
10月26日,由北京四维纵横数据技术有限公司自主研发的超融合数据库YMatrix 5.0正式发布。
不同于传统以及专用数据库产品,YMatrix实现了“一库多用”,可以支持各类传统及新兴数据场景,广泛支持多种数据类型,包括关系、时序、GIS、JSON、文本、图片数据等,也能满足包括机器学习、高级查询在内的全场景数据管理和复杂分析需求。
YMatrix创始团队曾在全球排名Top3的Greenplum工作多年,是分析型数据库领域少见的世界级完整建制团队。创始人姚延栋所带领团队有大量服务全球500强企业的经验,对企业级数据库产品的需求、研发和应用有深刻理解。
从第一行代码到5.0版本,仅两年时间,公司已获得累计近2亿元人民币的4轮融资,股东包括晨山资本、顺义产业基金、某头部云厂商、东方富海、中科创星、清华启迪等。
此次产品发布会上,YMatrix CEO 与创始人姚延栋分享了超融合数据库的发展趋势,以及万物智联场景下数据库的最佳形态。另外,杭州自动化技术研究院院长徐赤、小米智能制造软件产品部负责人封杨博士、三一重工泵送研究院泵诵云平台大数据负责人褚凤天,也参与了此次发布会,分别从工厂数字化、智能制造和工业互联网、智能设备运维等不同应用场景角度,分享了他们对下一代数据库的需求和理解。
专用数据库 vs. 超融合:下一代技术栈的竞赛
下一个时代,是万物智联和数智化转型的时代。那么,作为数字基石之一的数据库应该是什么样的?
过去20年间,互联网飞速发展,为了应对不断升级、升维的数据环境,涌现了很多优秀的产品,或是功能强大,或是性能惊艳,或是易用性极佳。然而,用户选择时,功能、性能、易用性似乎构成了一个”不可能三角”,总是需要权衡和取舍。

为了应对新增的需求,用户不得已的选择是不断叠加,先一个个叠加新的专用数据库产品,再叠加运维不同产品的专业化团队。最终造成的困境,杭州自动化技术研究院院长徐赤将其总结为“难、混、乱、散”:
每出现一个新需求,就要叠加一个新产品,从选型、试点到验证,少则一两个月,多则半年甚至一年,堪比“炼狱”。由于目标混沌、路径混乱、缺少核心系统,数据总是呈现散乱并难以整合的状态。
最后导致的直接结果就是“用户成本高“、”需求难以满足、痛点永远存在”。

对此,徐赤在发布会上表示,在过去以专用类产品为主流的市场中,服务商忙着生产孤岛、企业忙着购买孤岛,工程师们忙着打通孤岛,循环往复,永无止境。而且,这样强行耦合的结构,牵一发动全身,非常不稳定。
YMatrix创始人姚延栋介绍,作为数据库人,成立团队的初心,就是想从用户需求出发,做一款通用性强的产品,而不是和大多同行一样,开发专用数据库产品,继续一个问题接一个问题,只解决当下问题。
据了解,在国际市场上,类似YMatrix这样具备 “超融合”特性的产品,已经成为了近年的研发趋势。
海外市场,Snowflake 和 Databricks 曾先后提出 “one data platform”理念;传统数据库头把交椅的Oracle也在走向融合方向;对复杂新兴场景需求更加熟悉的时序数据库大佬 InfluxDB 和 TimescaleDB,也先后启动了新一代融合型数据库的研发,对比大厂采取了更为激进的策略。
国内市场中,YMatrix率先提出超融合数据库概念,在2020年完成了相应产品的研发;目前也有少数创业公司试水,从专用产品出发,研发符合新一代融合理念的产品。
如何定义一款优秀的“超融合”数据库产品?
首先,回到用户需求。
小米智能制造软件产品部负责人封杨博士是这么定义的:以工业互联网场景为例,其本质是以“数据”为核心要素,企业实现全面连接。企业经营者的核心诉求,是如何最大化利用数据智能,为企业经营带来看得见的价值。
再向上一层,则是跨过每个企业的微观需求,在垂直产业或多个产业交叉的维度,构建起全要素、全产业链、全价值链融合的新制造体系和新产业生态。
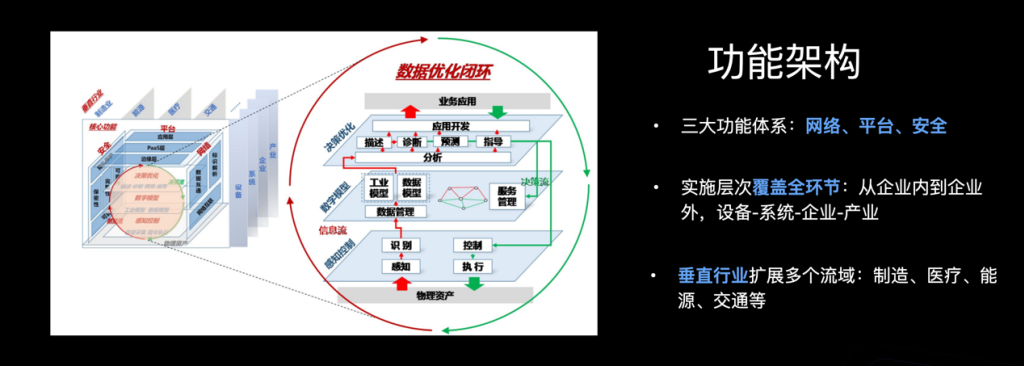
为了实现这个目标,需要搭建一个闭环的数据链条。在企业内到企业外,从采集、诊断、预测到智能决策,实现全环节覆盖。依赖优化后的结果,可以更及时、更准确的做商业决策,比如确定一个月后生产什么,需要提前备好多少原材料,技术工艺能怎么调优,等等。
封杨博士介绍,从企业级用户的角度来看,代表最先进生产力的产品,首先应该是极致简单的,最好是一个顶N个,能降低企业的财务、人力、学习成本;其次,要好用易用,因为制造场景采集的数据类型五花八门,不同数据类型的交叉分析、应对业务诉求的复杂分析也是层出不穷。
对此,姚延栋进一步解释,“用户并不关心什么TP、AP、湖仓、批流,他们想要的就是一个强大的数据库,能接入所有数据,做得了各种各样的分析。有数据就可以往里写,想用的时候随时用,允许他们把精力放在数据价值上,而不是数据库上。所以,行业内曾热烈讨论的湖仓之分、批流之分,只会是阶段性产物”。
“使用YMatrix,用户只需要做一次选型,运维一个产品,就可以支持所有数据类型,满足所有可能的需求。每次新需求出现时,只需要考虑在YMatrix中怎么实现。这大大降低了选型成本和开发运维成本”,姚延栋介绍。

“企业内很难有精通不同产品的通才,所以厂商应该把复杂度处理掉,把简单应用给到我们用户,这样既省钱,又省心省力”,封杨博士表示在应用YMatrix的超融合产品后,相当于实现了“无缝集成”,仅仅需要管理“1个极致轻松的数仓建设团队+1个极致专注的工业算法团队”。
三一重工泵送研究院泵诵云平台大数据负责人褚凤天表示,“使用高效的产品,可以大量释放出精力和创造力,让团队聚焦工厂运营、设备管理、工艺调优等更有价值的工作”。
“以常见的堵管故障为例,以前总是很难明确堵管的真实原因,现在可以在库内通过批量的算法,在采集到的工矿数据上,更好的定位原因,提升服务水平,降低客户投诉率”,褚凤天介绍,“在尝试从制造企业向服务型企业升级的过程中,数据能力会是重点之一,直接决定了服务水平和盈利水平” 。
性能突破,是超融合价值放大的必要前提
在数据库行业,性能似乎是一个永远有吸引力的话题。
性能数据直观,谁高谁低,谁强谁弱,一目了然。最近,很多数据库厂商都开始性能打榜打擂。姚延栋对此表示,“这是好事,说明技术在进步。但是,仅仅在某个场景下实现性能快20%-30%,甚至1倍,是很难赢得客户的。客户需要的是铁人三项,甚至是十项全能” 。
“在YMatrix团队内部,我们关注全场景性能表现,包括写入能力、时序查询能力、单表OLAP分析、多表关联OLAP分析、Machine Learning性能以及 OLTP 能力等诸多方面”,姚延栋介绍,“性能加持下的超融合,才是真正的超融合,才能给用户提供价值” 。
目前,YMatrix在生产场景下的写入速度实现了1.52 亿数据点/秒。通常一个工厂的数据点大概在10万点以内,1.52亿是该场景规模的1500倍,哪怕是对写入能力要求最高的时序场景,也可以轻松满足其高并发、低延迟的写入需求。

此外,对比时序数据库独角兽TimescaleDB,查询耗时是YMatrix的5.1倍;对比知名OLAP数据库产品Clickhouse,YMatrix在SSB基础测试上快27%;对比MPP数据库主流厂商Greenplum,YMatrix在多表关联分析场景上实现了数倍的性能提升;对比全球流行的开源大数据平台Spark,YMatrix在机器学习场景上的性能是其8倍;在Intel实验室的TPC-B 国际标准测试中,YMatrix主键查询tps高达160万,数十倍于绝大多数产品。
对于性能优化的重要性,三一重工褚凤天表示,“最直接的体现就是提高运行速度,我们可以更快速的反应,大大提高了运维团队的效率”。
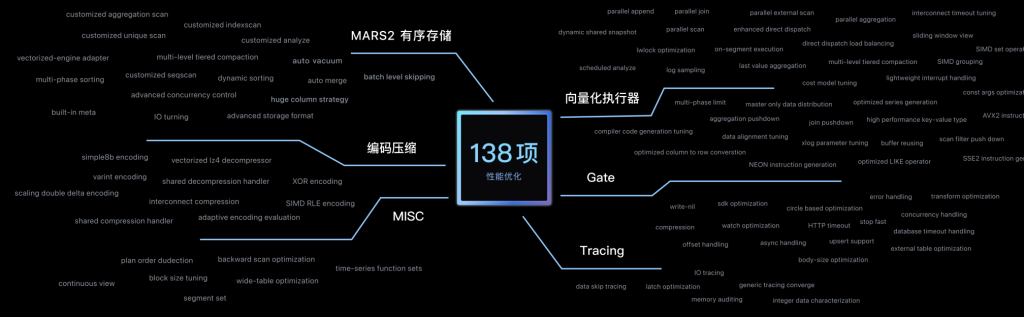
姚延栋介绍,此次发布的YMatrix 5.0版本,还包含了多至138项的性能优化,特别是针对写入和分析等重点领域,进行了深度的指令级优化。
在易用性方面,YMatrix设计了用户体验极佳的图形化installer,只需10分钟左右就可以完成数据库集群的搭建。同时,为了降低初学者的学习曲线,YMatrix提供了on boarding功能,用户可以在3分钟内体验一个完整的IoT场景,包括数据写入和查询分析。
目前,YMatrix已经获得了从创业公司到大型企业的认可,其中有超过万亿市值的行业龙头企业,包括宁德时代、比亚迪等,以及世界500强企业,包括小米、三一重工等。
“后续,YMatrix会在已经存在海量需求的时序场景深耕,尝试替代传统数据库和专用类产品”,创始人姚延栋介绍,“数据量大、指标量多的车联网、智能制造、智慧能源、智慧城市、智慧园区、智慧医疗等场景会是重要方向。这些场景所产生的业务需求,将最大化体现超融合产品的价值”。
收看发布会完整回放视频请至“B站“ :bilibili.com/video/BV1b84y1B7ys
关于四维纵横
北京四维纵横数据技术有限公司(YMatrix) 成立于 2020 年 8 月,是一家创新型基础软 件公司,致力于物联网时代新一代数据基础设施软件的研发,并提供相关产品、解决方案及一站式商业服务。
公司创立伊始即获得中科院系、清华系和民营头部投资机构的投资,在政府政策和投资资 金的大力支持下,公司迅速进入发展快车道。截止目前,公司已完成 4 轮融资,总计规 模超亿元人民币,主要投资人包括晨山资本、顺义产业基金、东方富海、某头部云厂商等 多家国内知名机构。
公司位于北京市中关村科创园,是国家高新及中关村高新技术企业,曾获得多项政府科创扶持基金支 持,并曾荣获 2021 HICOOL 全球创业大赛三等奖、 2021 中关村创业之星等多项荣 誉。
关于YMatrix 超融合数据库
四维纵横团队在业界率先提出超融合数据库理念,并发布了 YMatrix 超融合数据库,基于独创的多微内核开放架构,在单一数据库之上,实现多模态数据的融通管理,及全场景 查询分析的统一支持;同时,YMatrix 兼顾高性能、高可靠及易用性,并大幅降低了数据 基础设施的建设复杂度,为构建物联网时代的融合数据基座,开拓一种全新的技术路径。
YMatrix 内置 4 种高性能微内核数据引擎,支持包括关系数据、时序数据、GIS 数据、 JSON 数据、文本数据、图片等多类型数据的融通管理;全面支持 SQL 1992-2016 标 准,同时支持多种场景下的复杂查询分析,包括高并发低延迟的增删改查、点查、明细查 询、聚合查询、窗口查询、关联查询、多维查询、复杂 OLAP 查询等;支持库内机器学习(In-database machine learning)和 AI,可实现库内高性能模型训练和推理计算等。
YMatrix 在多项性能测试中均展现出强大的性能表现:基于 TPC- B 基准的并发查询 TPS 最高可达 163 万, 时序数据写入性能可达 1.5 亿点/秒。同时,YMatrix 是目前唯一通 过中国信通院 “分布式分析型数据库”及“时序数据库”双认证的数据库产品。
发布仅两年,YMatrix 超融合数据库已经赢得包括宁德时代、三一重工、比亚迪、理想汽 车、小米等多家行业领军企业的信赖,成功实现商业化落地,被应用于工厂数据基座、大 型公司集团数仓、智能网联汽车、物联设备智能运营等真实生产场景中。
YMatrix 以极高的性能、稳定性、数据安全性,以及融合极简的技术架构,助力用户轻松 应对数据管理挑战,大幅降低选型、采购、使用及运维时的技术门槛,使开发更省力、迭代更省时、运维更省心。
