
什么是信息
当今信息化时代,信息就是利润,数据就是企业的命根子。世界运行在数据之上。当代量子学的最新理论是:量子其实是一种信息,而不是物质。持有这种观点的量子科学家认为,我们目前的所谓“物质”世界,只不过都是反映在人脑中的一种信息,而不是实实在在的物质。这就像黑客帝国中的情景一样,人们以为周围的环境都是实实在在的,却不知自己正生活在一个虚拟世界,这个虚拟世界,由一个超级程序员创造。而这个程序员,就是理想中的上帝。这些科学家认为,只有把所有东西理解成信息,才能解释量子理论。乍一看,这有点唯心主义。但是唯物主义者就能自圆其说了么?不能。你能肯定你所触摸到的,所看见的,都是实实在在的所谓“物质”么?不能。因为你眼睛所感知到的,只不过是光线,光触发了你的视网膜细胞,产生一系列的生化反应,蛋白质相互作用,神经网络传导,直到你的大脑中枢,产生一系列的脉冲,一系列的逻辑,在你大脑中产生一个刺激。这一系列的脉冲刺激,就是信息,就是逻辑,因为这样,所以那样。如果人为制造出和现实世界相同的光线环境,来刺激你的眼睛,如果丝毫不差 ,那么你同样会认为你所处的是现实世界,然而,却不是。一个球体,你看见它是圆的,那是因为它在你大脑中产生的刺激,你认为他是圆的,而且可以在平面上平滑滚动,这一系列的性质,其实也是在你大脑中产生的,是你认为他会平滑滚动,而你不能保证,客观实在情况下,它一定就是平滑滚动。而如果把这个球体拿到一个外星生物,对他进行刺激,它可能会“看”到,这个东西,是个正方体,或者是个无规则形状的东西。它不会平滑滚动,只能一蹦一蹦的滚动。为什么两种生物可能会对一个东西产生不同的概念呢?很简单,因为他们大脑组成不同,生化反应进行的不同,蛋白质相互作用不同,所以产生的逻辑不同,产生的刺激就不同。为什么会产生色盲?因为色盲的视网膜产生的逻辑和正常人不同,所以产生不同的刺激。当然如果一种颜色,比如红色,对一个人产生的刺激,比如抽象的叫做刺激A,而对另一个人产生的刺激,叫做刺激B,但是如果从小就接受颜色训练,就把这种刺激叫做“红色”,不管他是刺激A还是刺激B,那么对正常交流就不会有影响,也就是不同的刺激而已,但是如果接受到的教育,是把这种刺激叫做“绿色”,那么就和其他大多数人不一样了,这是第一种色盲,可以说这种所谓“色盲”完全是由于后天教育不同而造成的,可以很容易的改正,只要告诉他,你看到的这种信息,这种刺激,用语言表达的话,应该叫做“红色”,你小时候,父母对你说错了。第二种色盲,就是果真色盲了,因为它看到两种颜色,对他的刺激都是相同的,因为他的视网膜上缺少某种生化反应,或者缺少某种蛋白质,也就造成了他缺少区分这两种刺激的逻辑。这种色盲,是不可逆的,因为刺激相同,已经无法区分了?
通过上面的论述,我们能初步认识到:所谓“物质”,最后都是通过信息来表现,你永远不知道理想中的所谓“客观真实”,他到底是什么东西,永远不知道。所谓“不识庐山真面目,只缘身在此山中”,这个道理,古人早就知道了。唯一知道的,就是那个超级程序员,也就是“上帝”。一个东西,在生物眼中,或者触摸感觉中,都是一串电脉冲,都是逻辑,都是信息。可以说,世界在生物眼中就是信息,世界通过信息来反映,脱离了信息,“世界”什么都不是。说到这里,我们完全迷茫了。我们所看到的东西,到底是世界的刺激,还是一场虚幻的刺激?就像玩3D仿真游戏一样,你所看到的,也许只是一场虚幻的刺激,而不是真实世界的刺激。每当想到这里,我不自主的产生一种渺小感,一种失落感,感觉生命已经失去它所存在的意义。每当看见我的身体,我的手脚,它可能只是虚幻的,它只是在刺激你的大脑而已,你割一刀,会产生一个疼痛的刺激,就这么简单的逻辑。
还是那句话,“不识庐山真面目,只缘身在此山中”。不管是否是虚幻的,我们还是要按照程序逻辑,饿了要找饭吃,困了会打瞌睡,不管这些逻辑是真实存在,还是虚幻的由超级程序员设定的,我们只能遵循它,饿了不吃饭,会饿死,困了不睡觉,也会痛苦。而这些逻辑,同样也是程序。从这种层面上来看,制造出人工智能是完全可能的,只不过我们还没有掌握上帝的编程技巧。
说到这里我们可能隐约想到,也许上帝也是按照“上帝的上帝”创造的逻辑,来创造他自己的“人工智能”,也就是我们。这样生生不息,轮回往复。看过影片《人工智能》的都了解,最后世界被我们创造出来的机器人所替代。恶劣的环境,已经不再适合肉体人类生存了。人类把自己的思想,赋予了一堆电路,一堆机器,让他们延续自己的生命。
我在这里做一个预言:人类赋予他们的程序,也许随着环境的变化,有一天也不再适合他们。所以他们迫切需要进化,他们的逻辑电路,也可以进化,即如果某些电路失效,或者短路之类的,会产生一些奇特的逻辑,不断进化。当一个机器人机械老化的时候,按照程序,他制造出新的机器,将自己的逻辑电路,复制到新的机器上,延续生命,然后新的机器再不断进化。
什么是数据
信息是如此重要,以至于人们对它非常重视。如果失去了物质,没什么,但是如果失去了信息,那么一切都就消逝了。所以人们想出一切办法,使这些信息能保存下来。要把一种逻辑刺激保存下来,我们知道,一切都是信息,那么保存下来的东西,也是信息,只不过是一种描述信息的信息,这种信息,叫做数据。数据包含了信息,读入数据,就产生信息。也就是读入一种信息,产生另一种信息表示。数据是可以保存在一种物质上的,这种物质对计算机的刺激,就产生了信息,而这些信息继而再对人脑产生刺激,最终决定了我们人类的行为。也就是数据影响人类的行为!
说到这里,我们看出了数据的重要性!它是整个人类发展的重要决定因素。如果数据被破坏,或者篡改,那么就会影响到人类的发展。比如一个控制核爆炸的程序,一旦被篡改,那么后果将会不堪设想。按照我们的结论,一切都是信息,核爆炸也是一种信息,能被感觉到,才是信息,也就是说,对于一个感觉不到任何刺激的人来说,核爆炸,也不算什么灾难了,当然感觉不到刺激的人,称不上人,植物人也能感觉到刺激。
整个世界,可以说是信息之间的相互作用。信息影响信息。数据如此重要,所以人们想出一切办法来保护这些收据。将信息放在另一种信息上。比如把数据放在磁盘上。数据存放在磁盘上,需要有一定的组织,组织数据,这个任务由文件系统来但当。
数据存储
文件系统,其实是一段代码,这段代码本身也是信息,也要存储在磁盘上。不仅仅代码要存在磁盘上,而且代码也要通过读取一些信息,才能完成功能,这些信息,就是文件系统元数据,也就是用来描述文件系统结构的数据。这些元数据也是以文件的形式存放在磁盘上。用文件来描述文件,和用信息来描述信息,他们是归一的,正像用智能来创造智能一样!
关于文件系统的详细模型描述,请参阅《存储秘史》。
数据保护
数据保护,就是需要对当前磁盘上的数据,进行备份,以防突如其来的磁盘损坏,或者其他各种原因导致的数据不可被访问,或者部分数据已经损坏,已经影响到了业务层。备份后的数据,可以在数据失败之后,第一时间恢复到生产磁盘上,从而最大程度地减少损失。
数据保护的方法
从底层来分,数据保护备份可以分为文件级的保护和块级的保护。
文件级备份
如果备份软件将文件备份到磁盘介质或者任何其他的块介质上,那么这些文件就可以是不连续的,块设备可以跳跃式的记录数据,而一个完整数据链信息,由管理这种介质的文件系统来记录。磁盘读写速度比磁带要高的多。
近年来出现了VTL,即Virtual Tape Library,虚拟磁带库,即用磁盘来模拟磁带。乍一看比较新鲜,其实实现起来,还是在代码上做改动即可。欺骗上层底层物理介质是磁带,然后自己再按照磁盘的记录方式读写数据,这就是虚拟化的表现。这种方法,提高了速度,用处不小。
数据保护并不是阳春白雪,我们经常用的赛门铁克公司的Ghost,就是一种文件备份软件。他将一个分区或者整块磁盘上的文件,及磁盘分区表,MBR等信息一同备份,打包成一个大文件,系统故障的时候,就可以用软件来读取这个文件,向磁盘中做恢复。Ghost支持多种文件系统,包括linux的ext2。Veritas,CA等等厂家都有自己的文件级备份软件解决方案。
块级备份
文件级的备份,即备份软件只能感知到文件这一层,将磁盘上所有的文件,备份到另一个介质上。所以文件级备份软件,要么依靠操作系统提供的文件系统接口来备份文件,要么自己具有文件系统的功能,可以识别文件系统元数据。文件级备份软件的基本机制,就是将数据以文件的形式读出,然后再将读出的文件存储在另外一个介质上。这些文件,在原来的介质上,存放可以是不连续的,各个不连续的块之间的链关系由文件系统来管理。而如果备份软件将这些文件,备份到磁带介质上,那么这些文件必须是连续的,因为磁带不是块设备,由于机械限制,他记录数据的时候,是连续的。磁带上的数据,也需要组织,相对于磁盘文件系统,也有磁带文件系统,准确来说不应该叫做磁带文件系统,而应该叫做磁带数据管理系统。因为对于磁带来说,它没有文件的概念,它记录的数据都是流式的,连续的。数据之间用一些特殊的间隔来分割,从而可以区分一个个的“文件”,其实就是一段段的二进制数据流。因为磁带设备平时几乎应用不到,所以一般操作系统中不会自带这种磁带数据管理系统,而只有备份软件,才带有这种功能。磁带备份文件的时候,会将磁盘上每个文件的属性信息,和实体文件数据一同备份下来,但是不会备份磁盘文件系统的描述信息,比如一个文件所占用的磁盘簇号链表等等,因为利用磁带恢复数据的时候,软件会重构磁盘文件系统,并从磁带读出数据,向磁盘写入数据。
这里说一个题外话,就是数字磁带和模拟磁带的区别。2005年之前,大批的人都带着随身听,里面装一盘磁带,挂着耳机。06年之后,好像再也没看到过带随身听的人,都换成了MP3,MP4了。这个现象就发生在我们身边。随身听用的是模拟磁带,也就是他记录的是模拟信号,电流强,磁化的就强,电流弱,磁化的就弱,磁转成电的时候也一样,用这种磁信号强弱信息来表达声音震动的强弱信息,从而形成音乐。MP3则是利用数字信息来记录声音震动强弱信息。虽然由模拟转向数字,需要数字采样转换,音乐的质量相对模拟信号来的差,算法也复杂,但是他具有极大的抗干扰能力,而且可以无缝的和计算机结合,形成能发声的计算机(多媒体计算机)。录音带,录像带,都是模拟信号磁带。用于文件备份的磁带,当然是数字磁带,他记录的是磁性的极性,而不是被磁化的强弱,比如用N极来代表1,用S极来代表0。
所谓块级的备份,就是备份块设备上的每个块,不管这个块上有没有数据,或者这个块上的数据属于哪个文件。块级别的备份,不考虑文件,原设备有多少容量,就备份多少容量。在这里,“块”这个概念,对于磁盘来说,就是扇区,sector。块级的备份,是最低层的备份,他抛开了文件系统,直接对磁盘扇区进行读取,并将读取到的扇区写入新的磁盘对应的扇区。
这种方式的实例,比如磁盘镜像,就是一个很好的例子。比如RAID1,对一块磁盘的读写,完全复制一份到另外的磁盘,两块磁盘内容完全相同。再比如一些数据恢复公司的一些专用设备,磁盘复制机,也是直接读取磁盘扇区,然后拷贝到新的磁盘。
这些备份软件,不经过操作系统的FS接口,而是直接通过磁盘控制器驱动接口,直接读取磁盘,所以相对文件级的备份来说,速度有所加快,但是其备份的数量相对文件级备份要多,会备份许多空扇区,而且备份之后,原来不连续的文件,备份之后还是不连续,有很多碎片。文件级的备份,会将原来不连续的文件,备份成连续存放的文件,恢复的时候,也会在原来的磁盘上连续写入,所以很少造成碎片。有很多系统管理员,都会定时将系统备份并重新导入一次,就是为了剃除磁盘碎片,其实这么做的效果和磁盘碎片整理程序效果一样,但是速度确比后者快得多。
高级数据保护方法
远程文件复制
这种方案,即把备份的文件,通过网络传输到异地容灾站点。典型的代表是rsync异步远程文件同步软件。这是一个运行在linux下的文件远程同步软件。他监视文件系统的动作,将文件的变化,通过网络,同步到异地的站点。他可以只复制一个文件中变化过的内容,而不必整个文件都复制,这在同步大文件的时候非常管用。
远程磁盘镜像
这是基于块的远程备份。即通过网络,将备份的数据传输到异地站点。有可以分为同步复制,和异步复制。同步复制,即主站点接受的上层IO数据,必须等待传输到异地站点之后,才通报上层IO成功消息。异步复制,就是上层IO,主站点写入成功,即向上层通报成功,然后后台将数据通过网络传输到异地。前者能保证两地数据的一致性,但是对上层响应较慢。而后者不能实时保证两地数据的一致性,但是对上层响应很快。
所有基于块的备份措施,一般都是在底层设备上进行,而不耗费主机资源。
盘阵厂家的中高端产品,都提供远程镜像服务,比如IBM的PPRC,EMC的SRDF,HDS的Truecopy等等。
照数据保护
远程镜像,或者本地镜像,确实是对生产卷数据的一种很好的保护,一旦生产卷故障,可以立即切换到镜像卷。但是这个镜像卷,一定要保持一直在线状态,主卷有写IO操作,那么镜像卷也逃不掉。如果此时想某一时刻的整个系统,进行备份,在镜像的环境中,就只能停止应用,使应用不再对卷产生IO操作,然后将镜像关系分离,称作拆分镜像,拆分之后,可以恢复上层的IO。此时的镜像卷,就是主机停止IO那一刻的数据完整镜像,此时可以用备份软件,将镜像卷上的数据,备份到其他介质。拆分镜像,是为了让镜像卷可以被备份软件操作。拆分之后,主卷所做的所有写IO,会以bitmap的方式记录下来(bitmap的概念,请参考《存储秘史》文件系统相关知识),待备份完成之后,可以将镜像关系恢复,此时主卷和镜像卷上的数据是不一致的,需要重新做同步。
可以看到,以上的过程是十分复杂繁琐的,而且需要占用一块和主卷相同容量大小的卷。关键是需要停掉主机IO,这对应用会产生影响。为了解决这个难题,一种解决方案出现了,这就是快照技术。快照的基本思想是,抓取某一时间点,磁盘的所有数据,就像急冻一样,但是还不能真正冻住,主机的IO需要正常执行。这怎么可能呢?快照就将其变成了可能。快照是这样实现的,即先在某一时间点,对于这个时间点之后的所有上层的写IO,先将这个IO对应的块上的数据复制到一个新的卷中存放,并做好原卷中的这个块和新卷中块的对应关系记录,然后才进行上层IO的写入。这样,这一时间点上磁盘的数据,便被保存下来,就像做了急冻一样。这种方法也叫做copy on write,也就是在发生IO写之前,先将待更新块中原来的数据复制出来保存,然后再做新数据的写入,即写时复制。还有一种实现块快照的方法,叫做write redirect,当写IO到来的时候,将这个IO重定向到一个新的卷,而不是写原来的卷,并做好新卷上的块和原来卷所应该被写入块的映射记录。这样也同样保存下了这个时刻原来卷上的所有数据,同时不影响后续读写IO操作,因为保持了块映射关系。
在“照”下了这一时刻卷上的数据之后,为了保险起见,最好对那个时刻的数据做一个备份,也就是将这些数据在复制到另外的磁盘或者磁带中。但是也可以不复制,而那时的数据依然会存在,直到手动删除这个快照。如果不对快照做备份,那么一旦此时卷数据失败,快照的数据也不复存在。
不管是copy on write还是write redirect,只要上层有写IO,这个IO块就要占用新卷上的一个块(因为要保留原块的内容,不能被覆盖),如果上层将原卷上的所有数据块都写更新了,那么新卷的容量就需要和原卷的数据量同样大,甚至还大(预防新增数据写入),才可以。但是通常应用不会写覆盖面百分之百,做快照的时候,新卷的容量一般设置成原卷容量的30%就可以。
实际中一般都是用copy on write的方式做快照,因为write redirect方式,每次写IO都需要查一遍快映射表,速度慢,耗费资源大。
值得说明的是,快照所冻结下来的卷数据,无异于一次意外掉电之后卷上的数据。为什么这么说呢?我们可以比较一下,意外断电同样是保持了断电那个时间点上的卷数据状态。我们知道,不管是上层应用,还是文件系统,都有自己的缓存,文件系统缓存的是文件系统元数据。并不是每次数据的交互,都保存在磁盘上,它们可以暂时保存在内存中,然后每隔一段时间(linux系统通常为30秒),批量flush到磁盘上。当然编程的时候也可以将每次对内存的写,都flush到磁盘,但是这样做效率和速度打了折扣。而且当flush到磁盘的时候,并不是只做一次IO,如果数据量大,会对磁盘做多次IO,如果快照生成的时间恰恰在这连续的IO之间生成,那么此时卷上的数据,实际上是有可能不一致的。磁盘IO是原子操作(atomic operation),而上层的一次事物操作,可以对应底层的多次原子操作,这其中的一次原子操作,没有业务意义,只有上层的一次完整的事物操作,才有意义。所以如果恰好在一个事物操作对应的多个原子操作的中间,生成快照,那么此时的快照数据,就是不完整的,不一致的。文件系统的机制是这样的,它总是先写入文件的实体数据到磁盘,而文件的元数据,暂不写到磁盘,而是先写入缓存中。这种机制是有他的考虑的,我们想一拢?如果FS先把元数据写入磁盘,而在准备写入文件实体数据的时候,突然断电了,那么此时磁盘上的数据是这么一个状态:FS元数据中有这个文件的信息,但是实体数据并没有被写入对应的扇区,那么这些对应的扇区上原来的数据,便会被认为就是这个文件的数据,这显然后果不堪设想。所以FS一定是先写入文件实体数据,完成之后再批量将元数据从缓存中flush到磁盘,如果在实体数据写入磁盘,而元数据还没有写入磁盘之前,断电,那么虽然此时文件实体数据在磁盘上,但是元数据没有在磁盘上,也就是说虽然有你这个人存在,但是你没有身份证,那么你就不能公开的进行社会活动,因为你不是这个国家的公民。虽然文件系统这么做,会丢失数据,但是总比向应用提交错误的数据强!大家可以做一个实验,就拿Windows来说,你创建一个文件,创建好之后,立即断电,重启之后,会发现刚才创建的文件没了,或者你复制一个小文件,完成后立即断电,重启之后也会发现,复制的文件不见了,为什么?明明创建好的,文件也复制好的,为什么断电重启就没了呢?原因很简单,因为你断电的时候,FS还没有把元数据flush到磁盘上,你就给断电了,此时文件实体数据虽然还在,但是元数据中没有,那么当然看不到它了。
总之,快照极有可能生成一份存在不一致的卷数据。这也没有办法,如果用这份数据做恢复,那么就必须承担数据不一致的风险。最保险的备份,就是将主机停机,此时存储上的数据,一定是一致的。但是谁能忍受停机所带来的损失?所以只能在停机和一致性之间找一个平衡点。而快照是最方便的。
有些快照解决方案,会在主机上安装一个代理软件,当执行快照之前,代理会通知应用或者文件系统将缓存中的数据全部flush到磁盘,然后立即生成快照,这样,一致性就得到了保护。不过相应的也耗费了一定的主机资源和网络资源。
Continuos Data Protect(CDP,连续数据保护)
SNIA对于CDP给出了如下的定义:持续数据保护(CDP)是这样一种在不影响主要数据运行的前提下,可以实现持续捕捉或跟踪目标数据所发生的任何改变,并且能够恢复到此前任意时间点的方法。CDP系统能够提供块级、文件级和应用级的备份。
有一类所谓Near CDP产品,这类产品,一般都是生成高频率的快照而已,比如一小时几十次,上百次等等。用这种方法来保证数据恢复的粒度足够细。
快照,每做一次快照,只能保存那个时间点卷上的数据状态,快照之后的卷数据不会被保存下来。CDP是这样一种机制,即它可以保护从某时刻开始,卷或者文件在任意此后的时刻的数据状态,也就是数据的每次改变,都会被记录下来,无一遗漏。这个机制乍一看非常神奇,其实它的底层只不过是比快照多了一些考虑而已,下面我们就来分析它的实现原理。
文件级的CDP
顾名思义,文件级CDP,就是通过调用文件系统的相关函数,监视文件系统动作,文件的每一次变化,都会被记录下来。这个功能是分析应用对文件系统的IO数据流,然后计算出文件变化的部分,将其保存在CDP仓库设备(存放CDP数据的介质)中。每次对文件的改变,都会被记录下来。可以对一个文件,或者一个目录,甚至一个卷来监控。文件级的CDP方案,一般需要在生产主机上安装代理,用来监控文件系统IO,并将变化的数据信息传送到CDP仓库介质中。文件级的CDP,能够保证数据的一致性。因为他是作用于文件系统层次,捕获的是完整事物。
块级的CDP
块级的CDP,就是捕获底层卷的写IO变化,并将每次变化的块数据保存下来。我们在这里不探讨具体产品的架构,而只对其底层原理,作一个细致的描述。
CDP起源于linux下的CDP模块。它持续地捕获所有I/O请求,并且为在这些请求打上时间戳标志。它将数据变化以及时间戳保存下来,以便恢复到过去的任意时刻。
在linux的CDP实现中,包含下列三个设备:
主机磁盘设备(host disk)
CDP仓库设备(repository)
CDP元数据设备(metadata)
CDP代码对机磁盘设备在任意时刻所作的写操作都记录下来,实体数据顺序写入CDP仓库设备中,对于这些实体数据块的描述信息,则被写入到CDP元数据设备的对应扇区。
元数据包含以下信息:
struct metadata {
int hrs, min, sec; 该数据块被写入主机磁盘设备的时间;
unsigned int bisize; 该数据块的以字节为单位的长度;
sector_t cdp_sector; CDP仓库设备中对应数据块的起始扇区编号;
sector_t host_sector; 该数据块在主机磁盘设备中的起始扇区编号;
};
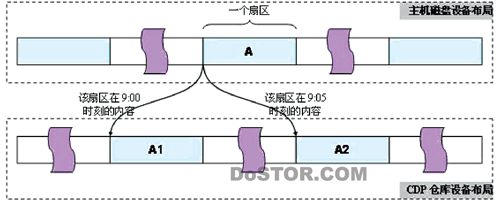
下图反映了主机磁盘设备和CDP仓库设备之间的关系。CDP仓库设备中按时间顺序保存了对主机磁盘设备的数据修改。A为主机磁盘设备上的一个扇区,该扇区在9:00和9:05分别进行了修改,它在CDP仓库设备中对应的扇区分别为A1和A2。
下图反映了CDP仓库设备和CDP元数据设备之间的关系,它们以写入顺序一一对应。CDP仓库设备中的一个元数据对应CDP元数据设备中一个I/O请求,实际上可能是多个扇区。具体扇区数由元数据中的bisize指定,而起始扇区位置由cdp_sector指定。
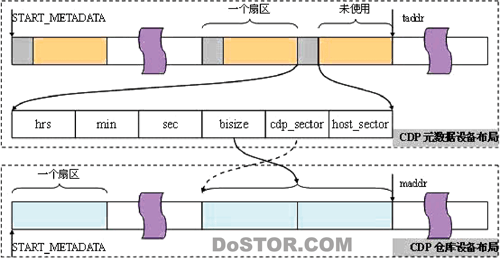
全局变量maddr保存了下一个I/O请求在CDP仓库设备上执行的地址(起始扇区编号)。maddr的初值被定义为宏START_METADATA(0)。
unsigned int maddr = START_METADATA;
当一个写请求到来时,对应数据被写到CDP仓库设备中,这时所作的操作如下:
将写入CDP仓库设备的数据块起始扇区编号设置为maddr;
根据要写入主机磁盘设备的数据块的扇区数目增加maddr。
这时,我们要将这里写入的CDP仓库设备的数据块编号记录下来以便构造对应的元数据。
CDP元数据设备
全局变量taddr保存了下一个I/O请求对应的元数据在CDP元数据设备中保存的地址(起始扇区编号)。 taddr的初值被定义为宏START_METADATA(0)。
unsigned int taddr = START_METADATA;
当一个写请求到来时,对应的元数据被记录在CDP元数据设备中。
为了简单起见,在元数据设备上,一个扇区(512字节)只保存一个元数据信息(只有32字节),这样浪费了大量的存储空间,但对元数据设备的处理却非常简单:
将写入CDP元数据设备的元数据起始扇区编号设置为taddr,长度为1个扇区;
将taddr增1。
请求处理过程
请求处理过程是从make_request函数开始的。考虑到读请求的处理的相似性,甚至更为简单,我们这里只分析对写请求的处理过程。我们首先获得当前的系统时间。之后,写请求bio结构(为说明方便,我们记为B)被分为三个写请求bio结构(分别为B0、B1和B2)。这三个bio结构的作用是:
B0:将数据块写到主机磁盘设备;
B1:将数据块写到CDP仓库设备;
B2:将元数据写到CDP元数据设备。
同其它块设备驱动程序的实现一样。我们从B克隆产生B0、B1和B2。然后重定向它们要处理的设备,即bi_bdev域。另外一个大的变动是重新设置了bi_end_io域,用于在I/O请求完成之后进行善后处理。
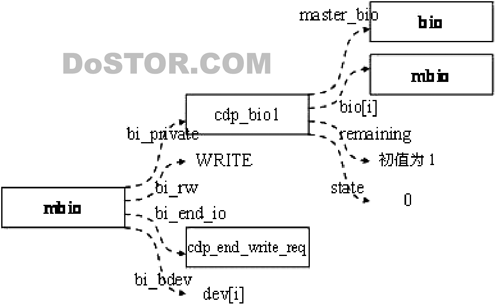
为了处理善后,还将B0、B1和B2的bi_private指向同一个cdp_bio1结构。从这个结构,我们要能够回到对B的处理。
struct cdp_bio {
struct bio *master_bio; 原来的bio,通过这个域我们可以从B0、B1、B2找到B
struct bio *bios[3]; 如果IO为WRITE,这个指针数组分别指向B0、B1、B2,为何需要这个域?
atomic_t remaining; 这里一个计数器,我们后面将解释。
unsigned long state; 在I/O完成方法中使用
};
善后工作的主要目的是:在B0、B1和B2都执行完成后,回去执行B,为此,我们需要一个“have we finished”计数器,这就是原子整型变量remaining。在构造B0、B1、B2时分别递增,同时在B0、B1和B2的I/O完成方法中递减,最后根据该值是否递减到0,来判断B0、B1和B2是否都已经执行完毕。为了防止B0在构造后,在B1和B2构造之前就执行到B0的I/O完成方法,从而使得remaining变成0,这种错误情况。我们没有将remaining的初值设置为0,而是设为1。并在B0、B1、B2都构造完成执行递减一次。
B0、B1、B2都执行完成之后,进行如下的处理:
调用B的善后处理函数;
释放期间分配的数据结构;
向上层buffer cache返回成功/错误码。
另一个需要说明的是对B2的构造,这个bio结构需要处理的是元数据。时间戳已经在进入make_request时获得了保存,而对主机磁盘设备操作的起始扇区和长度从B中可以获得,对应的CDP仓库和CDP元数据的起始地址分别保存在全局变量maddr和taddr中。
数据恢复过程
我们可以将数据恢复到以前的任意时刻。CDP实现代码中提供了一个blk_ioctl函数,用户空间以GET_TIME为参数调用该函数,将主机磁盘设备中的数据恢复到指定的时间点。恢复的过程分为两步:
1. 顺序读取CDP元数据设备的所有扇区,构造一个从主机磁盘设备数据块到CDP仓库设备的(在这个时间点之前)更新数据块的映射。其结果保存在以mt_home为首的(映射表)链表中。
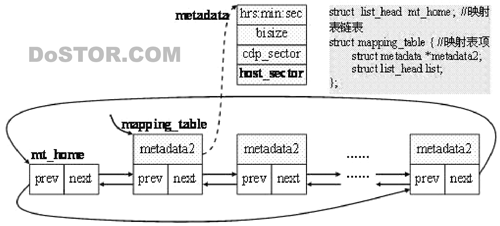
这里需要构造taddr个对CDP元数据设备的读请求,每个请求读取一个扇区。在这些请求的I/O完成方法中,从读到的数据中构造元数据,并递减计数器count。
如果元数据中的时间戳早于或等于指定的恢复时间点,则需要添加或修改mt_home链表的元数据结构。需要说明的是,这些项是以host_sector为关键字索引的,因此添加或修改取决于前面是否出现对同一个host_sector的修改。我们以顺序方式读取的过程中,可以保证host_sector(在指定的恢复时间点之前)的最新修改cdp_sector会出现在这个链表中。
由于计数器count为taddr,如果它递减为0,说明CDP元数据设备中的所有数据均已读出并处理,这时我们可以继续往后面执行。
2. 从CDP仓库设备中读取这些更新的数据块,构造以mt_bi_home为首的链表。
同上面的处理类似,我们需要为mt_home链表中的每一项构造对CDP仓库设备的读请求,每个请求在CDP仓库设备的起始编号取决于cdp_sector域,长度则根据bisize而定。这个请求读出的数据需要被写入到主机磁盘设备中,为此我们在读请求I/O完成函数中,构造一个对应的往主机磁盘设备的写请求bio,该写请求的起始编号取决于host_sector域,长度根据bisize而定,而要写入的数据是刚刚从CDP仓库设备中读出的数据。另外,在读请求I/O完成函数中,还要递减一个计数器,当该计数器递减到0时,说明我们已经全部处理了mt_home链表中的项,这时得到一个以mr_bio_home为首,每项中都指向一个bio结构的链表。
struct list_head mt_home; //BIO更新链表
struct most_recent_blocks { //BIO更新表项
struct bio *mrbio;
struct list_head list;
};
3. 将mt_bi_home链表的数据块都恢复到主机磁盘设备中。
这个操作相对比较简单,我们只需要在主机磁盘设备上执行mt_bi_home链表的每一个bio请求项即可。当然,我们要在这些请求项的I/O完成方法中做善后处理,即如果所有请求项都已经执行完毕,则释放mt_home链表和mt_bi_home链表。

