
自OpenBMB开源社区成立以来,OpenBMB践行“让大模型飞入千家万户”的理念,开发模型全流程加速系统以高效支持大模型的预训练、微调、应用和推理,并发起百亿大模型训练直播项目CPM-Live。
终于!CPM-Live 第二阶段的进度条终于拉到了100%,我们迎来了CPM-Live第二个里程碑:CPM-Bee 开源发布!

全新升级,CPM-Ant 蝶变 CPM-Bee
CPM(Chinese Pretrained Model) 系列大模型是我们团队自研模型,其中包括国内首个中文大模型 CPM-1、高效易用大模型 CPM-2、可控持续大模型 CPM-3 等。最新的百亿大模型训练直播项目 CPM-Live 的计划书在2022年5月26日发布,第一期模型 CPM-Ant 的训练在2022年5月29日正式启动,并于2022年9月16日圆满发布报告。
作为 CPM-Live 的第二期模型,CPM-Bee 在2022年10月13日开启训练,在基础能力和性能表现上都在 CPM-Ant 的基础上进行了全新升级。CPM-Bee 一网打尽多种能力,可以准确地进行语义理解,高效完成各类基础任务,包括:文字填空、文本生成、翻译、问答、评分预测、文本选择题 等等。考虑到用户使用模型的易用性,我们在预训练阶段将模型的输入输出设计成了 JSON 结构化形式,用户只需调整不同任务字段,就可以完成各类任务。
"文本生成": {"input": "今天天气很好,我和妈妈一起去公园,<mask>", "prompt": "往后写两句话", "<ans>": ""}"翻译": {"input": "北京是中国的首都", "prompt": "中翻英", "<ans>": ""}"评分预测": {"input":"之前多次聚餐都选择这里,有各种大小的包房同时能容纳很多人,环境好有特色还有表演,整体聚餐氛围一下被带动起来。现在由于炭火改成了电烤羊,口感真的不如从前,不过其他菜品都还是不错,烤羊剩下的拆骨肉最后还能再加工一下椒盐的也很好吃。","question":"评分是多少?(1-5)","<ans>":""}"选择题": {"input": "父母都希望自己的孩子诚实、勇敢、有礼貌。要想让孩子成为这样的人,父母首先得从自己做起,要是连自己都做不到,又怎能要求孩子做到呢?", "options": {"<option_0>": "少提要求", "<option_1>": "降低标准", "<option_2>": "自己先做好", "<option_3>": "让孩子拿主意"}, "question": "教育孩子时,父母应该:", "<ans>": ""}
CPM-Bee 是一个 完全开源、允许商用 的百亿参数中英文基座模型。它采用 Transformer 自回归架构(auto-regressive),使用万亿级高质量语料进行预训练,拥有强大的基础能力。CPM-Bee 的特点可以总结如下:
- 开源可商用:OpenBMB 始终秉承“让大模型飞入千家万户”的开源精神,CPM-Bee 基座模型将完全开源并且可商用,以推动大模型领域的发展。如需将模型用于商业用途,只需企业实名邮件申请并获得官方授权证书,即可商用使用。
- 中英双语性能优异:CPM-Bee 基座模型在预训练语料上进行了严格的筛选和配比,同时在中英双语上具有亮眼表现,具体可参见评测任务和结果。
- 超大规模高质量语料:CPM-Bee基座模型在万亿级语料上进行训练,是开源社区内经过语料最多的模型之一。同时,我们对预训练语料进行了严格的筛选、清洗和后处理以确保质量。
- OpenBMB大模型系统生态支持:OpenBMB 大模型系统在高性能预训练、适配、压缩、部署、工具开发了一系列工具,CPM-Bee 基座模型将配套所有的工具脚本,高效支持开发者进行进阶使用。
- 强大的对话和工具使用能力:结合OpenBMB 在指令微调和工具学习的探索,我们在 CPM-Bee 基座模型的基础上进行微调,训练出了具有强大对话和工具使用能力的实例模型,现已开放定向邀请内测,未来会逐步向公众开放。
🔗 Github地址 https://github.com/OpenBMB/CPM-Bee
🔗 Hugging Face地址 https://huggingface.co/openbmb/cpm-bee-10b
百炼千锤 ,零样本评测独占鳌头
我们对 CPM-Bee 基座模型进行了全方位的中英文能力评测。在中文的 Zero-CLUE 评测基准上,CPM-Bee 可以大幅超越其他模型,稳居中文大模型第一。
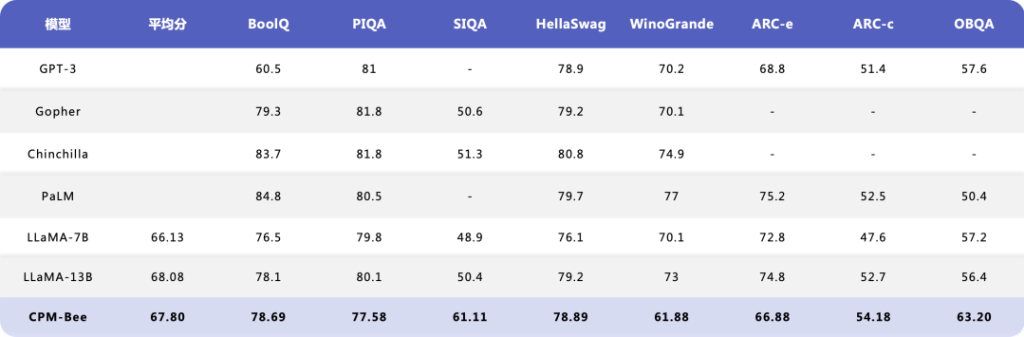
在英文评测基准上,CPM-Bee 也 展现出了和开源模型 LLaMA 相当的效果。
使用CPM-Bee提供的API 与 OpenBMB 和 THUNLP联合自研的Decoder Tuning(ACL 2023)技术,可以在 不访问和修改模型参数的情况下大幅提高下游任务的性能!

生态支持 ✨ 微调压缩部署一应俱全
—基于 OpenBMB 的大模型生态系统,我们在训练 CPM-Bee 的过程中实现了全流程高效。同时提供了训练(基于 BMTrain)、微调(基于 OpenPrompt 和 OpenDelta)、外部工具使用(基于 BMTools)、模型压缩(基于 BMCook)低资源推理(基于 BMInf)的全套脚本,可以协助开发者快速上手和使用 CPM-Bee。
基于高效微调工具 OpenDelta,我们给出了两种微调方案:全参数微调和增量微调,可以将 CPM-Bee 适配到各类下游场景中。
基于高效压缩工具 BMCook,我们对原始的 CPM-Bee 基座模型进行压缩,提供了 10B、5B、2B、1B 四种大小的 CPM-Bee 模型来适应各种不同的场景:
| 模型 | #Attn.层 | #FFN层 | Attn隐状态维度 | FFN隐状态维度 |
| CPM-Bee-10B | 48 | 48 | 4096 | 10240 |
| CPM-Bee-5B | 19 | 24 | 4096 | 10240 |
| CPM-Bee-2B | 19 | 24 | 2048 | 5120 |
| CPM-Bee-1B | 19 | 24 | 1280 | 1024 |
对于压缩后的 CPM-Bee,普通的消费级显卡即可完成快速推理,不同大小的模型所占用的推理资源如下:
| 模型 | 推理内存占用 | 硬件需求 |
| CPM-Bee-10B | 20GB | RTX3090(24 GB) |
| CPM-Bee-5B | 11 GB | RTX3090(24 GB) |
| CPM-Bee-2B | 6.7 GB | GTX 1080(8 GB) |
| CPM-Bee-1B | 4.1 GB | GTX 1660(6 GB) |
OpenBMB 始终坚守初衷,致力于打造卓越的大规模预训练语言模型库和相关工具。基于工具平台和模型库,我们在建设大模型开源生态的同时,也积极促进大模型的落地与广泛应用。
依托强大的开源基座模型 CPM-Bee,我们期待世界上涌现出更多精彩的大模型和大模型驱动的产品应用。人工智能的大模型时代正在加速行进!





