看不见,你说你付了钱,那不得哭啊。要是双十一的时候,下单的按钮始终点不了,钱一直付不了,每秒几十万、几百万、几千万订单额的商家不得哭晕在厕所吗?
要是银行的大型机也莫名其妙的重启了,那叫超级大事故,经济秩序可能就乱掉了。银行、保险、重型制造、电力等涉及国计民生的业务系统如果出现不可恢复的故障,那后果真实不堪设想。所以,这些场景要求数据不能丢。
林源介绍说,像银行的IT架构都需要符合银监会的规定,需要有两地三中心。所谓两地三中心,两地是指两个城市,三中心是指三个数据中心。同城的数据中心相互间是双活系统,异地的一个数据中心则主要负责备份,以此保障数据的安全性,业务的连续性。
两地三中心固然好,缺点就是贵。
前期投入在两个城市建三个数据中心,贵!三个机房的软硬设备,连接设备,贵!业务上线后,需要很多专门的运维人员,贵!
林源介绍说,建这么一套复杂的系统下来至少得一两年,时间就是金钱企业绝对。青云在构建北京大区、广东大区和上海大区的时候,每个区域、每个城市至少需要一年时间,就这还算快的。
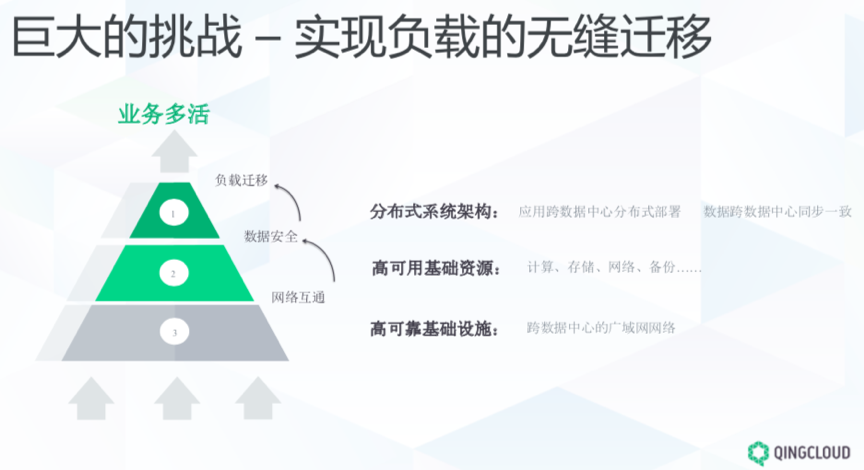
通常所说的多活是指业务的多活,业务的多活是最终要求。他需要数据中心网络互通、数据安全、负载迁移等层面层层递进,底层任意一个环节出现问题,整套多活系统可能会崩溃。
GitHub多活系统也是煞费苦心,GitHub投入巨大,在两个数据中心间买了100G光纤做互联,做了非常充足的准备,结果还是出了问题。服务于技术人的网站也出现技术问题,听起来挺讽刺的,其实这也正说明了多活系统的复杂性。
从技术上来讲,多活的实施很难,从需求上来看,多活的需求很普遍。于是,公有云便开始提供共性的多活服务,青云就有这样的多活服务。
青云的多活服务有基础架构、基础设施和分布式应用三个层次组成。
其中,基础设施是指数据中心本身,指的是青云在北京,上海和广东建立的数据中心,一个地区的数据中心算一个Region,一个Region有多个可用区,比如北京有北京3B,北京3D,北京3C这样三个可用区。3个可用区之间的距离(30-50公里之间)可以满足银监会对银行数据中心的要求,另外,机房之间还需要有高速低延迟带宽支持。
在基础设施之上的是IaaS基础架构,IaaS层的多活服务一般都指的构建于多个数据中心之间的负载均衡服务,负载均衡器将接收到的负载分发到多个数据中心,任何单个数据中心故障都没什么影响。另外,多活系统的网络也很麻烦,没关系,青云自己的数据中心已经做好了。
多活系统最上一层的是分布式应用。其实这里说是应用不是特别合适,应用一般都是用户自己开发的,而青云所提供的通常来说是数据库(如果非要说数据库也是应用也可以),数据库很难,分布式数据库更难,有了分布式数据库之后数据库的多活就方便多了,将数据库分布在不同的可用区就能提供很好的多活数据库服务。青云的平台上支持自研的分布式数据库MySQL Plus,另外也支持MongoDB。
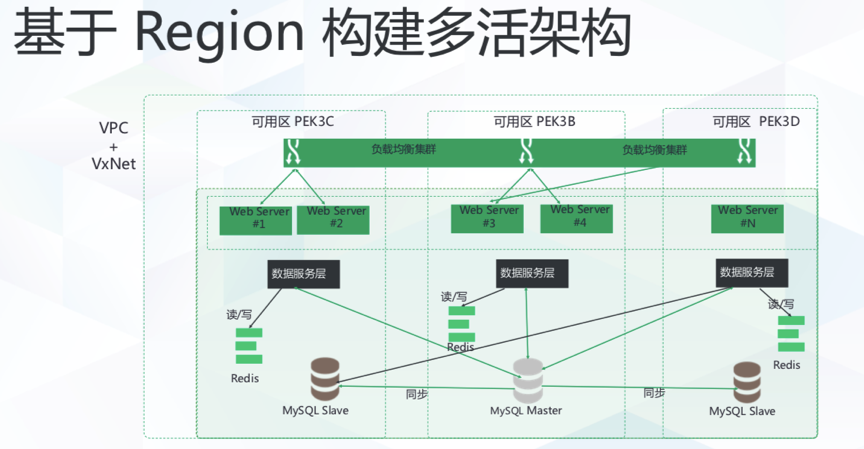
有了这三层服务之后,用户在青云的平台上,只要选择了三个可用区之一,使用了负载均衡器,然后部署了分布式数据库,然后部署自己的分布式应用之后就算构建了自己的多活服务。这套系统下来,即使是初创公司也能享受到高大上的多活服务,对青云这样的云服务商来说,也没有太多额外的成本,因为这服务是通用的。
所以,对于选用公有云多活服务的用户来说,额外的成本并不明显,远远低于自己搭建的多活服务。
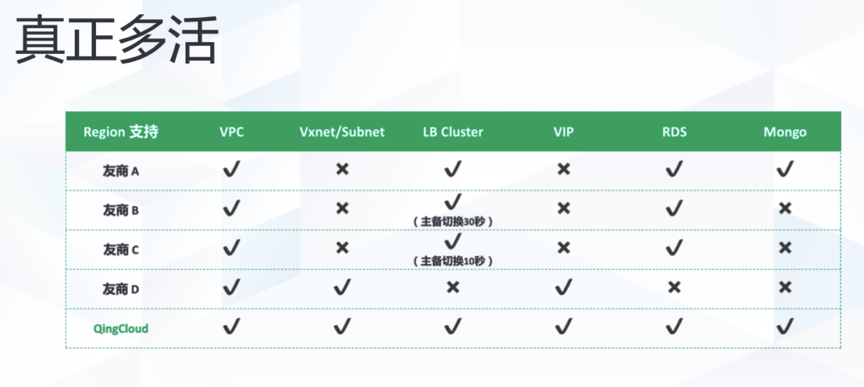
搭建多活系统,这是公有云的天然优势之一,所以很多公有云服务商都有多活服务,不过,与一些友商相比,青云的多活的服务能力更全面一些。(见下图)
最近,AWS发布了混合云的产品方案Outposts,让AWS云平台连接到企业数据中心内部,让用户在本地也享受到跟云端一样的服务体验。这一思想和类似的描述在恰好正式青云的宣传描述,青云自一开始就比较重视企业用户本地的使用体验,公有云和私有云两条腿走路,笔者也认为这是青云能实现较快盈利的一个重要原因。
正因为如此,青云的多活不仅可以用在公有云,也用在企业混合云环境,照顾了许多企业用户的实际需求,也能为企业用户搭建多活方案。
无论如何,我们是看到,云服务商提供的多活有明显优势,成本上,实施门槛上都大大降低,用户不会因为使用多活服务而承担太多额外成本。理论上不存在绝对不出问题的架构,但多活架构可以把风险降低再降低,相信未来,会有更多不那么关键,但是对服务体验有要求的企业也都会主动寻找云的多活服务。







