背景介绍
分布式系统是指一组独立的计算机,通过网络协同工作的系统,客户端看来就如同单台机器在工作。随着互联网时代数据规模的爆发式增长,传统的单机系统在性能和可用性上已经无法胜任,分布式系统具有扩展性强、可用性高、廉价高效等优点得以广泛应用。
但与单机系统相比,分布式系统在实现上要复杂很多。CAP理论是分布式系统的理论基石,它提出以下3个要素:
l Consistency(强一致性):任何客户端都可以访问到同一份最新的数据副本。
l Availability(可用性): 系统一直处于可服务状态,每次请求都能获得非错的响应。
l Partition-tolenrance(分区可容忍性):单机故障或网络分区,系统仍然可以保证强一致性和可用性。
一个分布式系统最多只能满足其中2个要素。对于分布式系统而言,P显然是必不可少的,那么只能在AP和CP之间权衡。AP系统牺牲强一致性,这在某些业务场景下(如金融类)是不可接受的,CP系统可以满足这类需求,问题的关键在于会牺牲多少可用性。传统的主备强同步模式虽然可以保证一致性,但一旦机器故障或网络分区系统将变得不可用。paxos和raft等一致性算法的提出,弥补了这一缺陷。它们在保证CP的前提下,只要求大多数节点可以正常互联,系统便可以一直处于可用状态,可用性上显著提高。paxos的理论性偏强,开发者需要自己处理很多细节,这也是它有很多变种的原因,相对而言raft更易理解和工程化,一经提出便广受欢迎。
在我们关注的消息中间件领域,金融支付类业务往往对数据的强一致性和高可靠性有严格要求。
在对主流的消息中间件进行调研后,发现它们在应对这种场景时都存在一定的不足:
l RabbitMQ:一个请求需要在所有节点上处理2次才能保证一致性,性能不高。
l Kafka:主要应用在日志、大数据等方向,少量丢失数据业务可以忍受,但不适合要求数据高可靠性的系统。
l RocketMQ:未采用一致性算法,如果配置成异步模式可能丢失数据,同步模式下节点故障或网络分区都会影响可用性。
l SQS:只提供最终一致性,不保证强一致性。
鉴于以上分析,我们设计开发了基于Raft的强一致高可靠消息中间件CMQ。接下来会介绍raft算法原理细节、如何应用在CMQ中在保证消息可靠不丢失,以及实现过程中在性能方面所作的优化。
二 Raft算法介绍
2.1 概述
Raft算法是Diego Ongaro博士在论文《In Search of an Understandable Consensus Algorithm》,2014 USENIX中首次提出,算法主要包括选举和日志同步两部分:
以下是贯穿Raft算法的重要术语:
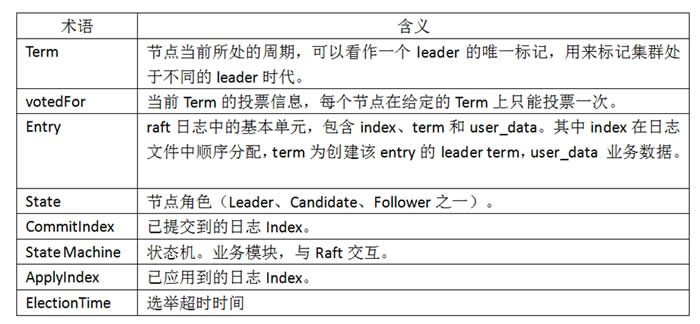
节点之间通过RPC通信来完成选举和日志同步,发送方在发送RPC时会携带自身的Term,接收方在处理RPC时有以下两条通用规则:
1) RPC中的RTerm大于自身当前Term,更新自身Term = RTerm、votedFor = null,转为Follower。
2) RPC中的RTerm小于自身当前Term,拒绝请求,响应包中携带自身的Term。
2.2 选举算法
Raft算法属于强Leader模式,只有Leader可以处理客户端的请求,Leader通过心跳维持自身地位,除非Leader故障或网络异常,否则Leader保持不变。选举阶段的目的就是为了从集群中选出合适的Leader节点。

选举流程如下:
- 节点初始状态均为Follower,Follower只被动接收请求,如果ElectionTime到期时仍未收到Leader的AppendEntry RPC,Follower认为当前没有Leader,转为Candidate。
- Candidate在集群中广播RequestVote RPC,尝试竞选Leader,其他节点收到后首先判断是否同意本次选举,并将结果返回给Candidate。如果Candidate收到大多数节点的同意响应,转为Leader。
- Leader接收客户端请求,将其转为Entry追加到日志文件,同时通过AppendEntry RPC同步日志Entry给其他节点。
选举超时值:
在选举时可能会出现两个节点的选举定时器同时到期并发起选举,各自得到一半选票导致选举失败,选举失败意味着系统没有Leader,不可服务。如果选举定时器是定值,很可能两者再次同时到期。为了降低冲突的概率,选举超时值采用随机值的方式。此外,选举超时值如果过大会导致Leader故障会很久才会再次选举。选举超时值通常取300ms~600ms之间的随机值。
2.3日志同步
选举阶段完成后,Leader节点开始接收客户端请求,将请求封装成Entry追加到raft日志文件末尾,之后同步Entry到其他Follower节点。当大多数节点写入成功后,该Entry被标记为committed,raft算法保证了committed的Entry一定不会再被修改。
日志同步具体流程:
1)Leader上为每个节点维护NextIndex、MatchIndex,NextIndex表示待发往该节点的Entry index,MatchIndex表示该节点已匹配的Entry index,同时每个节点维护CommitIndex表示当前已提交的Entry index。转为Leader后会将所有节点的NextIndex置为自己最后一条日志index+1,MatchIndex全置0,同时将自身CommitIndex置0。
2)Leader节点不断将user_data转为Entry追加到日志文件末尾,Entry包含index、term和user_data,其中index在日志文件中从1开始顺序分配,term为Leader当前的term。
3)Leader通过AppendEntry RPC将Entry同步到Followers,Follower收到后校验该Entry之前的日志是否已匹配。如匹配则直接写入Entry,返回成功;否则删除不匹配的日志,返回失败。校验是通过在AppendEntry RPC中携带待写入Entry的前一条entry信息完成。
4)当Follower返回成功时,更新对应节点的NextIndex和MatchIndex,继续发送后续的Entry。如果MatchIndex更新后,大多数节点的MatchIndex已大于CommitIndex,则更新CommitIndex。Follower返回失败时回退NextIndex继续发送,直到Follower返回成功。
5)Leader每次AppendEntry RPC中会携带当前最新的LeaderCommitIndex,Follower写入成功时会将自身CommitIndex更新为Min(LastLogIndex,LeaderCommitIndex)。
同步过程中每次日志的写入均需刷盘以保证宕机时数据不丢失。
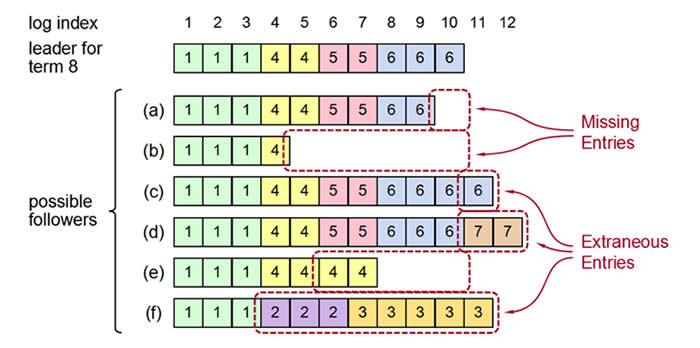
日志冲突:
在日志同步的过程中,可能会出现节点之间日志不一致的问题。例如Follower写日志过慢、Leader切换导致旧Leader上未提交的脏数据等场景下都会发生。在Raft算法中,日志冲突时以Leader的日志为准,Follower删除不匹配部分。
如下图所示,Follower节点与Leader节点的日志都存在不一致问题,其中(a)、(b)节点日志不全,(c)、(d)、(e)、(f)有冲突日志。Leader首先从index=11(最后一条Entry index +1)开始发送AppendEntry RPC,Follower均返回不匹配,Leader收到后不断回退。(a)、(b)在找到第一条匹配的日志后正常同步,(c)、(d)、(e)、(f)在这个过程中会逐步删除不一致的日志,最终所有节点的日志都与Leader一致。成为Leader节点后不会修改和删除已存在的日志,只会追加新的日志。
2.4集群管理
Raft算法中充分考虑了工程化中集群管理问题,支持动态的添加节点到集群,剔除故障节点等。下面详细描述添加和删除节点流程。
添加节点:
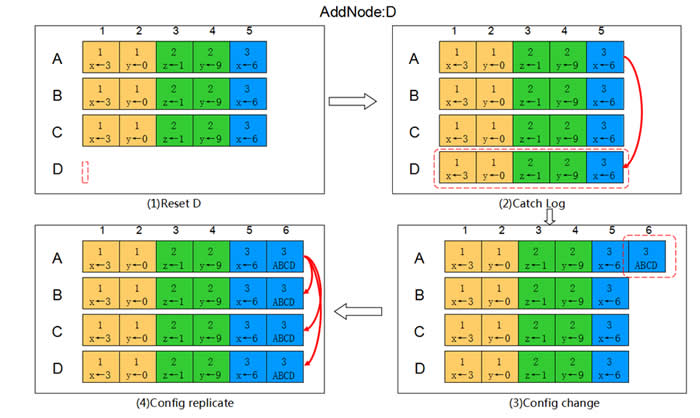
如下图所示,集群中包含A B C,A为Leader,现在添加节点D。
1) 清空D节点上的所有数据,避免有脏数据。
2) Leader将存量的日志通过AppendEntry RPC同步到D,使D的数据跟上其他节点。
3) 待D的日志追上后,Leader A创建一条Config Entry,其中集群信息包含ABCD。
4) Leader A将Config Entry同步给B C D,Follower收到后应用,之后所有节点的集群信息都变为ABCD,添加完成。
注:在步骤2过程中,Leader仍在不断接收客户请求生成Entry,所以只要D与A日志相差不大即认为D已追上。
删除节点:
如下图所示,集群中原来包含A B C D,A为Leader,现在剔除节点D。
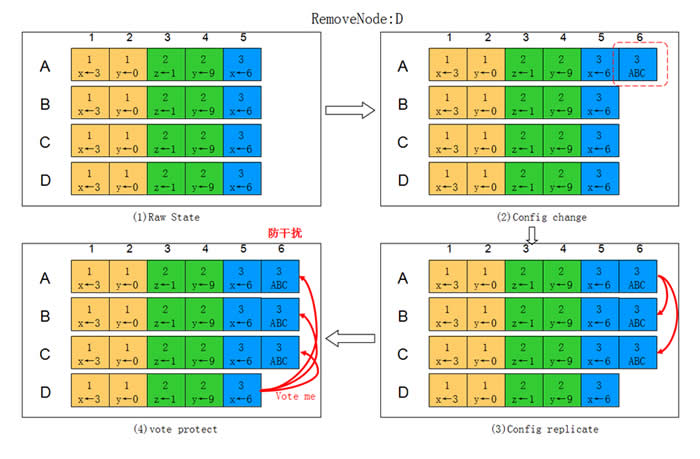
1) Leader A创建一条Config Entry,其中集群信息为ABC。
2) A将日志通过AppendEntry RPC同步给节点B C。
3) A B C在应用该日志后集群信息变为ABC,A不再发送AppendEntry给D,D从集群中移除。
4) 此时D的集群信息依旧为ABCD,在选举超时到期后,发起选举,为了防止D的干扰,引入额外机制:所有节点在正常接收Leader的AppendEntry时,拒绝其他节点发来的选举请求。
5) 将D的数据清空并下线。
2.5 快照管理
在节点重启时,由于无法得知State Matchine当前ApplyIndex(除非每次应用完日志都持久化ApplyIndex,还要保证是原子操作,代价较大),所以必须清空State Matchine的数据,将ApplyIndex置为0,,从头开始应用日志,代价太大,可以通过定期创建快照的方式解决该问题。如下图所示:
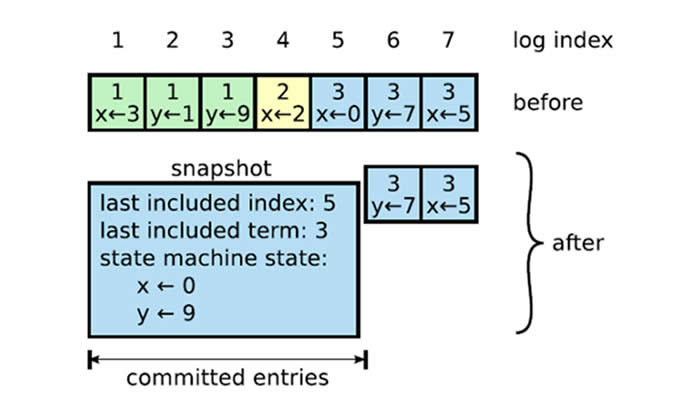
1) 在应用完Entry 5 后,将当前State Matchine的数据连同Entry信息写入快照文件。
2) 如果节点重启,首先从快照文件中恢复State Matchine,等价于应用了截止到Entry 5为止的所有Entry,但效率明显提高。
3) 将ApplyIndex置为5,之后从Entry 6继续应用日志,数据和重启前一致。
2.6异常场景及处理
Raft具有很强的容错性,只要大多数节点正常互联,即可保证系统的一致性和可用性,下面是一些常见的异常情况,以及他们的影响及处理:
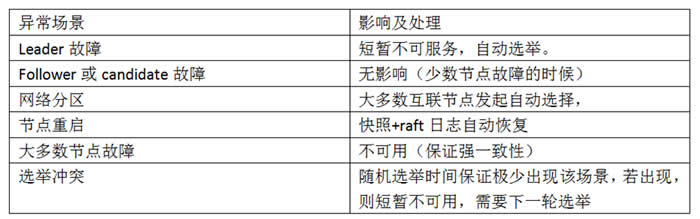
可以看到异常情况对系统的影响很小,即使是Leader故障也可以在极短的时间内恢复,任何情况下系统都一直保持强一致性,为此牺牲了部分可用性(大多数节点故障时,概率极低)。不过,Leader故障时新的Leader可能会包含旧Leader未提交或已提交但尚未通知客户端的日志。由于算法规定成为Leader后不允许删除日志,所以这部分日志会被新Leader同步并提交,但由于连接信息丢失,客户端无法得知该情况。当发起重试后会出现重复数据,需要有幂等性保证。此外,raft的核心算法都是围绕Leader展开,网络分区时可能出现伪Leader问题,也需要特殊考虑。
三 Raft在CMQ中的应用和性能优化
3.1 Raft算法在CMQ中的应用
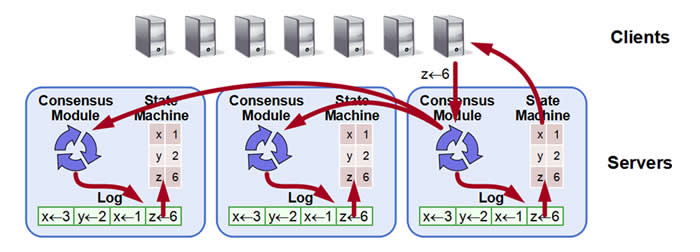
我们用State Matchine统一表示业务模块,其通过ApplyIndex维护已应用的日志index。以下为Raft与状态机交互的流程:
1)客户端请求发往Leader节点。
2)Leader节点的Raft模块将请求转为Entry并同步到Followers。
3)大多数节点写入成功后Raft模块更新CommitIndex。
4)各节点的State Machine顺序读取ApplyIndex+1到CimmitIndex之间的Entry,取出其中的user_data并应用,完成后更新ApplyIndex。
5)Leader 上的State Machine通知客户端操作成功。
6)如此循环。
下面介绍CMQ详细的生产消费流程:
生产流程:
1)生产者将生产消息的请求发往Leader的Raft模块。
2)Raft模块完成Entry的创建和同步。
3)大多数节点上持久化并返回成功后Entry标记为Committed。
4)所有节点的State Machine应用该日志,取出实际的生产请求,将消息内容写入磁盘,更新ApplyIndex。该步骤不需要刷盘。
5)Leader回复客户端Confirm,通知生产成功。
6)如果此后机器重启,通过raft日志恢复生产消息,保证了已Confirm的消息不丢失。
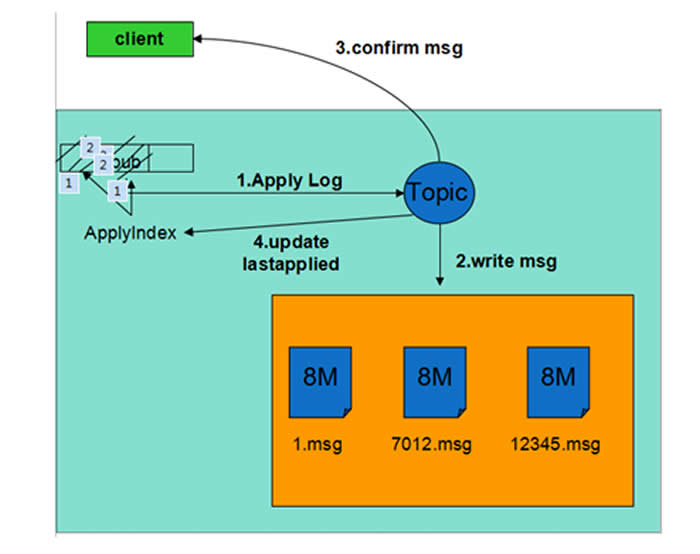
消费流程:
1)消费者从Leader节点拉取消息。
2)Leader收到后从磁盘加载未删除的消息投递给客户端。
3)客户端处理完成后Ack消息,通知服务器删除消息。
4)Ack请求经Raft同步后标记为Committed。
5)各节点状态机应用该日志,将消息对应的bit置位,将其设置为已删除并更新ApplyIndex。
6)通知客户端删除成功。
7)如果机器重启,通过Raft日志恢复Ack请求,保证了已删除的消息不会再投递。
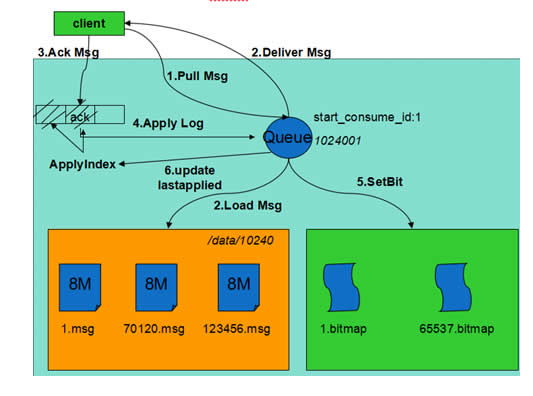
快照管理:
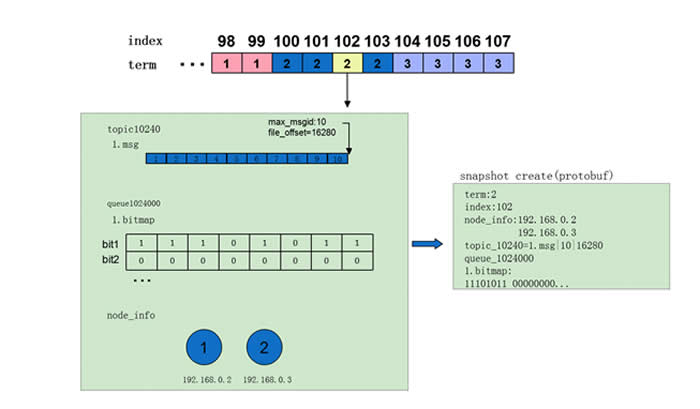
快照管理与业务紧密相关,不同系统快照制作的成本差异很大,CMQ中快照的内容十分轻量,一次快照的耗时在毫秒级,平均5min创建一次,各节点独立完成。实现上内存中维护了一份动态的快照,制作快照时首先拷贝出动态快照的副本,之后处理流继续更新动态快照,用拷贝出的副本创建快照文件,不影响实际的处理流。快照具体内容包括:
1)term:快照对应Entry的term (参照算法)
2)index:快照对应Entry的 index (参照算法)
3)node_info:Entry时的集群配置信息。
4)topic info:每个队列一项。CMQ中同一队列生产的消息顺序写入,分片存储,因此只需记录最后一个分片的状态(分片文件名,文件偏移量)。
5)queue info:每个队列一项。CMQ中采用bitmap记录消息的删除情况,在内存中维护,在制作快照时dump到快照文件。
3.2 Raft算法性能优化
Raft算法的性能瓶颈主要有两方面:
1)每次日志写入后都需要刷盘才能返回成功,而刷盘是一个比较耗时的操作。
2)由于算法限制,所有的请求都由Leader处理,不能做到所有节点皆可提供服务。
针对以上两个问题,我们做了以下优化:
Batch Processing:在请求量较大时,并不是每一条日志写入都刷盘,还是累积一定量的日志后集中刷盘,从而减少刷盘次数。对应的,在同步到Follower时也采用批量同步的方式,Follower接收后将日志批量写盘。
Multi-Raft: 进程中同时运行多个raft实例,机器之间组建多raft 组,客户端请求路由到不同的group上,从而实现多主读写,提高并发性能。通过将leader分布在不同机器上,提高了系统的整体利用率。
Async-rpc: 在日志同步过程中采用同步rpc方式,在一端处理时另一端只能等待,性能较差。我们采用异步的方式使得leader端发送和Follower端处理并发进行。发送过程中leader端维持一个发送窗口,当待确认的rpc数达到上限停止发送,窗口值上限:

在与同属于高可靠(多副本同步刷盘)的Rabbitmq性能对比中,相同压测场景下CMQ速度可以达到RabbitMQ的四倍左右。
以下为在E5-2620*2/8G*8/2T*12/SSD-80G*1/10GE*2 配置机型测试1KB消息大小时性能数据:
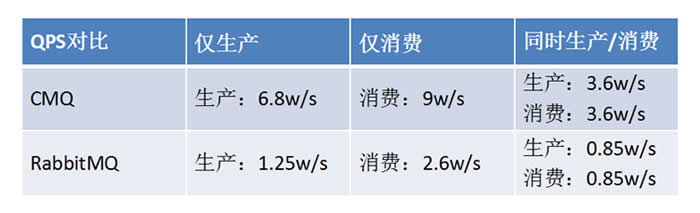
测试中CMQ采用单Raft组方式以保证测试公平性。监控显示CPU、内存和网卡均未达到瓶颈,系统瓶颈在磁盘IO,iostat显示w_await远大于svctm。主要原因在于刷盘耗时,造成写操作排队等待。
实际生产环境CMQ中我们将raft组和磁盘进行绑定,实现raft组之间磁盘的隔离,一方面保证了磁盘的顺序读写,另一方面充分利用机器的cpu 、内存、网卡等资源。
四 总结
Raft算法具备强一致、高可靠、高可用等优点, 消息中间件通常分为高可靠版本和高性能版本两种。腾讯云CMQ是一款金融级的高可靠分布式消息中间件,通过raft保证了消息的可靠不丢失。同时在性能和可用性方面相比竞品都有显著提高。