过去几年来,RAID 6 不断推广,已成为购买 RAID 控制器时必须考虑的一项特性。本文将探讨人们对该技术兴趣不断提高背后的一些原因,说明有的原因是合理的,而有的则是盲信,并将给出具体模型与实施实例,分别说明其优缺点,为分析问题、明确解决方案奠定坚实的基础。
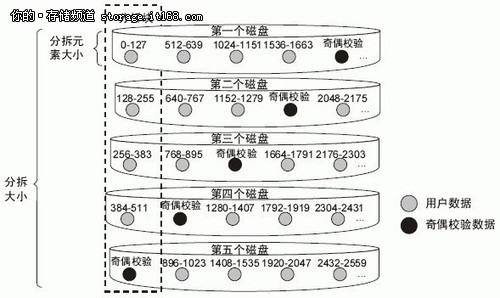
从最基本的角度来说,RAID 就是指一组磁盘关联和相对应的数据布局,在某些组件发生读取错误的情况下仍能确保从系统检索到数据。RAID 0 是基础条带化模型,不支持任何冗余,因此可最优化系统性能,但在数据故障情况下不能恢复数据。RAID 5 设计旨在从单次数据故障中恢复数据,通过添加一个冗余校验盘(“P”盘即奇偶校验盘),作为对等数据 XOR 计算,从而实现数据恢复功能。从数学角度来说,我们把数据恢复可看作只有一个未知变量(也就是因读取故障丢失的数据)的线性方程式,并能通过基础代数方法轻松解出任何线性方程。

Luca Bert 绝对的RAID专家
RAID 6 扩展了 RAID 5 的功能,可在同一数据集上恢复两个数据错误。从数学角度来说,RAID 5 使用一个方程式解出一个未知变量,而 RAID 6 则能通过两个独立的线性方程构成方程组,从而恢复两个未知数据。第一个方程与 RAID 5 机制一样,也是通过添加P盘实现的,而第二个方程则有所不同,将创建一个 Q 盘,因此 RAID 6 又称作“P+Q”盘机制。
从理论上说,这种回归计算可以无限延伸,可创建任意类型的 M+N 冗余,但实际应用通常仅限于 N=2,也就是说数据条带上同时发生两个不同的故障,这也就是RAID 6 所要解决的主要问题。
为什么需要 RAID 6?
RAID 5可独立解决磁盘不能检索数据的两种情况:
• 一个磁盘损坏,也就是说不能对任何读写命令做出响应,需要更换。RAID 5 能从保存的对等数据中恢复所有数据,重建缺陷磁盘。
• 磁盘组本身没问题,但其中一个磁盘上出现了坏块(即不能读取的块),造成某些数据不能恢复。
请注意,从数学角度说,每个磁盘的平均无故障时间 (MTBF) 大约为 50 万至 150 万小时(也就是每 50~150 年发生一次硬盘损坏)。实际往往不能达到这种理想的情况,在大多数散热和机械条件下,都会造成硬盘正常工作的时间大幅减少。考虑到每个磁盘的寿命不同,阵列中的任何磁盘都可能出现问题,从统计学角度说,阵列中 N 个磁盘发生故障的机率比单个磁盘发生故障的机率要大 N 倍。结合上述因素,如果阵列中的磁盘数量合理,且这些磁盘的平均无故障时间 (MTBF) 较短,那么在磁盘阵列的预期使用寿命过程中,就很有可能发生磁盘故障(比方说每几个月或每隔几年就会发生一次故障)。
两块磁盘同时损坏的几率有多大呢(“同时”就是指一块磁盘尚未完全修复时另一块磁盘也坏掉了)?如果说 RAID 5 阵列的MTBF相当于MTBF^2,那么这种几率为每隔1015个小时发生一次(也就是1万多年才出现一次),因此不管工作条件如何,发生这种情况的概率是极低的。从数学理论角度来说,是有这种概率,但在现实情况中我们并不用考虑这一问题。不过有时却是会发生两块磁盘同时损坏的情况,我们不能完全忽略这种可能性,实际两块磁盘同时损坏的原因与MTBF基本没有任何关系。
读取错误(不能恢复的ECC读取错误)从统计角度来说也比较少见,一般来说是指读取多少位后会出现一次读取错误。就 SCSI/ FC/ SAS 磁盘(SAS 是本文的重点,但同样的量化说明适用于所有这三种技术)来说,发生读取错误的几率为每读取10^15位(也就是约100TB)到10^16位(约 1000TB 或 1PB),会出现一次错误。我们把这一几率称作误码率 (BER)。
不过,SATA 磁盘的错误率要大一些,其 BER 比其它类型的磁盘要高出一两个数量级(即其BER为每读取10^14到10^15位出现一次错误,或者说每读取10/100TB 出现一次错误,具体取决于磁盘设计)。如果 SATA 磁盘容量为1TB,完整读取磁盘十次,就会发现新的故障块(假定这里的 BER 为每读取10^14位出错一次)。存储相同数据的相应两个块同时出现问题几乎是不可能的,几率为每读取 10^30 位发生一次。
然而,如果一个问题由于 MTBF 引起,另一个问题由于读取错误引起,这样两个错误同时发生的几率有多大?假设我们有 10 个 SAS 磁盘组成的阵列,每个磁盘容量为 300GB,BER为每读取10^-15 位出错一次,那么我们在重建磁盘时发生读取错误的可能性有多大?
计算方法如下: 10^15(位)X 1/8 (字节/位)X 1/10 (磁盘)X 1/300GB,从而得到每 50 次重建就会出现一次。这种几率还是比较大的,但并不足以让人震惊,要是磁盘阵列在使用寿命中要发生50次故障的话,那才真成了问题!不过,上述几率在统计学上还是有意义的,我们可以换一种方式来理解,也就是说,如果我们出售50款与上述配置一样的阵列,那么至少其中一个会出现上述严重问题。这种几率也不算高,但要是客户安装上百个阵列的话,问题就比较严重了。不过,有的SAS磁盘的BER比我们这里假定的情况要好上10倍,因此问题可以大大化解。
如果使用 SATA 会有什么情况呢?磁盘容量越大,问题就越严重!
磁盘的BER会较差,造成问题的严重性。假定同样有上述10个磁盘组成阵列,但每个磁盘容量为500GB,BER为读取10^-14位出错一次,那么计算如下:10^14 X 1/8 X 1/10 X 1/500GB,得出每 2.5 次重建就会出一次严重问题,这就要引起我们的高度重视了。我们这里所谈的是5TB容量的阵列,尽管这种阵列还不太常见,但完全是当前技术可以达到的水平。这就是说,这种容量大小的阵列每 2.5 个中,就有一个阵列会出现每次重建就发生块损坏的问题,用户会看到“Read Error at LBA = 0xF43E1AC9”这类报错信息,着实让人头痛。用户怎么会明白0xF43E1AC9 到底指什么?是说空间为空?还是说内核数据下次重启会发生蓝屏错误?是仅涉及没人会用得到的数据库?还是包含着银行帐户信息?实际上看到这种错误信息我们根本无所做出判断,唯一的办法就是从备份中恢复数据,这会花大量时间,而且还要考虑到从 5TB 容量的磁带中恢复数据会面临多大的读取错误几率。这种读取错误的几率要大大高于磁盘,因此用户会遇到无穷尽的问题。
内容提要:RAID 6 之所以重要,不是因为它能恢复两个同时发生的磁盘故障,而是能用完好的对等磁盘恢复一个磁盘故障和一个读取错误。随着磁盘容量的上升,上述这种错误的发生几率也在增加。更为重要的是,低质量SATA磁盘使用比较多,造成这种几率又要提高10倍乃至百倍。
说到底,我们要在价格与风险之间进行权衡,SAS 和高端驱动器的平均无故障时间 (MTBF) 更长/BER 性能更高,因而出问题的可能性也就少得多(尽管不是不可能出问题),而低端SATA 有助于大幅节约购买设备的资本投入,却会面临较高的双重故障几率。在此情况下,RAID6 市场便应运而生。
需要指出的是,上述涉及的某些风险可通过其它技术加以规避减轻,如定期扫描磁盘以避免坏块的巡读 (Patrol Read),确保不会因为另一块磁盘的故障造成同一条带上的数据发生双重故障。就目前而言,RAID 6 似乎是针对 SATA 驱动器的更合适的解决方案,也是我们更加需要的解决方案。不过随着市场预期的发展,磁盘容量和阵列规模不断上升,这种技术在 SAS 磁盘领域的应用也可能颇有商机。