

今天我主要介绍一下我们做的针对一组NVM(Non-volatile memories,非易失存储器)的进展。
目前我们的项目侧重在解决怎么存,怎么存得快,存得准,还有存得可靠,也就是高效、低能耗解决问题。
对于一些响应延迟要求比较高的应用,比如说淘宝、12306,希望一点击就出来的应用,或者说,要求数据在内存里面存放和运算。内存的需求和供给存在很大的差距,大数据的计算需要的内存容量是普通的1000倍,现在的通过体系结构是RRAM、DSRM、SSD等等。为了满足大规模内存的需要,Cache放在一个DRAM里会有这样的问题,因为是用电荷来存的,所以就存在如何保证电荷检测、电荷泄露等等的,而DRAM是电容来保存信息的,所以有一个充电放电的过程,能耗也比较高,据统计40%到50%的能耗来自Memory,DRAM的能耗有40%来自于刷新,这也是DRAM为什么受到关注的原因。
再来说说制程。制程达到几个纳米之后就会停止,现在NVM比较受关注,最受关注的有三个,另外两个是STTMaRM和DARM。不过,STTMARM容量上不去,而RRAM容量可以做得非常大,这也是这几年RRAM关注度比较高的原因。
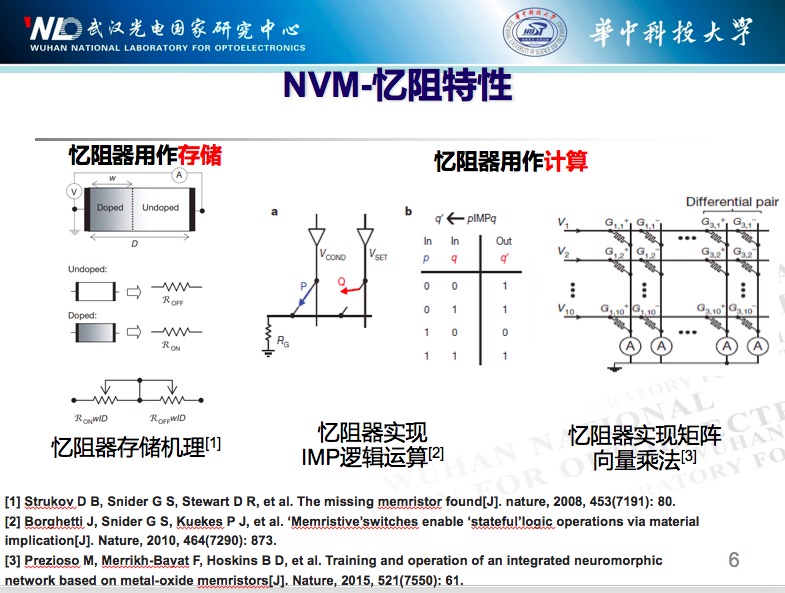
NVM的忆阻器一是可以做存储,第二个是可以做计算;2008年做存储,2010年就可以做逻辑运算,到2015年实现矩阵向量乘法,做存算结合。它的主要原理,应该说行上面有一个电阻,加一个电压上面就会出现电流,比如说每一个行上加不同的电压,就产生了电流。
来看一下,怎么样能够存得好?因为要能计算,首先是要能存下来,存下来就是刚才说的矩阵,也就是一个模拟量,类似一个非信息的点,希望能够尽量存得准,同时也能够实现高效低能耗。大家对此研究比较热的原因,就是非理想因素的影响。
一个低组态RRAM的单元,要进行一个高组态,面临reset的延迟,要变化高阻态,就是带正离子和带负离子正位。相反的就是,再加上一个反向的电压,金属氧化物的阻值状态的变化实现数据的存储,当它做RESET,从1变成0的时候,加一个电压会变大,加一个RESET的时候就会有延迟,就会变慢。理想状态是一个单元就有一个控制器,但这是不可能的,会浪费很多芯片的面积。这里面就会有很多IR drop的问题。
比如说要在某个单元上面加一个单元,上面列的单元都有一个电压,也就会有一个电流,目前的方法就是要把列上面加一个半偏置,加上一个1/2的V,相当于上面的数也会有问题。
首先就是线路上,每一个线路都要考虑,每一个面和行都有电流的线路,上面都有一个电压,也有一个电阻,而且能耗比较高,如果这些都是一些高阻态存着,就会存在一些问题。只有克服电压和电阻这些问题才能存得准。
传统的方式是在面和行上加电压,然后测试、改变它的阻值,观察数据的变化,RESET的数字从144ns变成了240ns,受到这个启发,我们做了相应的工作。
首先是“双端写驱动”,如果是使用了双端控制之后,电压就会升上去,就会缓解延迟,在这个电压上存在这样的分布,慢慢会下降为对角线的分布。如何应用对角线的分布?可以做一个优化,比如说crossbar的阵列上下都有驱动,两边都可以加。如果从右边和下边两驱动,这个线就是这么长,这个延迟就是这么长,相应的延迟也会比较短,所以我们就这样开始分区:把左下角放大,可以看到这一块的延迟是最低的,慢慢从对角线的方式延迟是最大的,是这样的一个控制方式。
这样有一个什么好处?如果不做对角线划分,写这块区域的时候,就要保证最坏的一个要在限定的长时间写完,建了一个分区之后,得到的一个好处“告诉上层,可以不同的延迟”。上层就可以通过内存分配和边缘优化进行低延迟使用,比如说冷热数据调度,热数据也做一些地址的转化等等。
第二,提高性能。在正crossbar上面做一个并行,在reset做一个延迟操作,可以进行并行来操作,这个SET的操作和RESET的操作都可以做,测试效果显示,延迟降低了22%。
第三,降低能耗,要克服倾斜电流,就需要高阻态,怎么样达到这个目的?互补组变单元。但它的缺点是影响寿命,同样也影响性能。最直观的方法就是用MEM模式,把经常访问的数据做成MEM模式,冷数据用CRS模式,如何区别冷热?记录频率的表开销。一般为了降低能耗,采取的是全浮空的状态,如果低阻态多了以后,数据就会消失。为了克服这个缺点,需要减少低阻态的数据,用MEM来存热数据,这个方式提高了可靠性和降低能耗,这种混合的方式,平均能耗能够节省7.3倍。
我们在最新的一篇论文中对此做了报道,其他还有一些相关的研究,就不再一一介绍。
我们的研究已经到了非常的底层,怎么样来做出存储器,具体就跟介绍这么多。在存得准,存得可靠的基础方面,进一步再来做计算,就可以解决计算的很多问题,如果是多个阵列集成,会有一个传递的集成,会有越来越大的误差,我们希望先解决第一步,在这方面做些工作。
今天我就讲这么多,谢谢大家!(本文未经过本人审阅)






