
北京时间8月4日23时,在全球权威 AI 基准测评组织 MLCommons® 正式发布的MLPerf® Storage v2.0存储性能基准测试结果中,深圳市泛联信息科技有限公司(UBIX Technology Co., Ltd.)参与了全部10项场景测试,取得7项世界第一。这一成绩不仅彰显了泛联信息(UBIX)在高性能全闪存储系统领域的技术领先地位,也展现了其产品在支撑大规模AI训练与推理任务中的卓越能力。
MLPerf® Storage v2.0:定义AI存储性能的新标准
MLPerf® Storage v2.0 是由全球权威 AI 基准测试组织 MLCommons® 推出的最新一代人工智能存储性能评测标准,旨在衡量在真实 AI 工作负载下,存储系统对训练与推理流程的支持能力。作为专门面向 AI 时代的数据密集型应用设计的评测套件,MLPerf® Storage v2.0 不仅强调吞吐带宽、IO 吞吐量等传统性能指标,更着重于在大规模并发、海量数据处理、大模型训练、Checkpoint保存及恢复等典型场景中的系统表现。
本次测试吸引了全球 26家顶尖科技企业参与,覆盖存储系统、AI 基础设施及半导体三大核心领域,参与者既包括泛联信息(UBIX)这样的创新力量,也涵盖 IBM、Huawei、HPE、DDN、Intel、Samsung、Micron、Kioxia、Lightbits Labs、H3C、Oracle、Nutanix 等行业标杆企业,充分体现了该基准测试在全球科技领域的广泛认可度与影响力。

本次MLPerf® Storage v2.0参测企业(来源:MLCommons)
MLPerf® Storage v2.0在2023年0.5版本及2024年1.0版本6个训练场景的基础上,增加了4个基于不同规模llama3模型的checkpoint测试场景,覆盖了从样本加载、checkpoint保存与恢复等常见模型训练场景的工作负载,全面测评图像识别、科学计算等领域人工智能应用的存储需求,确保评测结果具有广泛的现实参考意义。
MLPerf® Storage v2.0 针对A100和H100两种GPU分别定义了3D Unet 、ResNet50和CosmoFlow 3个模型下总计6类训练测试场景,从下表中可以看到每个测试场景的模型简介、训练框架及测试条件等关键信息:
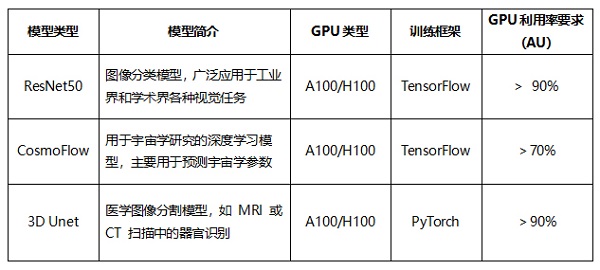
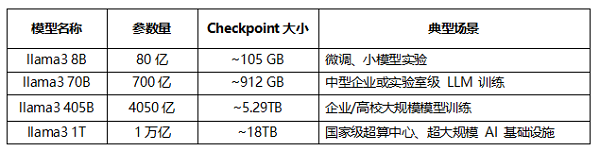
MLPerf® Storage v2.0中新增了4个Checkpoint测试场景,用于模拟 AI 模型训练过程中的模型checkpoint保存与恢复工作负载。这些测试场景聚焦于checkpoint高带宽写入和读取性能,覆盖了不同规模模型训练中常见的I/O模型,从下表中可以看到每个测试场景的参数规模、checkpoint测试数据量和典型场景等关键信息:
同时,为了保证测试结果的准确性和权威性,MLPerf® Storage v2.0制定了极其严格的测试准则,包括:
1. 高 GPU 利用率
·v2.0更加强调在训练任务中存储系统不应成为性能瓶颈:
·ResNet-50和3D UNet测试中,GPU利用率要求 >90%。
·CosmoFlow测试中,GPU利用率要求 >70%。
·在MLPerf® Storage v2.0中,允许使用更大规模的GPU模拟集群,进一步提高了对系统高带宽与低延迟的要求。
2. 严禁缓存优化
·主机侧禁止任何数据缓存行为,以防影响存储系统真实性能评估:
·测试前必须清空缓存(例如,使用 echo 3 > /proc/sys/vm/drop_caches命令清空缓存)。
·测试数据集至少5倍于主机内存容量,确保数据真实从存储中读取。
·每轮测试之间必须重新加载数据,防止隐性缓存。
3. 可重复性与审核机制
·多次执行且连续成功(训练任务5次、Checkpoint任务10次)。
·提交结果需附带完整配置、日志与运行脚本。
·在MLCommons官网公开测试流程与硬件配置。
·所有测试结果均经过官方及参与测试厂家交叉检视。
为了深入理解 MLPerf® Storage 2.0基准测试内容,我们先解释几个核心概念:
Accelerator Number(ACC NUM):模拟测试训练GPU数量,衡量系统处理能力的规模;模拟测试训练GPU数量越多,对存储系统的读写带宽和并发吞吐的压力越大。
Accelerator Utilization(AU):测试过程中 GPU 的平均利用率(百分比),反映存储系统是否能为GPU提供稳定且持续的数据供给。如果利用率低,说明存储性能可能成为瓶颈。
Accelerator Type: GPU类型,表示参与测试的GPU型号/架构,MLPerf® Storage v2.0测试目前支持模拟测试A100和H100两种GPU类型。
Storage System Type:参与测试的存储系统结构和介质类型。MLPerf® Storage v2.0测试中覆盖了以下存储系统类型:
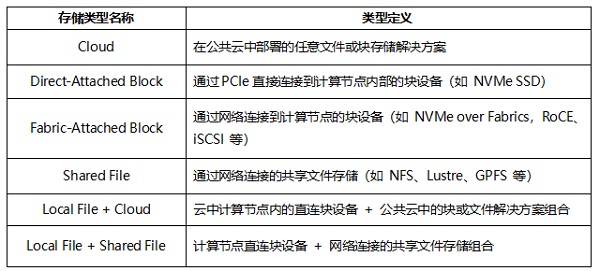
Storage System RU:存储系统所占的物理空间,单位为 RU(Rack Unit,1RU = 1.75 英寸)。注:由于部分Cloud类型的参测厂商未反馈实际使用的存储系统RU数据,因此本文并未将这部分参测厂商的每存储系统RU输出带宽纳入对比。
基于上述指标维度,大家就可以对 MLPerf® Storage v2.0测试中各参测厂商的系统能力进行全面对比,例如:
·在满足官方要求的GPU 利用率下,哪个存储系统能支持更高的GPU数量及更高的业务带宽?
·在相同训练模型下,哪个存储系统的性能密度更高,即存储系统每RU输出的读、写带宽更高?
·在相同checkpoint模型下,哪个存储系统的性能密度更高,即存储系统每RU输出的读、写带宽更高?
·更高的性能密度,意味着相同节点数和机架空间下,系统可以支持更多 GPU 计算节点的训练任务。
实力领跑!泛联信息包揽MLPerf® Storage v2.0七项世界第一
泛联信息(UBIX)作为国内唯一全面参与 MLPerf® Storage v2.0 全部10项测试场景的创新型AI存储厂商,在众多国际领先参测企业中脱颖而出,斩获其中7项世界第一的卓越成绩。同时,在所参与的测试项目中,泛联信息(UBIX)相较于1.0版本的核心测试指标,普遍实现了两倍以上的性能提升,充分展现了其在AI存储领域的技术实力与持续创新能力。
泛联信息(UBIX)使用自研独立知识产权的UbiPower18000全闪存储产品参与测试。本次测试环境基于泛联信息战略合作伙伴新疆银丰智能算力技术有限公司提供的优质AI算力、网络平台搭建。平台整合高品质的AI算力资源与高速网络架构,为本次测试提供了稳定可靠的基础测试环境。在存储介质方面,泛联信息选用了大普微 Roealsen® R6系列PCIe Gen5 NVMe SSD,该产品在整个测试过程中保持了超低的读写时延以及稳定的读写带宽,为高负载、密集型训练场景提供了强有力的支撑。
本次UbiPower 18000测试环境包含3节点组成的UbiPower 18000分布式集群(每节点配置了16块大普微Roealsen R6100 15.36TB NVMe SSD以及4张英伟达NVIDIA ConnectX-7 400Gbps IB网卡)、16台GPU算力服务器以及一台英伟达400G IB交换机,测试环境网络拓扑如下图所示:
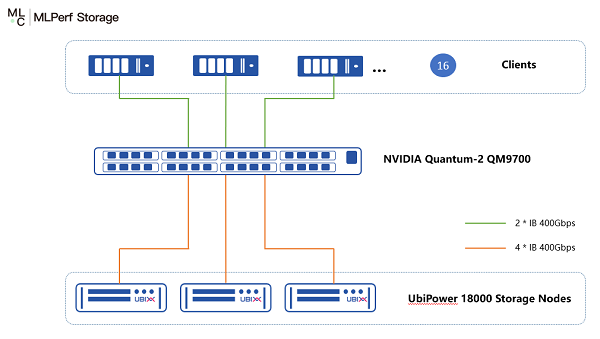
UbiPower 18000测试拓扑图
接下来,我们将对泛联信息(UBIX)UbiPower 18000分布式全闪存在本次测试中的详细性能数据进行深入解析,全面剖析其在智算训练业务测试场景中的表现。让我们一同见证这款面向智能计算场景全新设计的创新型 AI 分布式存储系统所带来的强劲性能冲击与突破性价值。
ResNet50模型测试数据解析
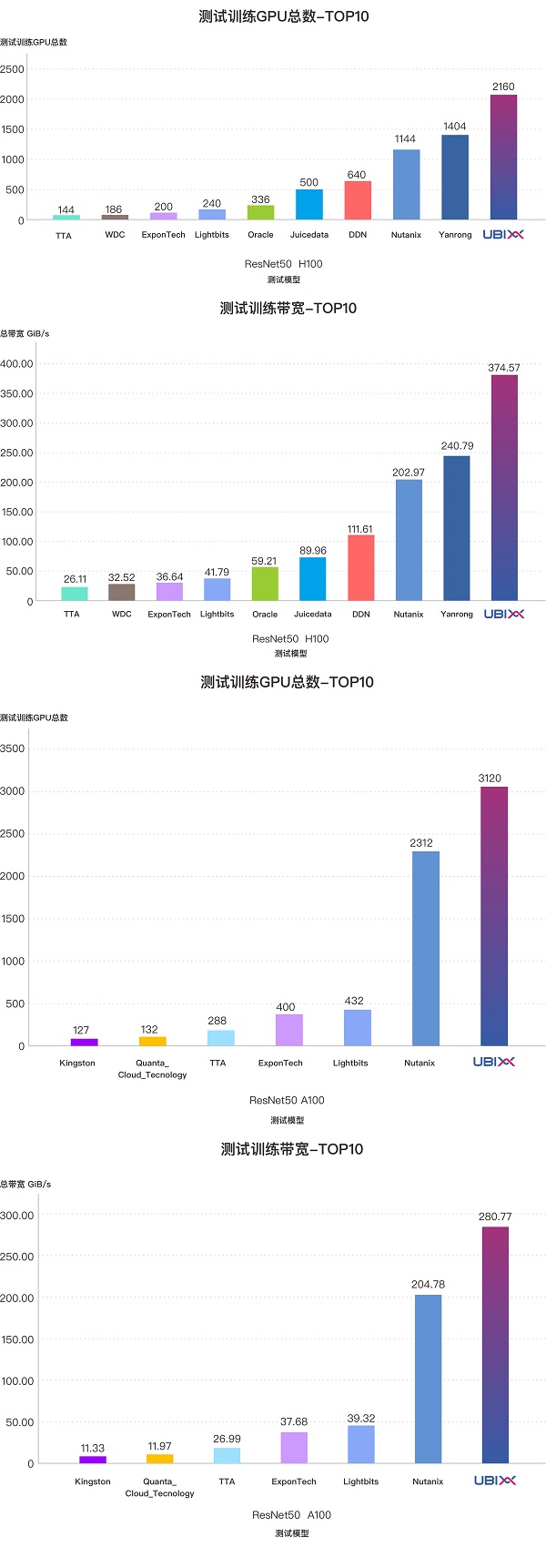
在 ResNet-50 模型模拟测试中,测试系统模拟图像分类任务,使用生成的 ImageNet 风格图像数据集,并通过多并发读取的 I/O 模型进行评估。在该测试场景下,仅由3个 2U存储节点组成的UbiPower 18000分布式存储系统,成功支撑了模拟训练中多达 2160张H100 GPU的数据吞吐需求,GPU利用率持续保持在90%以上,系统稳定带宽达到374.57GiB/s,对应每存储系统RU的带宽高达62.43 GiB/s。同时,该系统成功支持了3120张A100 GPU的模拟训练需求,依然保持GPU利用率超过 90%,系统稳定带宽为280.77GiB/s,对应每RU带宽高达46.8GiB/s。
在本测试模型下,UbiPower 18000无论在支持的GPU数量、系统总带宽,还是每存储RU带宽,均为所有参测厂商中的最高值,充分展现了其在处理大规模数据集场景中的卓越能力。同时,在紧凑的空间占用下,提供了更高的性能密度,证明UbiPower 18000能在相同节点数和机架空间下,支持更多 GPU 计算节点的高效训练任务,具备极强的可扩展性与部署效率。
CosmoFlow模型测试数据解析
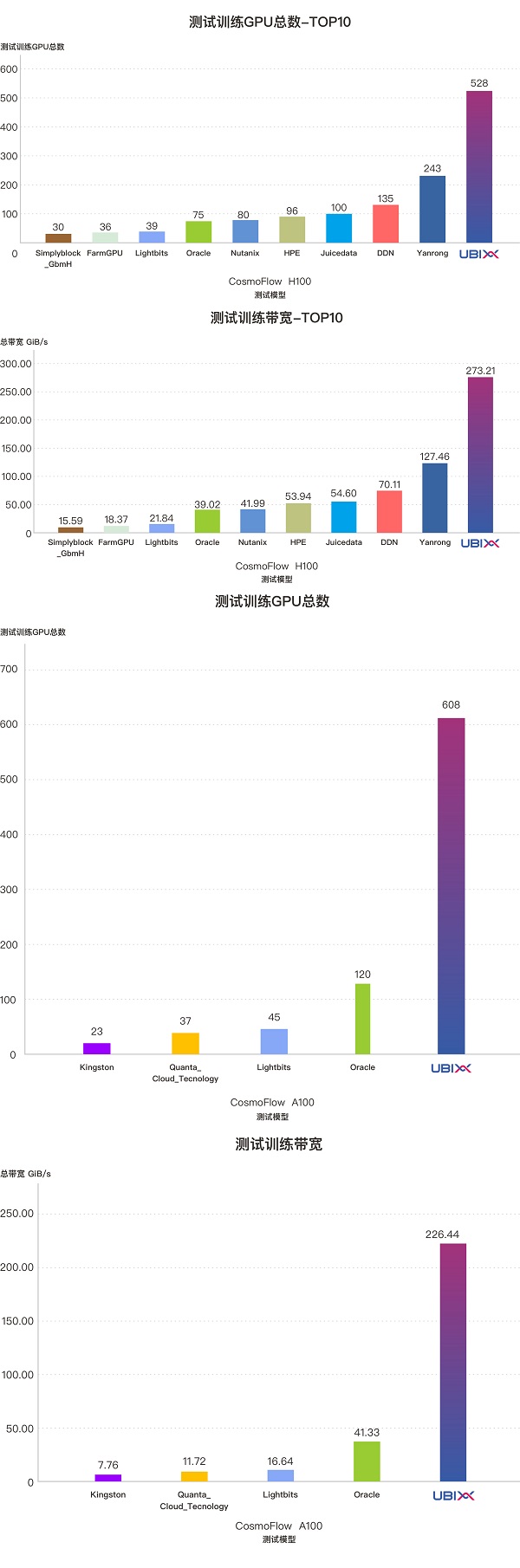
该测试模型模拟的是科学计算类AI工作负载,测试模型根据计算节点内存容量动态生成2.6MB大小的科学模拟数据文件,并采用并发读取的I/O模型进行训练评估。泛联信息(UBIX)所使用的测试客户端内存配置为512GB,在此基础上,测试程序共生成约1500多万个科学模拟数据文件,在本项测试中数据集规模在所有参测厂商中也是最大的。在如此大规模的数据集条件下,UbiPower 18000分布式存储系统依然展现出强劲的性能表现:
·成功满足了528张H100 GPU的模拟训练带宽需求,提供高达273.21 GiB/s 的稳定带宽,折合每存储系统 RU 带宽为45.54 GiB/s;
·成功满足了608张A100 GPU的模拟训练带宽需求,稳定带宽达到226.44 GiB/s,每存储系统 RU带宽达37.74GiB/s。
在该测试模型下,UbiPower 18000在支持的GPU数量、系统总带宽及每存储系统 RU带宽等核心指标方面,均为所有参测厂商中的最高水平。即便在更大规模的数据集和更高的 I/O 压力下,该系统依然支持远超其他厂商的GPU数量与集群带宽,充分体现了UbiPower 18000在科学计算类AI训练负载场景下的优异性能和出色的可扩展能力。
3D U-Net模型测试数据解析
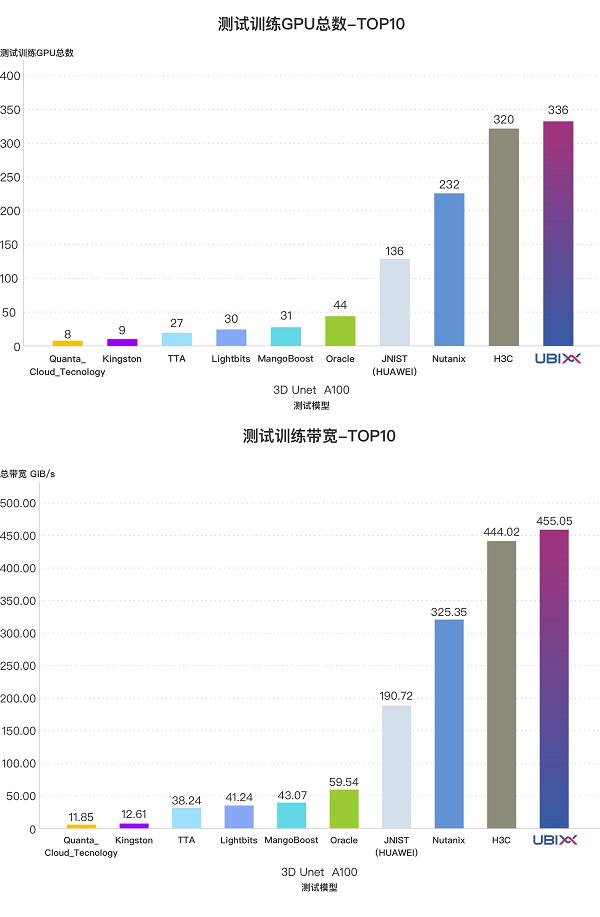
该测试模型模拟医学影像分割任务的典型工作负载,主要用于评估存储系统在混合读取模式及中等文件大小(约140MB)场景下的性能表现。在本模型下,UbiPower 18000 存储系统也展现出了卓越的性能能力:
·面向336张A100 GPU的模拟训练任务,系统成功满足了高强度的数据吞吐需求;
·在训练过程中,GPU利用率稳定保持在90%以上;
·系统实现了高达455.05 GiB/s的稳定带宽输出;
·折合每存储系统RU带宽达到75.84GiB/s。
在该测试模型下,UbiPower 18000 所支持的 GPU 数量、总带宽及每存储系统 RU 带宽均为所有参测厂商中的最高水平,充分展示了其在医学影像类AI负载下的领先性能与强大适应性。
Llama3-405b模型测试数据解析
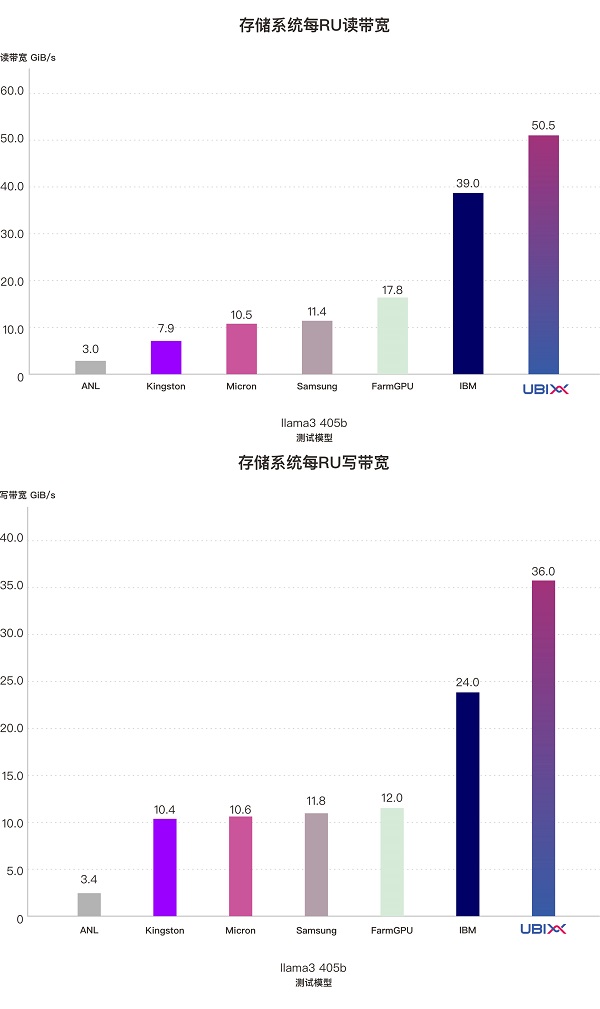
Llama3 405b模型模拟的是企业或高校在进行大规模模型训练时,多个GPU服务器同时进行checkpoint数据读写的典型场景。在MLPerf® Storage v2.0测试中,该模型模拟了512路并发写入、并发读取,每轮总数据量达5.29TB的checkpoint数据,重点评估存储系统的读、写带宽能力以及大规模计算集群下的并发访问性能。
在该测试模型中,由3个2U存储节点组成的UbiPower 18000存储系统表现出色,每个存储系统RU稳定输出50.5GiB/s的读带宽和36GiB/s的写带宽,其读、写带宽密度在所有参测厂商中均为最高。
Llama3-1t模型测试数据解析
Llama3-1t模型模拟的是超大规模AI基础设施场景下,多个GPU服务器并发进行 checkpoint的读写操作。该模型模拟了1024 路并发写入和读取,每轮总量高达18TB的checkpoint数据,进一步提升了对存储系统并发访问能力和读写带宽的考验。
在此测试中,由 3 个2U存储节点组成UbiPower 18000存储系统,每个 RU 稳定输出54.7GiB/s的读带宽和36.3GiB/s的写带宽,再次刷新了参测厂商中的读写带宽密度记录。
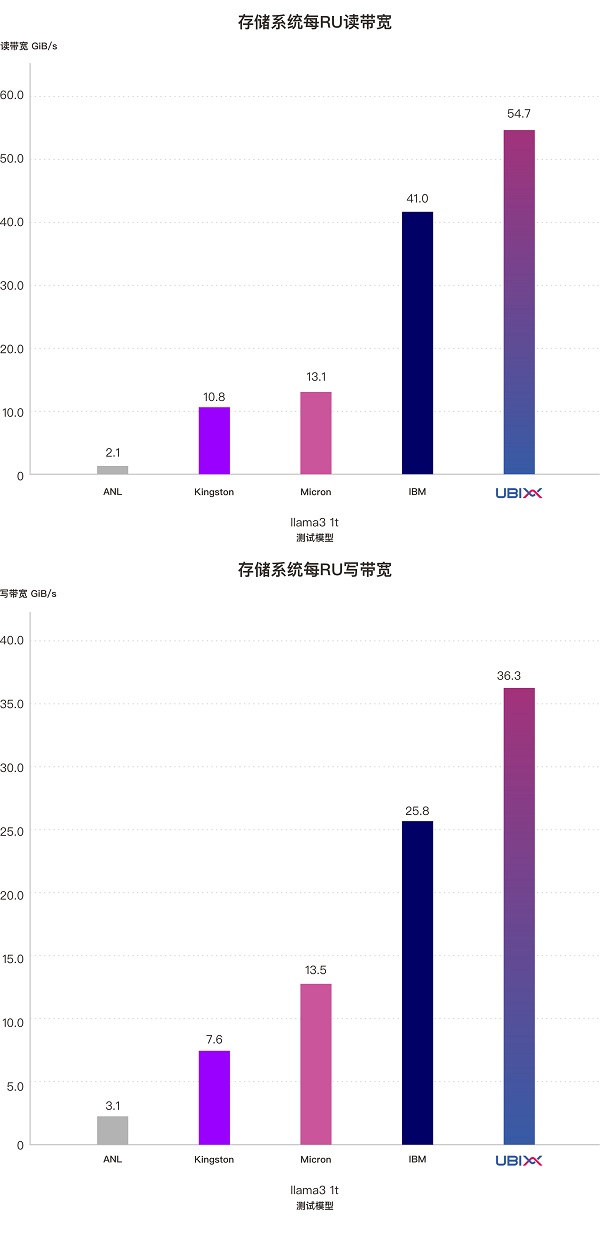
从 Llama3-405b与Llama3-1t 两个checkpoint模型的测试结果来看,在高并发读写业务场景下,UbiPower 18000存储系统展现出强大的带宽吞吐能力:
·系统读带宽突破328GiB/s,写带宽超过218GiB/s
·每节点稳定提供 100 GiB/s以上的读带宽、72 GiB/s以上的写带宽
这些数据充分证明了UbiPower 18000在大模型训练过程中checkpoint保存与加载场景下的优异性能表现。同时,随着节点数量的线性扩展,该系统还能够持续提升集群的整体读写带宽,全面满足大规模 AI 训练对存储系统的极致带宽需求。
泛联信息(UBIX):面向智算时代的存储创新者
作为一家专注于 AI 存储产品与解决方案的新兴厂商,深圳市泛联信息科技有限公司(UBIX Technology Co., Ltd.) 通过在存储介质应用、系统架构及软件实现等方面的持续创新,成功研发出拥有自主知识产权的高性能分布式文件系统 UBIXFS。
其核心技术包括:
·全固态分层资源池架构
·高并发、低时延分布式元数据服务集群
·基于RDMA网络的多链路动态聚合高速传输协议
·CSN资源虚拟化及统一调度
上述创新显著提升了存储系统整体性能,有效支撑智算、超算场景对存储系统的严苛需求,成为推动 AI 技术发展与落地的关键支撑力量。
目前,泛联信息(UBIX)创新AI存储产品已在多个超算中心和智算中心实现商用部署,广泛应用于数据预处理、海量数据访问、大规模checkpoint读写等关键场景,并在科研、高性能计算(HPC)、以及文本、图像、视频、多模态大模型训练等任务中展现出优异的性能表现。
展望未来,泛联信息将持续深耕 AI 存储领域,围绕高性能、高可靠性、智能化三大方向不断加大研发投入,持续优化系统架构与软件能力,推出更多面向大模型训练、智算与超算中心的领先产品与解决方案,助力全球用户高效应对 AI 时代的存储挑战。





