
2026年,AI大模型持续突破——万亿级参数、百万Token上下文长度已非新鲜事。但随之而来的,是一场悄无声息的“存力危机”。在中国电子工业标准化技术协会数据存储专业委员会近期的一次研讨中,多位专家指出:存力已成为制约AI发展的新瓶颈,GPU集群的核心矛盾已从“算力够不够”转向“数据能不能喂饱”。有行业调研数据表明,万卡甚至十万卡级集群中,GPU因等待数据传输而闲置的比例相当可观,仅以xAI的55万张GPU卡规模为例,闲置浪费折合近80亿美元。
更大参数规模、更长的上下文窗口,意味着训练过程中Checkpoint保存、模型加载、海量小文件高并发读写等环节对存储系统的压力呈指数级增长。有研究机构测试显示,存储性能不足会导致高达30%的GPU算力处于空闲等待状态。存储已不再是传统意义上的数据承载平台,而是影响GPU利用率、训练效率和业务连续性的关键基础设施。
更值得关注的是,AI产业的增长重心正在从训练向推理迁移。据中电标协数据存储专业委员会秘书长孙钢提供的数据,2025年全球大模型推理计算量较上年提升100倍以上;2026年计算工作负载中推理占比将提升至66%。而在推理场景下,KV Cache访问延迟直接影响token生成速率,SSD的IOPS密度则制约着并发能力和系统吞吐。存储系统的角色正在从被动数据“仓库”升级为决定token成本和系统效率的关键引擎,而国内外存储产业也因此告别周期性波动,迈入由AI驱动的黄金发展时代——CFM预计2026年全球存储市场规模有望突破6000亿美元。
面对这一行业趋势,国内算力基础设施赛道上的新锐选手云尖信息,正在用一套扎实的分布式存储解决方案交出答卷。
分层架构:高性能与高性价比可以兼得
云尖信息的思路很直接:用一个存储方案解决所有问题不现实,那就把“好钢用在刀刃上”。云尖信息推出了CS8000 X6全闪分布式并行存储系统与CS6000 X6混闪分布式并行存储系统双产品协同方案,构建“高性能访问+大容量承载”的分层数据底座。
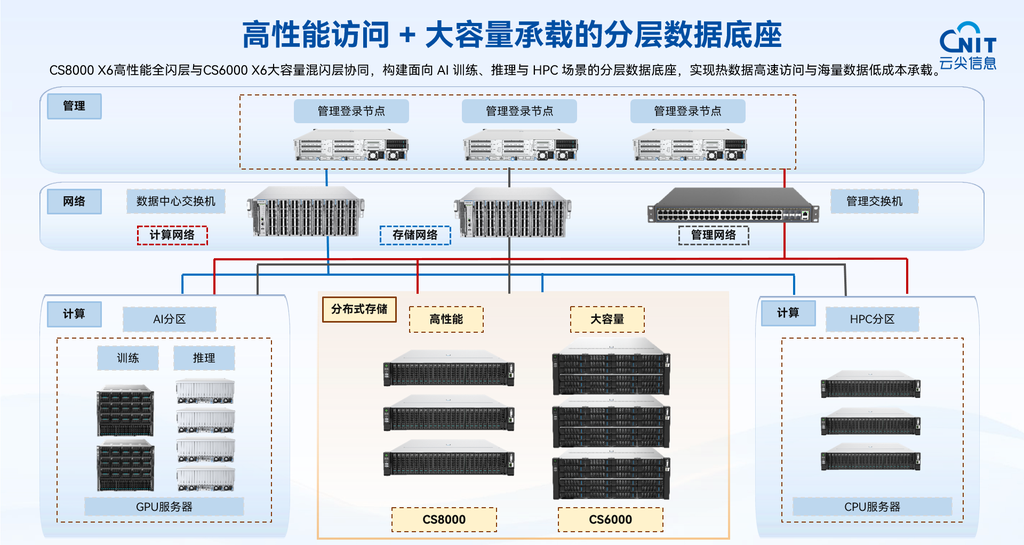
CS8000 X6定位于全闪加速层,专为应对性能密集型场景而生。单节点顺序读带宽可达40GB/s,典型小文件测试下IOPS突破400K+,主要负责承载大模型训练中的热数据集、Checkpoint高频读写、模型加载与分发等低时延、高并发需求。
CS6000 X6则定位于海量数据承载层,融合NVMe SSD、SATA SSD与高性能HDD,通过智能分层引擎根据访问频率自动迁移数据——热数据驻留SSD,冷数据归档至HDD,在保障性能的同时最大化成本效益。它支持最大8192节点横向扩展,单文件系统容量可达200PB以上,百亿级文件轻松管理,适合承载海量非结构化数据、全量训练数据与历史数据、日志归档备份等。
这种分层策略有几个值得注意的亮点:
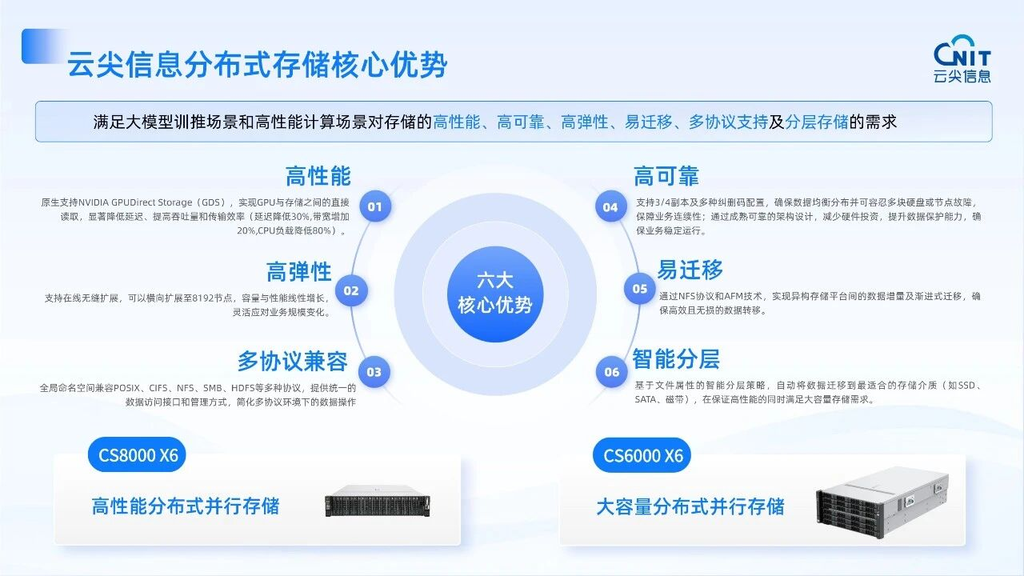
其一,原生支持NVIDIA GPU Direct Storage(GDS)。这意味着数据可以直接在NVMe SSD与GPU显存之间传输,绕过CPU和内存瓶颈。GDS作为NVIDIA Magnum IO技术栈的重要组成部分,传统I/O路径需经过“存储→CPU内存→GPU显存”的三次拷贝环节,而GDS建立点对点直通通道,使延迟降低最高可达3.8倍、吞吐量提升2-8倍。对于千卡、万卡规模的GPU集群而言,这一点直接关系到算力利用率的本质提升。TechWeb在近期报道中也引用行业案例指出,利用GDS等存储直通优化技术,自动驾驶万卡集群的GPU利用率实际提升了30%以上。
其二,对称分布式架构。CS6000 X6采用所有节点同时承担元数据与数据服务角色的对称设计,避免传统架构中元数据集中式节点带来的性能瓶颈和单点故障风险,同时大幅简化部署与运维复杂度。统一存储池同时支持文件、大数据和AI应用的多协议统一访问,有效减少数据孤岛与重复迁移的困扰。
其三,高可靠与企业级特性。CS8000和CS6000均支持3/4副本及N+2、N+3纠删码等多种冗余策略,支持硬盘、节点或网络故障下的自动修复,保障业务连续运行。
在当前行业共识中,“算力虽强,存力却拖后腿”已成为智算中心建设中的普遍矛盾。CS8000+CS6000的“双产品协同”架构,正是在高性能和性价比之间找到了一个现实而务实的平衡点。
高密存储精准卡位:C7460A X6的PB级故事
如果说CS8000和CS6000代表了云尖信息在核心存储系统层面的技术积累,那么近期推出的C7460A X6大容量存储服务器,
则体现了其在存储硬件产品化方面的另一重思考。

这款4U60盘位的存储服务器,在当前高密度存储赛道上是一个相当激进的设计。在4U标准机架内实现了60个3.5英寸盘位及8个2.5英寸盘位的超高配置,单台即可突破PB级存储容量,大幅节省机房空间与运维成本。对于温冷数据归档、备份存档、分布式存储集群部署、AI训练数据预处理等容量密集型场景而言,这种“用更少空间承载更多数据”的思路,精准切中了数据中心运营商的实际痛点。
搭配Intel EGS平台处理器、DDR5内存与PCIe5.0扩展能力,C7460AX6在大容量存储的同时并未牺牲计算性能,可同时满足AI数据预处理、大数据分析等高吞吐场景的存算协同需求。
值得关注的是,云尖信息在该系列产品上提供全栈一体化服务——主板、背板、RAID卡、网卡等全链路组件自主设计与验证,同时支持OEM定制涵盖BIOS、BMC及硬件外观等灵活配置。这种“一体化制造+灵活定制”的模式,在当下服务器代工市场格局加速变化的环境中,正在形成差异化竞争力。据了解,云尖信息目前已经构建起涵盖2U24NVMe、2U28 NVMe、4U36、4U60等主力机型的完整存储产品矩阵,全面兼容Intel及国产CPU平台,形成了覆盖从核心存储系统到硬件产品的全链条能力。
“一站式技术服务平台”何以支撑全栈能力?
剖析云尖信息的存储布局,绕不开这家公司的底层定位:“数字化产品一站式技术服务平台”。云尖信息总裁朱升宏曾对媒体做过清晰的阐释:“我们不是简单的产品供应商,也不是简单的订单执行者,而是客户数字化转型路上的‘联合创新伙伴’和‘端到端交付专家’。”
从实际动作来看,这种定位有实质内容支撑。公司构建了“研发+制造+服务”一体化的全链条能力,区别于传统的纯代工厂或纯方案商。截至目前,云尖信息在职员工超过2000名,拥有杭州、北京两大研发中心,总部位于杭州萧山“中国视谷”,总建筑面积超14万平方米。
值得注意的是,云尖信息的核心团队多来自华为、新华三体系。创始人朱升宏曾担任新华三研发总裁、供应链副总裁等核心职务,团队平均从业经验超过15年。这种成建制的“大厂基因”赋予了云尖信息
在ICT基础设施领域深厚的技术积累和产业化落地能力——从硬件设计到供应链管理再到制造交付的全链条能力,并不是靠短时间就能建立起来的护城河。
业务端,云尖信息已形成三大核心板块:AI智算解决方案、定制化及自研白牌产品(覆盖服务器、交换机、存储设备等全系列硬件产品)、以及覆盖PCB设计、热设计、EMC设计、电子制造服务等的全生命周期技术服务。目前服务客户覆盖互联网、AI、汽车电子、工业控制、智慧能源、智慧医疗等数十个行业。
写在最后:存储正在扮演“新主角”
回到存储本身。云尖信息的这一系列动作释放出的信号不难捕捉:在AI大模型训练从“暴力堆算力”走向“系统效率精细化竞争”的下半场,存储不再是依附算力的“配角”,而是与算力、网络平起平坐的关键基础设施。从DOIT峰会的行业讨论到各大厂商的产品布局,这一点正在成为业界高度一致的判断。
云尖信息以CS8000 X6与CS6000 X6双产品协同构建分层存储底座,以C7460A X6等存储服务器产品矩阵覆盖硬件层的多样化需求,辅以全链条“一站式技术服务”能力——这种从系统到硬件的完整布局,在当下AI基础设施赛道中并不常见。
当然,挑战也同样清晰。国内智算中心建设竞争激烈,头部云服务商和互联网巨头自有存储系统实力雄厚,传统企业存储厂商同样在加速AI适配。云尖信息能否在这一赛道上持续扩大市场份额,取决于其分层存储方案能否在更多实际部署场景中证明TCO优势和工程化落地的可靠性。
但至少,云尖信息用它的产品矩阵说明了“存力”可以做到什么程度——高性能不必牺牲性价比,大容量不必牺牲访问效率。在AI算力与数据基础设施双引擎驱动的时代,这或许正是“真需求”所在。






