
以ChatGPT为代表,布局人工智能大模型已成为世界性趋势,大模型时代正在加速到来。大模型发展背后,数据科学技术不断推动着人工智能的发展,大模型的发展也带动数据科学技术走向新未来。本文将从数据科学技术发展历程出发,探讨数据科学技术在实施过程中面临的挑战,并分析其未来发展趋势。
数据科学技术发展溯源
数据科学的概念最早出现于1962年,美国数学家John Tukey提议用数据科学(Data Science, Datalogy)来替代计算机科学,认为数据科学是数据分析的未来。
在1974年,Peter Naur 发表了《计算机方法简明调查》,调查了各种应用程序中的数据处理方法,第一次明确定义了数据科学是“处理数据的科学”。此后,计算机科学家和统计学家开始关注如何利用计算机技术处理大量的数据。
随着计算机技术的发展和数据量的不断增长,在20世纪90年代,数据科学技术经历了爆发式的发展,诸如数据挖掘、数据仓库等技术概念应运而生。直到现在,数据科学的概念和范围也在持续演变。
当前,维基百科将数据科学定义为“一门利用数据学习知识的学科”。它的目标是从数据中提取输入价值的部分生产数据产品,其中最典型的代表就是各类人工智能的应用。
实际上,数据科学交叉融合了诸多技术,包括数学、统计、机器学习、数据仓库以及高性能计算等关键技术。尤其是将计算机科学中的数据处理技术和数学中的机器学习技术融合,是数据科学典型的特征。
数据处理与机器学习的关系
从上述关系图可以看出,在计算机方面数据科学所涵盖的核心技术是数据处理和机器学习,不妨通过二者发展历程来探寻其关系。
自2016年AlphaGo横空出世起,大众对人工智能的认知达到了前所未有的广度和高度,传统产业对智能升级和转型的热情也空前高涨。再到2022年底ChatGPT的发布,使得更为广泛的大众深刻感受到人工智能对日常生产生活的影响。
其实,当前主流人工智能技术中所采用的算法,几乎都是上世纪八九十年代或更早前被提出的。以AlphaGo为例,其采用的强化学习、深度学习、蒙特卡洛搜索树都是上世纪被提出来的。可以说,在上世纪70年代至90年代,人工智能经历了漫长的“黑暗期”,多项研究进展缓慢。
通过将大数据技术发展历程图和人工智能技术发展历程图对照,可以看到从1960年开始,数据管理的需求逐渐增长,从二十世纪九十年代到进入二十一世纪,数据库技术持续蓬勃发展,在2005年Apache基金会推出大数据处理框架Hadoop,助力企业更高效地处理和存储海量数据,为数据科学的发展奠定了基础。
总体来说,数据形式和数据量的变化,推动了数据处理和机器学习的进化:数据量的增加催生了更为先进的数据处理技术,数据处理技术的成熟使得机器学习的发展成为可能。
实施数据科学面临的挑战
传统的数据科学家会使用Python作为工具,而Python的数据科学栈三大底座分别是NumPy, Pandas和SciPy。其中NumPy用来做数值计算,包括最基础的数据结构。Pandas在NumPy之上,通过各种API来对数据进行分析操作,SciPy则负责科学计算。在三大底座之上,还有丰富的机器学习和可视化的函数。
此套数据技术栈组合的益处在于使用广泛,高度标准化;上手成本低,容易为初学者和学生入门;和语言结合紧密,能用Python来组织函数调用。但以Python为基础的数据科学技术栈问题也很明显,它们都是单机的数据库,不能处理很大的数据量。
在数据量爆炸式增长、数据来源多样、数据实时性要求高的当下,显然使用Python的数据库不能很好地解决实际中遇到的问题,因此往往需要引入大数据的技术栈。
主流的大数据技术包括Hadoop, Spark, Flink, Kafka等,虽然都支持多语言,但是学习曲线比较陡峭,也需要用户对系统本身有足够的了解。因此,实施数据科学项目时,通常由数据科学家用Python完成小量数据的分析、处理、建模,将数据处理的部分交给数据工程师,由数据工程师将数据处理的逻辑转化为大数据技术的方法,再将处理好的大数据交还给数据科学家。但由于两者使用的技术不同,技能背景不同,导致沟通配合成本较高,应用落地难。
而在大模型快速发展的当下,除了提供极速的大数据分析处理能力外,如何为模型服务提供高质量的数据,从而提升大模型响应速度并降低算力消耗,也是值得研究的方向。
数据科学技术新趋势
面对以上挑战,数据科学技术也迎来一些新的发展趋势。
In-DBMS analytics
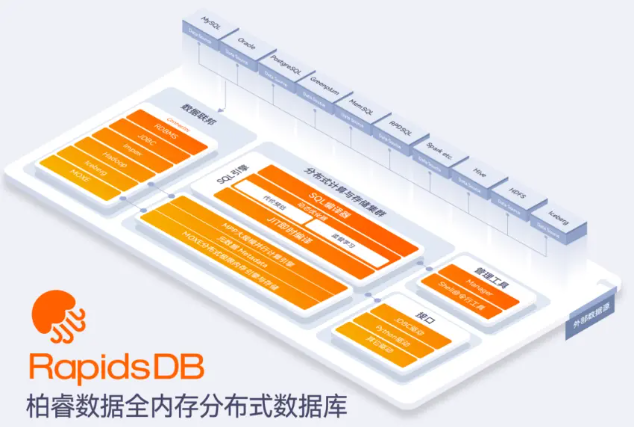
为应对大模型时代越来越大的数据量,最简单的方式就是Scale Up,利用更多的核和更好的硬件,如GPU、FPGA等;另外一个方式是Scale out, 利用分布式的方式,例如Ray、Dask等。而结合Scale up和Scale out,可以构建一个大规模的、更好的硬件集成,柏睿数据的全内存分布式计算引擎RapidsDB即是如此,搭载了针对引擎的FPGA加速芯片,为大数据场景提供一站式的数据科学解决方案,满足用户对大数据存储、分析、建模的全部需求。
MLOps
解决大数据技术和人工智能技术不统一的方法,其中一个便是通过工程化的方式提高数据科学项目落地的效率。人工智能研发运营体系(MLOps) 作为 AI 工程化重要组成部分,其核心思想是解决 AI 生产过程中团队协作难、管理乱、交付周期长等问题,最终实现高质量、高效率、可持续的 AI 生产过程。柏睿数据RapidsAI是一系列用于构建人工智能应用的产品组合,包括数据智能分析诊断平台、特征库、AIWorkflow和模型集市,覆盖了在人工智能应用开发全流程的工作,包括数据获取、数据探索、数据处理、特征工程、模型开发、模型评估、模型部署应用和模型监控维护,提升数据科学开发落地的工作效率。
向量数据库
在如ChatGPT此类大语言模型的预训练、微调以及条件生产过程中,需要利用词嵌入的方法,将单词转化为具有语义信息和连续表示的向量。这些词嵌入向量使得模型能够更好地理解单词之间的关系、建模上下文信息,并生成连贯的文本或理解上下文的含义。
在大语言模型的应用场景中,例如问题回答和知识检索等应用场景,可以使用向量数据库存储大规模的知识库,通过将问题和知识库中的内容转化为向量表示,并计算向量之间的相似度,最大限度地减少数据检索所需的时间,系统可以更快地响应并提供更好的用户体验。使用嵌入(以及文档索引)和向量存储的另一个优点是,它更易于实现迁移学习等技术,以实现更高效的微调和更好的性能。
未来展望
根据Gartner技术报告分析,In-DBMS Analytics库内分析技术将是数据库技术主流发展趋势;未来,从数据产生、集成、建模、执行、管理均在同一平台完成,实现数据和AI技术的融合。
在过去,由于数据管理技术的发展,带动了AI技术的发展,但随着ChatGPT此类大语言模型的成熟,人工智能技术也会反哺数据管理领域。一方面,通过ChatGPT等AI模型赋能,提高代码的编写效率,加速软件开发迭代;另一方面,改变交互方式,降低使用门槛,让计算机语言不再成为数据科学家工作的障碍。







