
9月24日,2025云栖大会,阿里巴巴集团CEO吴泳铭宣布阿里云重磅升级全栈AI体系,实现从AI大模型到AI基础设施的技术更新。面向新一轮智能革命,阿里云将全力打造成为全栈人工智能服务商。
AI时代,大模型将是下一代操作系统,超级AI云是下一代计算机。吴泳铭认为,超级AI云需要超大规模的基础设施和全栈的技术积累,未来,全世界可能只会有5-6个超级云计算平台。阿里云将持续加大投入,迎接超级人工智能时代到来。
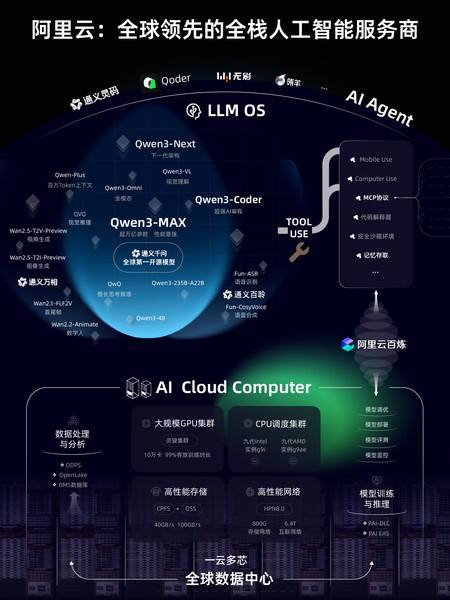
大模型七连发,Qwen3-Max性能跻身全球前三,超过GPT5
围绕大模型和AI云,2025云栖大会现场,阿里云智能首席技术官周靖人发布了多项重磅技术更新。通义大模型7连发,在模型智能水平、Agent工具调用和Coding能力、深度推理、多模态等方面实现多项突破。

2025云栖大会,阿里云CTO周靖人发布多项重磅技术更新
在大语言模型中,阿里通义旗舰模型Qwen3-Max全新亮相,性能超过GPT5、Claude Opus 4等,跻身全球前三。Qwen3-Max包括指令(Instruct)和推理(Thinking)两大版本,其预览版已在 Chatbot Arena 排行榜上位列第三,正式版性能可望再度实现突破。
Qwen3-Max是通义千问家族中最大、最强的基础模型,预训练数据量达36T tokens,总参数超过万亿,拥有极强的Coding编程能力和Agent工具调用能力。在大模型用Coding解决真实世界问题的SWE-Bench Verified测试中,Instruct版本斩获69.6分,位列全球第一梯队;在聚焦Agent工具调用能力的Tau2-Bench测试中,Qwen3-Max取得突破性的74.8分,超过Claude Opus4和DeepSeek-V3.1。Qwen3-Max推理模型也展现出非凡性能,结合工具调用和并行推理技术,其推理能力创下新高,尤其在聚焦数学推理的AIME 25和HMMT测试中,均达到突破性的满分100分,为国内首次。
下一代基础模型架构Qwen3-Next及系列模型正式发布,模型总参数80B仅激活 3B ,性能即可媲美千问3旗舰版235B模型,实现模型计算效率的重大突破。Qwen3-Next针对大模型在上下文长度和总参数两方面不断扩展(Scaling)的未来趋势而设计,创新改进采用了混合注意力机制、高稀疏度 MoE 结构、多 token 预测(MTP)机制等核心技术,模型训练成本较密集模型Qwen3-32B大降超90%,长文本推理吞吐量提升10倍以上,为未来大模型的训练和推理的效率设立了全新标准。
在专项模型方面,千问编程模型Qwen3-Coder重磅升级。新的Qwen3-Coder与Qwen Code、Claude Code系统联合训练,应用效果显著提升,推理速度更快,代码安全性也显著提升。Qwen3-Coder此前就广受开发者和企业好评,代码生成和补全能力极强,可一键完成完整项目的部署和问题修复,开源后调用量曾在知名API调用平台OpenRouter上激增1474%,位列全球第二。
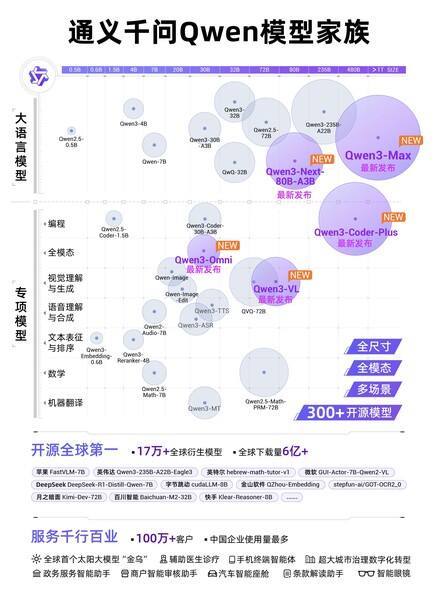
通义千问Qwen模型家族
在多模态模型中,千问备受期待的视觉理解模型Qwen3-VL重磅开源,在视觉感知和多模态推理方面实现重大突破,在32项核心能力测评中超过Gemini-2.5-Pro和GPT-5。Qwen3-VL拥有极强的视觉智能体和视觉Coding能力,不仅能看懂图片,还能像人一样操作手机和电脑,自动完成许多日常任务。输入一张图片,Qwen3-VL可自行调用agent工具放大图片细节,通过更仔细的观察分析,推理出更好的答案;看到一张设计图,Qwen3-VL 就能生成Draw.io/HTML/CSS/JS 代码,“所见即所得”地完成视觉编程。此外,Qwen3-VL还升级了3D Grounding(3D检测)能力,为具身智能夯实基础;扩展支持百万tokens上下文,视频理解时长扩展到2小时以上。
全模态模型Qwen3-Omni惊喜亮相,音视频能力狂揽32项开源最佳性能SOTA,可像人类一样听说写,应用场景广泛,未来可部署于车载、智能眼镜和手机等。用户还可设定个性化角色、调整对话风格,打造专属的个人IP。类似于人类婴儿一出生就全方位感知世界,Qwen3-Omni一开始就加入了“听”、“说”、“写”多模态混合训练。在预训练过程中,Qwen3-Omni采用了混合单模态和跨模态数据。此前,模型在混合训练后,各个功能会相互掣肘甚至降智,比如音频理解能力提升,文字理解能力反而降低了。但Qwen3-Omni在实现强劲音频与音视频能力的同时,单模态文本与图像性能均保持稳定,这是业内首次实现这一训练效果。
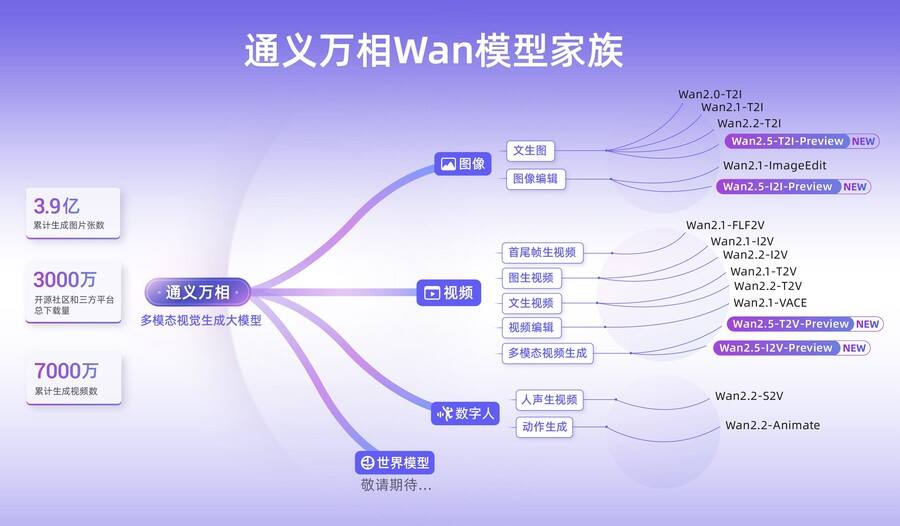
通义万相Wan模型家族
通义大模型家族中的视觉基础模型通义万相,推出Wan2.5-preview系列模型,涵盖文生视频、图生视频、文生图和图像编辑四大模型。通义万相2.5视频生成模型能生成和画面匹配的人声、音效和音乐BGM,首次实现音画同步的视频生成能力,进一步降低电影级视频创作的门槛。通义万相2.5视频生成时长从5秒提升至10秒,支持24帧每秒的1080P高清视频生成,并进一步提升模型指令遵循能力。此次,通义万相2.5还全面升级了图像生成能力,可生成中英文文字和图表,支持图像编辑功能,输入一句话即可完成P图。

通义百聆发布
2025杭州云栖大会上,通义大模型家族还迎来了全新的成员——语音大模型通义百聆,包括语音识别大模型Fun-ASR、语音合成大模型Fun-CosyVoice。Fun-ASR基于数千万小时真实语音数据训练而成,具备强大的上下文理解能力与行业适应性;Fun-CosyVoice可提供上百种预制音色,可以用于客服、销售、直播电商、消费电子、有声书、儿童娱乐等场景。
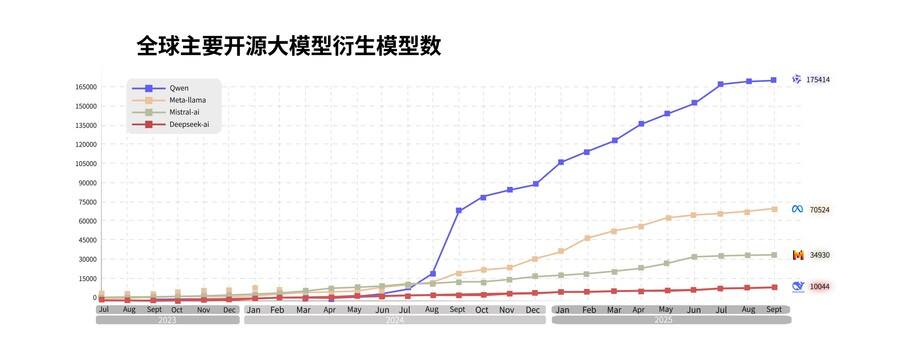
通义大模型已成为全球第一开源模型,也是中国企业选择最多的模型。截至目前,阿里通义开源300余个模型,覆盖不同大小的“全尺寸”及LLM、编程、图像、语音、视频等“全模态”,全球下载量突破6亿次,全球衍生模型17万个,稳居全球第一。超100万家客户接入通义大模型,权威调研机构沙利文2025上半年报告显示,在中国企业级大模型调用市场中,阿里通义占比第一。
模型日均调用量增长15倍,阿里云百炼发布全新Agent开发框架
作为一站式模型服务和Agent开发平台,阿里云百炼也来了重磅升级。大会现场,阿里云发布全新Agent开发框架ModelStudio-ADK,该框架突破以预定义编排方式开发Agent的局限,可帮助企业高效开发具备自主决策、多轮反思和循环执行能力的Agent。使用ModelStudio-ADK,1个小时就能轻松开发一个能生成深度报告的Deep Research项目。随着模型能力的不断提升以及Agent应用的爆发,过去一年,阿里云百炼平台的模型日均调用量增长了15倍。

在框架层面,阿里云ModelStudio-ADK基于通义开源的AgentScope打造,可开发深度研究、硬件代理智能体、复杂检索智能体等应用。该框架还全面支持云端部署和云端组件调用,提供企业级、服务稳定、灵活部署和运行的高代码开发模式,帮助企业和开发者快速实现复杂场景Agent的开发和落地。
在模型层面,阿里云百炼持续上线全新通义千问家族旗舰模型,基于Qwen3系列模型强大的推理能力,可驱动Agent实现更高效的自主规划与决策,推理性能提高50%,决策成功率达到90%。目前,用户可一键调用Qwen、Wan、DeepSeek等200多款业界领先的模型。
在组件层面,面向Agent开发和部署所需的各类组件,阿里云百炼集成了工具连接MCP Server、多模数据融合RAG Server、沙箱工具Sandbox Server、智能记忆存取Memory Server以及支付订阅服务 Pay Server等7大企业级能力。以Pay Server为例,该服务由阿里云百炼和支付宝联合首发推出,是业界首个为企业级Agent提供专业商业化支付通道的服务。目前,阿里云百炼首批上线了基于ModelStudio-ADK开发的DeepResearch、Agentic-RAG、Computer-Use Agent等Agent应用,用户可免费在线体验或下载代码进行二次开发。
大会现场,阿里云百炼还升级了低代码Agent开发平台ModelStudio-ADP,该平台已广泛应用于金融、教育和电商等领域企业,目前,阿里云百炼平台已有超20万开发者开发了80多万个Agent。据介绍,网商银行基于ModelStudio-ADP开发了贷款审核应用,支持合同、发票、营业执照等26种凭证,以及店面门头、餐饮厨房、就餐区、货架商品等超过400种细粒度物体的精准识别,准确率超95%,其任务处理时间从原来的3小时优化至5分钟内。
同时,阿里云Agent Infra重要组件的无影AgentBay迎来重大升级。无影AgentBay是阿里云为Agent量身打造的“超级大脑” ,可动态调用云上算力、存储及工具链资源,大大突破了Agent在本地设备上的算力限制。本次云栖大会,无影AgentBay还全新推出了自进化引擎、自定义镜像、安全围栏、内存状态管理等新能力,并首次展示全新的个人计算产品——无影Agentic Computer,拥有全新的人机交互方式,革命性的“记忆”能力和近乎无穷的云上算力。
AI算力一年增长超5倍,阿里云AI基础设施全面升级
阿里云围绕AI进行了软硬全栈的协同优化和系统创新,已初步形成以通义为核心的操作系统和以AI云为核心的下一代计算机。过去一年,阿里云AI算力增长超5倍,AI存力增长4倍多。

2025年云栖大会现场,全面升级的阿里云AI基础设施重磅亮相,全面展示了阿里云从底层芯片、超节点服务器、高性能网络、分布式存储、智算集群到人工智能平台、模型训练推理服务的全栈AI技术能力。
在服务器层面,阿里云发布全新一代磐久128超节点AI服务器。新一代磐久超节点服务器由阿里云自主研发设计,具备高密度、高性能和高可用的核心优势,可高效支持多种AI芯片,单柜支持128个AI计算芯片,密度刷新业界纪录。磐久超节点集成阿里自研CIPU 2.0芯片和EIC/MOC高性能网卡,采用开放架构,扩展能力极强,可实现高达Pb/s级别Scale-Up带宽和百ns极低延迟,相对于传统架构,同等AI算力下推理性能还可提升50%。

磐久AI Infra2.0 128超节点服务器
在网络层面,阿里云新一代高性能网络HPN 8.0全新亮相。为应对大模型时代对海量数据传输的需求,HPN8.0采用训推一体化架构,存储网络带宽拉升至800Gbps,GPU互联网络带宽达到6.4Tbps,可支持单集群10万卡GPU高效互联,为万卡大集群提供高性能、确定性的云上基础网络,助力AI训推提效。
在存储层面,阿里云分布式存储面向AI需求全面升级。高性能并行文件存储CPFS单客户端吞吐提升至40GB/s, 可满足AI训练对快速读取数据的极致需求;表格存储Tablestore为Agent提供高性能记忆库和知识库;对象存储OSS推出 Vector Bucket,为向量数据提供高性价比的海量存储,相比自建开源向量数据库,成本骤降95%,结合OSS MetaQuery 语义检索和内容感知能力,可快速构建RAG等AI应用。
在AI智算集群层面,智能计算灵骏集群通过多级亲和性与拓扑感知调度设计,基于HPN 网络支持10万卡稳定互联,多级可扩展的架构让每张卡间互联路径更短、带宽更优。灵骏集群面向任务的稳定性设计、故障分钟级恢复能力,有效提高了模型训练任务的集群稳定性。
AI需求爆发也带动了通用算力需求上升,阿里云通用计算全面升级。依托自研的“飞天+CIPU”架构体系,阿里云第九代企业级实例采用英特尔、AMD的最新芯片,在大幅提升算力水平的同时,可为Agent提供稳定、安全、高性能的通用CPU算力。其中,九代AMD实例g9ae提供物理核的规格,性能最高提升67%,尤其适合企业离线数据分析处理、视频转码等高并发场景。
为AI负载提供弹性、调度优化和规模化运行的容器计算,也迎来重磅升级。容器服务ACK新增灵骏节点池,引入模型感知智能路由、多角色推理负载管理、故障自愈等核心功能,自动处理恢复时长缩短了 85% ,模型推理冷启动提速10倍。容器计算服务ACS强化网络拓扑感知调度,任务通信性能整体提升30%,并针对AI Agent场景深度优化,Serverless GPU算⼒开箱即用,支持每分钟15000沙箱的大规模并发弹性,结合安全沙箱、智能休眠与唤醒,实现Agent随需启用、高效响应。
阿里云人工智能平台PAI与通义大模型联合优化,印证了全栈AI的“1+1>2”的效果。在训练层,针对MoE模型,采用统一调度机制、自适应计算通信掩盖、EP计算负载均衡和计算显存分离式并行等优化手段,使得通义千问模型训练端到端加速比提升3倍以上;升级DiT模型训练引擎,通义万相单样本训练耗时降低28.1%;在推理层,通过大规模EP、PD/AF分离、权重优化、LLM智能路由在内的全链路优化,实现推理效率显著提升:推理吞吐TPS增加71%,时延TPOT降低70.6%,扩容时长降低97.6%。
“阿里云正在全力打造一台全新的AI超级计算机,它同时拥有最领先的AI基础设施和最领先的模型,两者可以在产品设计和运行架构上高度协同,从而确保在阿里云上调用和训练通义千问模型时,能达到最高效率。”吴泳铭表示。
截至目前,阿里云运营着中国第一、全球领先的AI基础设施和云计算网络,在全球29个地域设有90个可用区。三方机构Omdia2025年上半年数据显示,中国AI云市场阿里云占比35.8%,超过2到4名总和;在已采用生成式AI的财富中国500强中,超53%企业选择阿里云,渗透率位列第一。未来3年,阿里巴巴将投入3800亿用于建设云和AI基础设施,总额超过过去十年的总和。





